Hi,
I am trying to set the num_workers=0 before calling get_preds() but it turned out that it is not setting it correctly. See the code snippet below:
tta_res=[]
prs_items=[]
for learn in self.ensem_learner:
print(type(learn.dls))
learn.dls.bs=1
print(f'num_workers before the chage are: {learn.dls.num_workers}')
learn.dls.num_workers=0
print(f'num_workers after the change are: {learn.dls.num_workers}')
tta_res.append(learn.get_preds(dl=learn.dls.test_dl(fs)))
if len(prs_items)<1:
prs_items=learn.dl.items
if not self.cpu:
gc.collect()
torch.cuda.empty_cache()
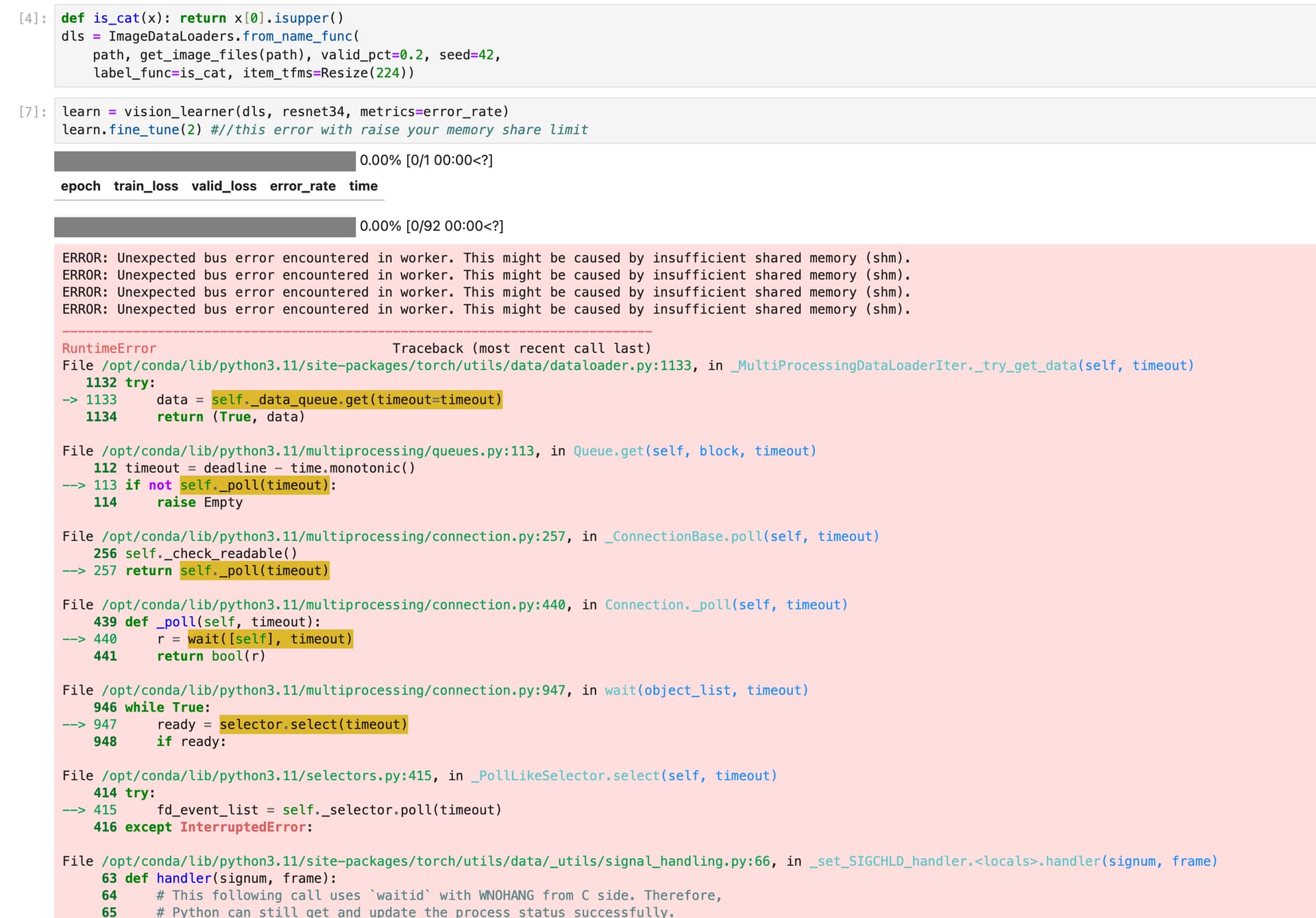
While the code prints num_workers are 0, I think it’s not catching the settings because the error below refers to workers where there shouldn’t be any.
