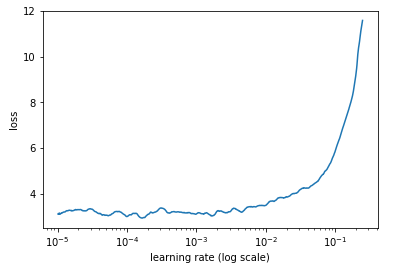
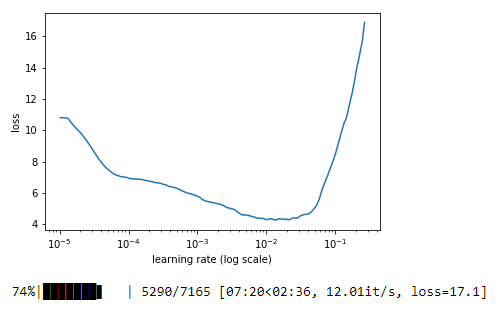
I am solving this problem using NLP notebook from Week 4. The dataset is considerably large. Currently I am using a p3.2x large instance. I have been running the notebook for something around 2 hours. I am doing the language modelling portion of the notebook.
My first iteration -
lr = 3e-3 learner.fit(lr, 3, wds=1e-6, cycle_len=1, cycle_mult=2)
[ 0. 4.01247 3.77574]
[ 1. 3.62427 3.37876]
[ 2. 3.54717 3.23648]
[ 3. 3.50206 3.26325]
[ 4. 3.40787 3.13808]
[ 5. 3.37264 3.04037]
[ 6. 3.34219 3.01174]
My second iteration –
lr = 3e-3 learner.fit(lr, 3, wds=1e-6, cycle_len=1, cycle_mult=2)
[0. 3.39474 3.01604] [1. 3.34584 3.07711] [2. 3.30852 2.96716] [3. 3.34519 3.10738] [4. 3.29975 3.01878]
I believe I am suffering from underfitting . One of the ways to improve underfitting is to increase number of hidden layers and another way might be to increase number of activations per layers. I am not sure.
Increasing size of embedding layer might allow to improve the contextual information of each of the word. Does it prevent underfitting?
I am not touching the dropout portion as for now, since I believe the only thing I can do is to dropout more nodes - which would decrease overfitting.
Any ideas for somebody who have tinkered with the parameters?