Hi Guys,
I’m working on a data set that utilizes log-in and transaction information from a eCommerce website to predict log-in risk (classification, 0/1).
The training data are transactions from 2015-01-01 to 2015-06-30, test data are from 2015-07-01 to 2015-07-31.
(competition link if you are interested: http://jddjr.joybuy.com/item/9)
This is a Kaggle-like competition, so I can see my score (fbeta with beta=0.1) on public leaderboard.
To estimate my model performance, I used two approaches, which gives very different results:
- 5-fold cross validation on entire training set
- Out-of-time validation using data form 2015-06-01 to 2015-06-30
For both approaches, I trained my submission model on full training set.
I trained a Random Forest with 500 trees, here the scores I got:
- avg. score of 5-fold cross-validation is 0.87
- score of OOT (June data) validation is 0.39
- score on test set (Public Leaderboard) is 0.66
After I saw the huge difference between 1 and 2, my first guess is data leakage happened somewhere. While I cannot rule out the possibility of data leakage, I checked the distribution of risk transactions over the time:
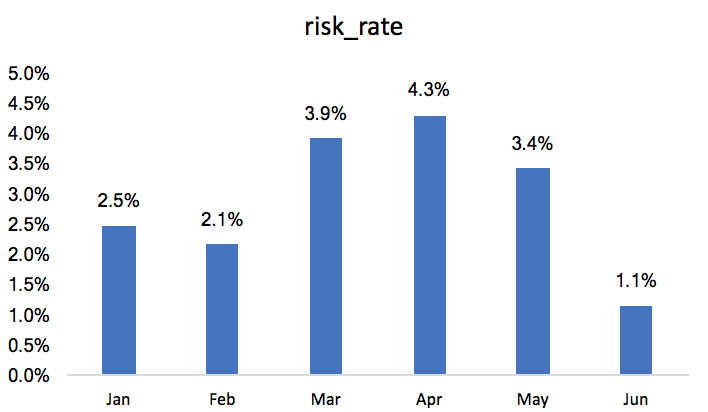
I saw the rate of risk transactions is much lower in June than the months before. I believe this explained why score on OOT set is so different from cross validation and test set.
My question is:
How can I know whether the difference between scores of OOT, CV versus test is due to the shifted distribution of target variable or something else?
How can I choose a validation set that I can rely on in this case?
Thanks!