I set up fastai to use my windows 10 laptop Nvidia GPU. While running some code, i found that kinda slow, so i am wondering whether the GPU is being used or not.
How can I know if the GPU is being used?
@nabil.affo A basic way to do is have Nvidia SMI installed if you are working with Linux.
nvidia-smi -q -g 0 -d UTILIZATION -l this command would help you to get your GPU utilization in terminal.
Another way to check it would be to import torch and then execute torch.cuda.device(0) this will show your GPU device id. You can also view device name by typing torch.cuda.get_device_name(0).
You can have a look here: Is my GPU being used & How to check your pytorch / keras is using the GPU?
2 Likes
Thanks… am using windows 10, what’s the alternative for nvidia-smi ?
I run the code and it detected my GPU.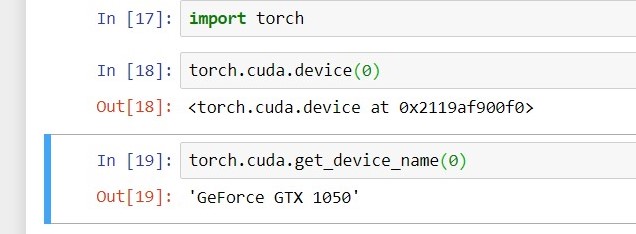 .
.
But fastai is definitely not using the GPU. The execution time should be less than 1 min (I presume) for every cycle but i have instead this…(if the GPU was used, the time should be less than that, right?)
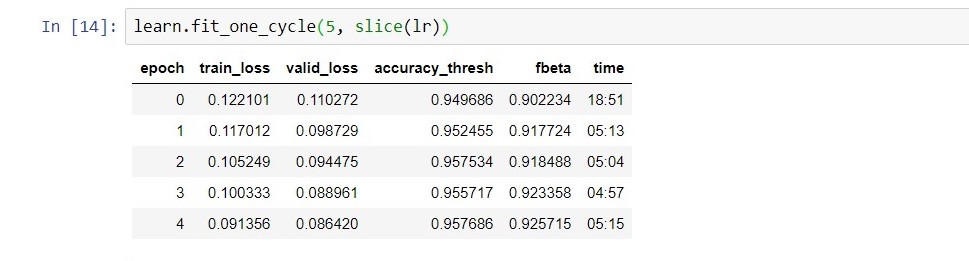
How can i make it use GPU(if of course it is true that it is not used)
4 Likes
Time depends on various factors: One of them would be your hardware and another would be your parameter tunning. For your case, I think its a hardware issue as DL mostly depends on GPU, CPU, memory, etc. If you have higher Batch size, it would require more GPU memory. [Edit: For more
Please refer this post]
For Windows, I am not sure which tool would be helpful to find GPU utilization. Try this one if it helps: https://www.thewindowsclub.com/monitor-gpu-usage-iusing-task-manager
1 Like
OK… Yeah. Seems right. My machine is an i5 and the GPU has only 4Gb of VRAM, while Colab (I was using this before) for instance provides better GPU parameters.
1 Like
Yep…
I had the same problem when running tabular models, with images it just works. I have the same GPU as you. But now It appear to be working. Try to force your model to gpu: learn.model = model.cuda().
The good GPU utilization tool is Nvidia Gpu Utilization tool (NvGpuUtilization). Also when using CPU, the progress bar does not seem to move, when using GPU the training is fluid.
4 Likes
GPU memory won’t actually affect speed unless you properly tune your batch size through the bs parameter of DataBunch. More GPU memory will let you set a higher batch size but won’t automatically speed things up.
