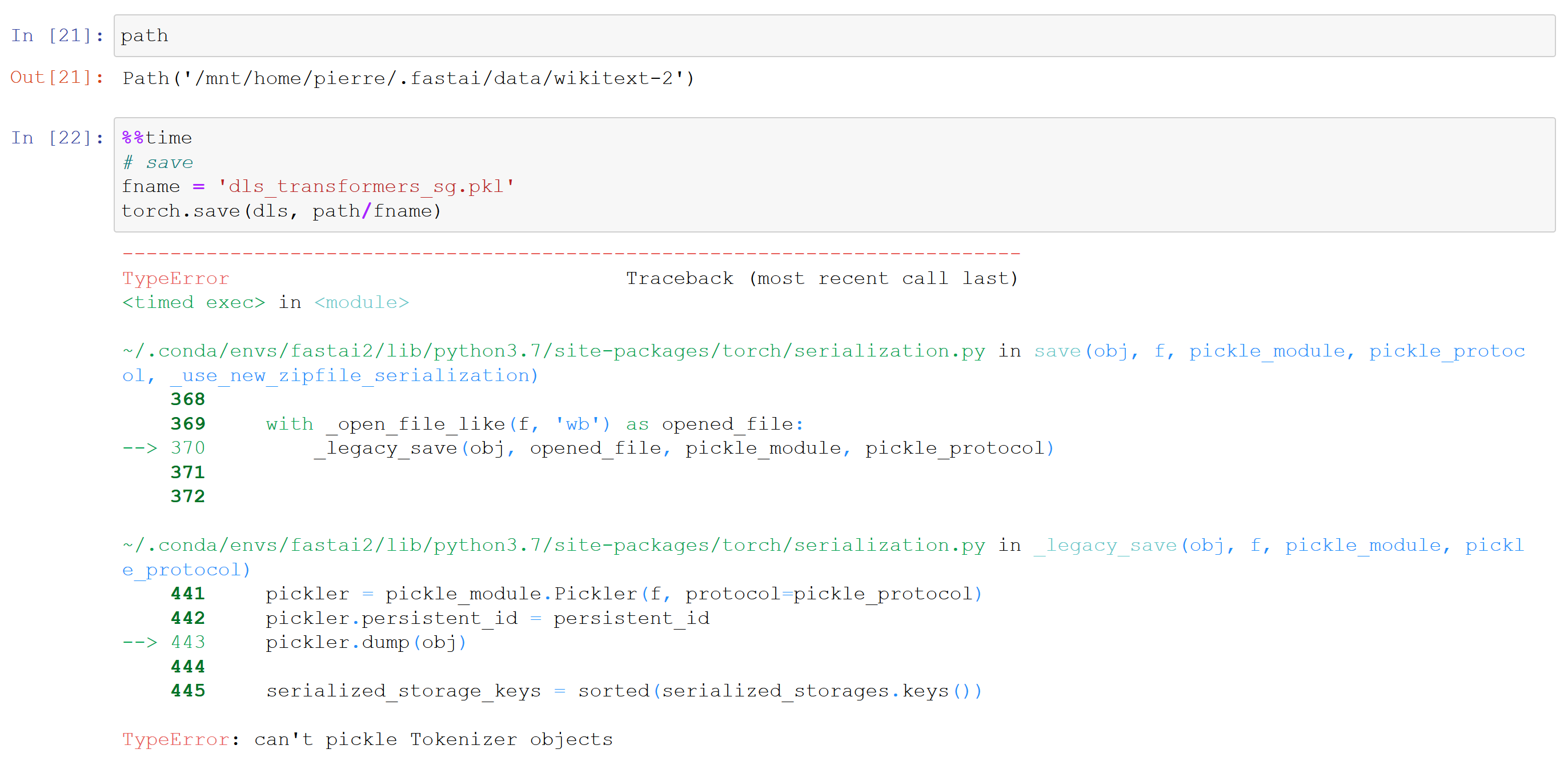
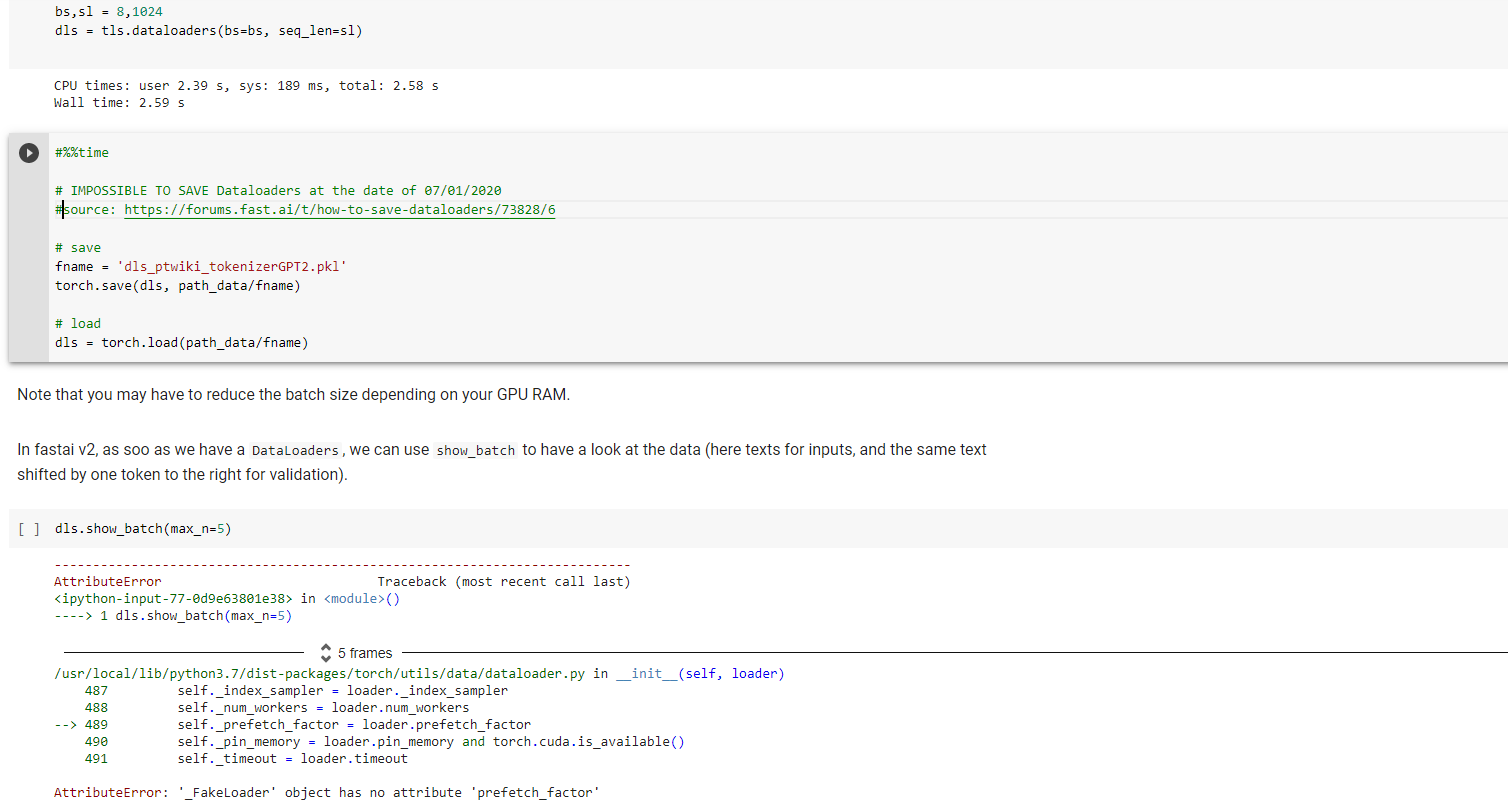
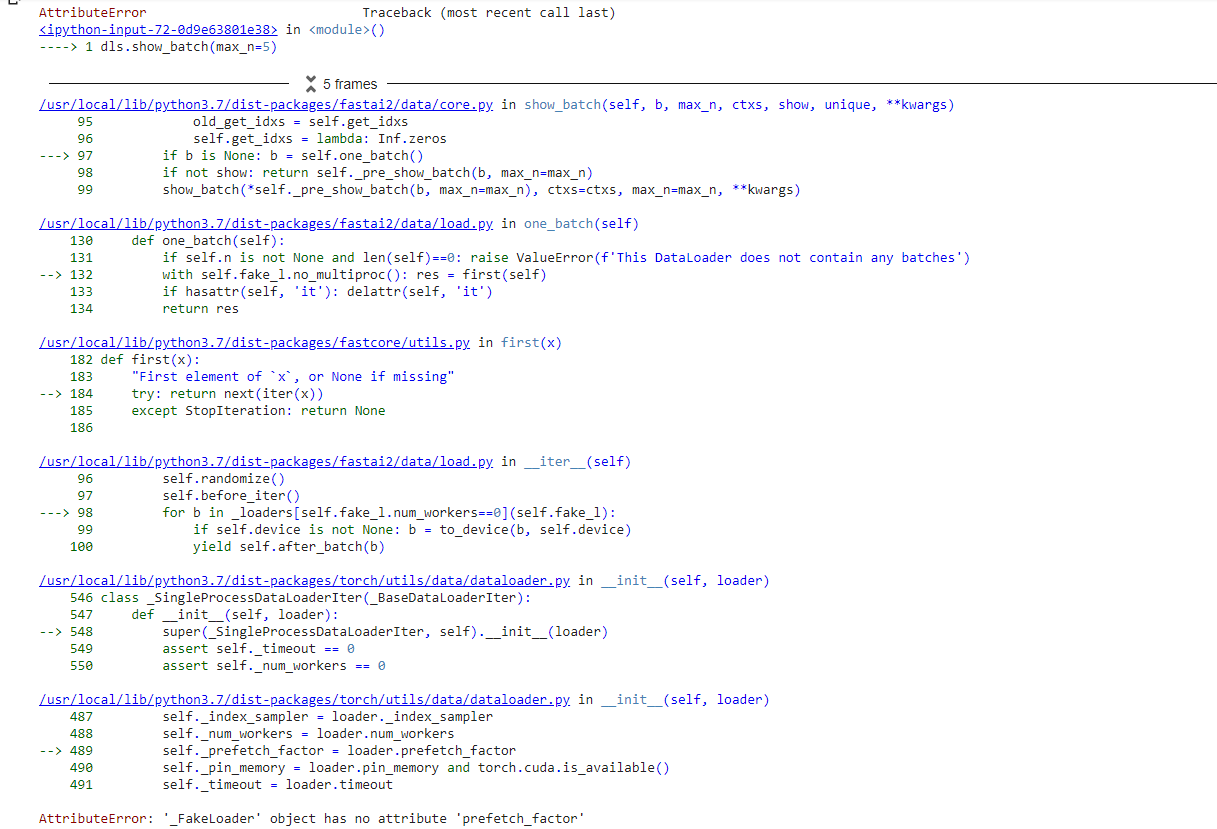
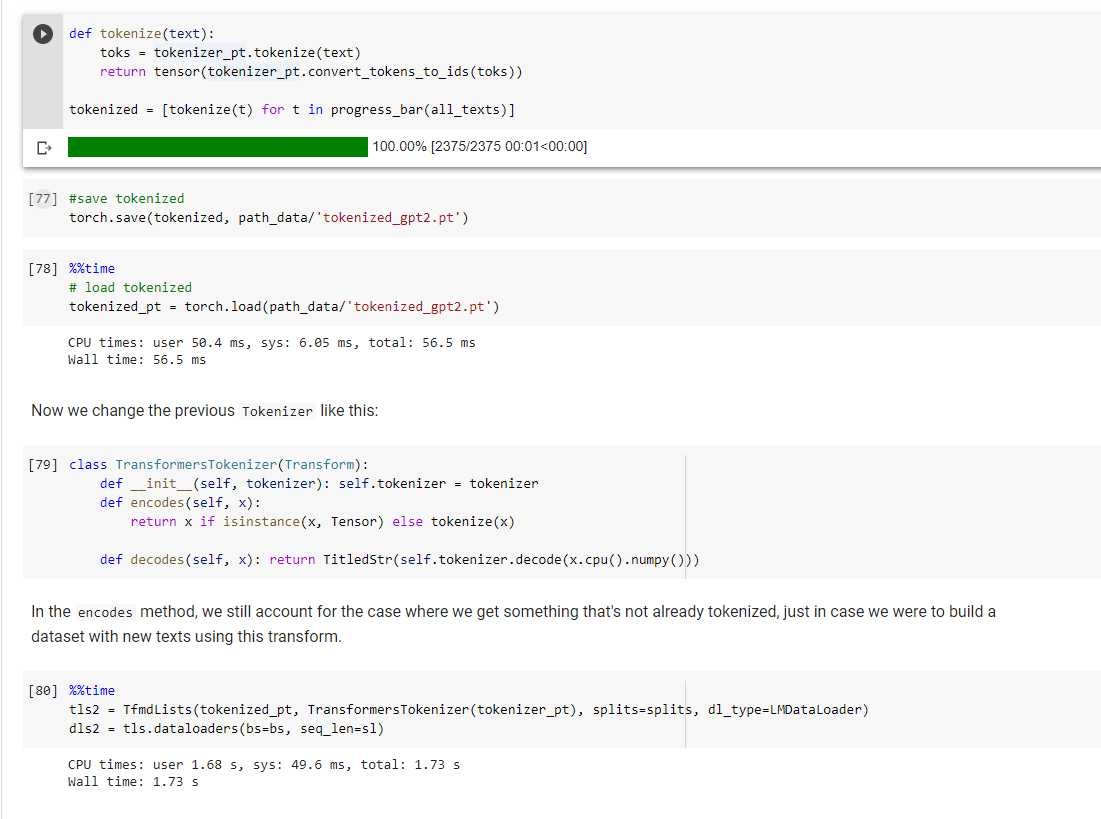
@muellerzr Question on the Dataloaders one thing that can be nice, but also is a pain is that I can only save the data loader with the data until I have a model I don’t have the ability to take the preprocessing steps from a recently saved TabularDataLoader. ( I think this is why I am asking  )
)