-Tools presence detection task started.
<class 'fastai.data.core.DataLoaders'>
num_workers before the chage are: 1
num_workers after the change are: 0
ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm).
ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm).
ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm).
ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm).
ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm).
ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm).
ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm).
ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm).
ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm).
Traceback (most recent call last):
File "/opt/conda/lib/python3.10/runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/opt/conda/lib/python3.10/runpy.py", line 86, in _run_code
exec(code, run_globals)
File "/opt/algorithm/process.py", line 258, in <module>
Surgtoolloc_det().process()
File "/home/algorithm/.local/lib/python3.10/site-packages/evalutils/evalutils.py", line 183, in process
self.process_cases()
File "/home/algorithm/.local/lib/python3.10/site-packages/evalutils/evalutils.py", line 191, in process_cases
self._case_results.append(self.process_case(idx=idx, case=case))
File "/opt/algorithm/process.py", line 157, in process_case
scored_candidates = self.predict(case['path']) #video file > load evalutils.py
File "/opt/algorithm/process.py", line 210, in predict
tta_res.append(learn.get_preds(dl=learn.dls.test_dl(fs)))
File "/opt/conda/lib/python3.10/site-packages/fastai/learner.py", line 290, in get_preds
self._do_epoch_validate(dl=dl)
File "/opt/conda/lib/python3.10/site-packages/fastai/learner.py", line 236, in _do_epoch_validate
with torch.no_grad(): self._with_events(self.all_batches, 'validate', CancelValidException)
File "/opt/conda/lib/python3.10/site-packages/fastai/learner.py", line 193, in _with_events
try: self(f'before_{event_type}'); f()
File "/opt/conda/lib/python3.10/site-packages/fastai/learner.py", line 199, in all_batches
for o in enumerate(self.dl): self.one_batch(*o)
File "/opt/conda/lib/python3.10/site-packages/fastai/learner.py", line 227, in one_batch
self._with_events(self._do_one_batch, 'batch', CancelBatchException)
File "/opt/conda/lib/python3.10/site-packages/fastai/learner.py", line 193, in _with_events
try: self(f'before_{event_type}'); f()
File "/opt/conda/lib/python3.10/site-packages/fastai/learner.py", line 205, in _do_one_batch
self.pred = self.model(*self.xb)
File "/opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/lib/python3.10/site-packages/torch/nn/modules/container.py", line 141, in forward
input = module(input)
File "/opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/lib/python3.10/site-packages/fastai/vision/learner.py", line 177, in forward
def forward(self,x): return self.model.forward_features(x) if self.needs_pool else self.model(x)
File "/home/algorithm/.local/lib/python3.10/site-packages/timm/models/convnext.py", line 353, in forward_features
x = self.stages(x)
File "/opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/lib/python3.10/site-packages/torch/nn/modules/container.py", line 141, in forward
input = module(input)
File "/opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/home/algorithm/.local/lib/python3.10/site-packages/timm/models/convnext.py", line 210, in forward
x = self.blocks(x)
File "/opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/lib/python3.10/site-packages/torch/nn/modules/container.py", line 141, in forward
input = module(input)
File "/opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/home/algorithm/.local/lib/python3.10/site-packages/timm/models/convnext.py", line 148, in forward
x = self.mlp(x)
File "/opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/home/algorithm/.local/lib/python3.10/site-packages/timm/models/layers/mlp.py", line 31, in forward
x = self.drop2(x)
File "/opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1172, in __getattr__
def __getattr__(self, name: str) -> Union[Tensor, 'Module']:
File "/opt/conda/lib/python3.10/site-packages/torch/utils/data/_utils/signal_handling.py", line 66, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 479) is killed by signal: Bus error. It is possible that dataloader's workers are out of shared memory. Please try to raise your shared memory limit.
Do I need to iterate over the data loaders contained in ‘learn.dls’ and set num_workers for each since DataLoaders is a thin wrapper around multiple DataLoader instances?
I tried using learn.dls.test_dl.num_workers=0, but got an error stating that there is no such attribute in the test_dl.
AttributeError: 'method' object has no attribute 'num_workers'
Any ideas on how to set n_workers or num_workers zero for fastai learner at the inference stage?
Thanks in advance
Best regards
Bilal