You can just keep increasing the batch size until you get an error when you run out of memory or there is some stuff in fastai.utils.mem to monitor memory usage but I’m not sure how reliable it is and haven’t tried it on windows. But from my linux system, running a very small network (with a very large batch here to test) I get:
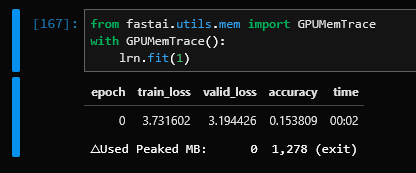
Not sure why the △Used is reporting 0, it should be the more accurate figure I gather, taking into account existing usage (though maybe that’s because it’s a linux box without anything else using the GPU). But the peak of 1,278Mb does seem correct and increased with increasing batch sizes.
4 Likes
@nabil.affo Please refer to @TomB answer. It is more accurate. Thanks!
thanks…
@TomB Now I did find this error
RuntimeError: CUDA out of memory. Tried to allocate 1024.00 KiB (GPU 0; 4.00 GiB total capacity; 2.95 GiB already allocated; 230.40 KiB free; 18.25 MiB cached)
and it doesn’t work. Actually i have 2 GPUs (Intel Graphics and Nvidia, GPU 0 seems to be Intel)
I tried to free the memory by running torch.cuda.empty_cache() but still there is the runtime error.
@nabil.affo You can simply restart your kernel to remove this error. Also try to reduce batch size.
1 Like
I haven’t used this stuff but from the looking at this documentation it looks like that function doesn’t actually free any memory, it just means that GPU memory that has been freed but not actually returned to the system is returned (normally it keeps the memory to more quickly be able to re-allocate it). You need to actually delete the objects using memory, e.g. by doing del some_gpu_tensor. As noted in that documentation ipyexperiments may help here. Or as Rishi said just restart the notebook kernel (though depending on notebook complexity this may not be a quick thing).
Based on the output you posted above, GPU 0 is the dedicated GTX 1050 as reported by torch.cuda.get_device_name. Though given that message I would guess that your GPU may currently be being used by other system processes (based on it only wanting to allocate 3Gb of RAM, reserving 1Gb for system usage). I think you would ideally switch your system to using the integrated graphics so that only fastai is using the dedicated GPU as otherwise things like browsers will take up your GPU memory. As it specifically requests which GPU to used pytorch shouldn’t be affected by system settings so switching the whole system to integrated graphics shouldn’t limit pytorch. The nvidia control panel should let you control which GPUs are used as in the instructions here. You may also be able to control how your dedicated graphics is used by playing around with power profiles, you may be able to have a profile that disables the dedicated GPU for most apps while not limiting CPU power and still allowing pytorch to specifically request and use the dedicated GPU. Then you can switch to this while using fastai but have things like browsers use the GPU and so perform better when not using this profile. It’s been awhile since I played with these settings though so unsure of how his currently works. But searching for stuff on dedicated/integrated graphics and power profiles might give some good pointers.
3 Likes
Just to add some more info, I stopped using the GTX1050 (I have the P1000 equivalent) and moved to colab, it is way faster. Anyway, I would like to understand why in windows sometimes fastai decides not to use the GPU.
yes torch.cuda.empty_cache() doesn’t free memory. instead, I used this function gpu_mem_get_free_no_cache(). I would run it before any big execution that would require much memory and i had to reduce the batch size as well.
yes, colab is faster… i was using colab, but somehow, some lines of codes wouldn’t work for me (I used windows)  . So i switched to my Nvidia GPU. Windows may not use GPU maybe because the GPU doesn’t not support cuda.
. So i switched to my Nvidia GPU. Windows may not use GPU maybe because the GPU doesn’t not support cuda.
All Nvidia GPUs support cuda, at least recent ones.
Use:
learn.model.cuda()
To force the model to use CUDA, it worked perfectly for me.
4 Likes
In order to load the model on a dedicated GPU:
fastai_learner = load_learner(self.model_directory + ‘/’ + Train.TRAINED_MODEL_FILE_NAME, cpu=True) #cpu=True, to avoid that we load it to GPU 0
self.fastai_learner.model.cuda(gpu_id) #Load it do the GPU definde by gpu_id