This might be a thing in the DataBlockAPI, but I am currently in a tabular project mode for work.
dl_test = dl_train.test_dl(X_test, with_label=False) # could be true doesn't matter
This is fine when you are going to train and do inference in the same place and have enough ram to hold both data sets. However when using a tabular learn I don’t believe the training data is available and as I write this maybe it is, but I don’t think so.
learn_inf = load_learner(os.path.join(model_path, yaml.get('process_name') + yaml.get('dl_model_suffix')),
cpu=True)
test_dl = learn_inf.dls.test_dl(df_test, with_label=False)
Even though the fastai model is a little bigger than a typical model like an xgb model that is completely okay for the functionality it gives me.
Do you know of a way when
dl_train = (TabularDataLoaders.from_df(df_transform, procs=procs,
cat_names=cat_vars, cont_names=cont_vars,
y_names=0, y_block=y_block,
valid_idx=splits[1], bs=bs))
if os.path.exists(p) is False:
os.makedirs(f'{p}')
logging.info(f'{fn} getting saved to {p}')
file_path = os.path.join(p, '' f"{process_name}_{fn}.pkl")
logging.info(f'file saved to {file_path}')
torch.save(dl, file_path)
Rather than save the entire dataset in the Dataloader is there way to pop out the data have that this be similar to a sklearn pipeline that is there to then use what’s above without the overhead of the memory and large object movement
 cc
cc