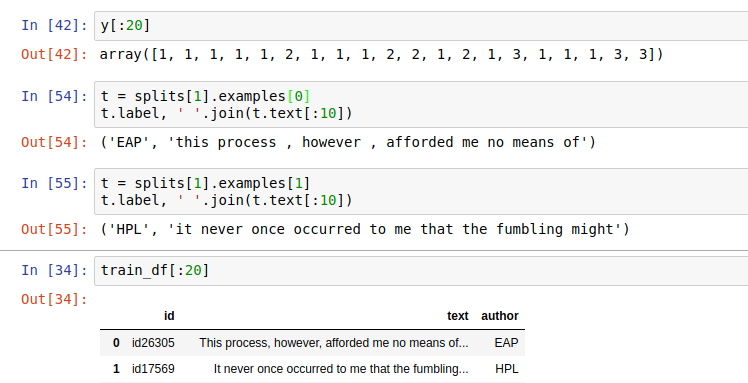
When I do a m3.predict_with_targs(), I get:
A few questions:
-
Why are there 3 columns when there are only two classes (pos and neg)?
-
How would I convert the numbers into probabilities?
When I do a m3.predict_with_targs(), I get:
A few questions:
Why are there 3 columns when there are only two classes (pos and neg)?
How would I convert the numbers into probabilities?
Me too! Help! =)
Also, it didn’t make predictions for the final batch … (note, these #s are from a different dataset, though I get the same thing with IMDB)
You need to run them through a softmax to get probabilities.
So when you sayrun them through a softmax, I’m taking that to mean you append a nn.LogSoftmax() to your model, correct?
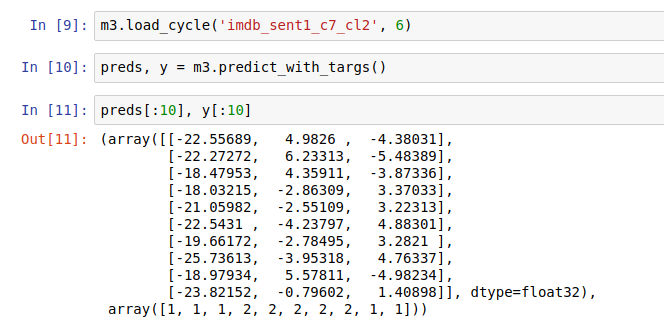
And what about the 3rd column? I know softmax will zero it out, but what is it and do we need to git rid of beforehand by running it through a Linear layer that converts the 3 activations to 2 before the softmax?
No need to change the model. Just:
pre_preds = m.predict()
preds = F.softmax(pre_preds)
Make sense?
Yah, that makes sense. I wasn’t aware of the ‘F’ class.
What about the additional output? What is it?
That’s an <unk> class that torchtext adds by default (see this thread). You can verify that by calling IMDB_LABEL.vocab.itos (it is inserted at the front).
I don’t think it really impacts the predictions. As you can see, the magnitudes of that first column are all very small and, when you convert them to probabilities, you can see they are all 0.
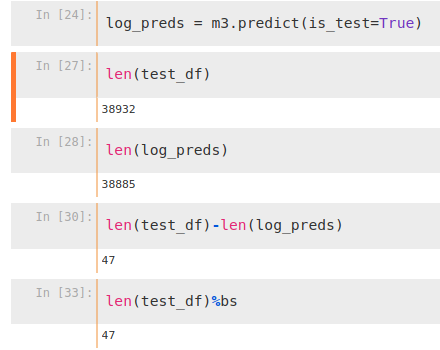
I found incomplete predictions too and I think it’s because of the rounding when splitting data into batches. My hacky solution is too append some redundant data at the end of the dataframe so that it won’t cut my real data.
Another thing I noticed is that there may be some shuffling involved in the batches and as a result the prediction output do not follow the original order. This is very annoying and my (another) hacky solution is to set the prediction batch size to 1 to preserve the original order.
Thank you for confirming I’m not the only one seeing those two issues!
I feel both of these should be handled by the library by default when predicting on test data.
I’m thinking the same because when I run
pre_preds, y = m3.predict_with_targs()
The y values do not match with my validation dataset order.
Hi @runze, how did you set the prediction batch size? predict() won’t take bs as a parameter and setting m.bs=1 didn’t work either
Do I need to recreate and load the model with new params?
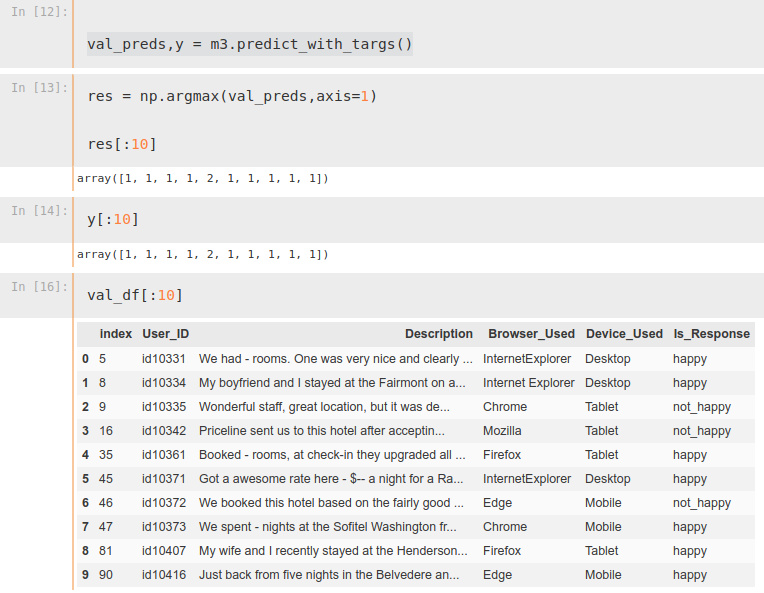
See below (looking at spooky comp.):
y is supposed to be the actual targets … but notice that the first two are both 1’s. And yet, when you look at the first 2 examples in my validation datasets (btw, I’m using my training as my validation dataset for testing), the actual classes cannot both me 1.
Hey, I didn’t change the model structure - I just modified this line when defining TextData.from_splits from
trn_iter,val_iter = torchtext.data.BucketIterator.splits(splits, batch_size=bs)
to
trn_iter, val_iter, test_iter = torchtext.data.BucketIterator.splits(splits, batch_sizes=(bs, bs, 1))
You can see from the source code here that torchtext.data.BucketIterator.splits actually takes in a batch_sizes tuple argument that defines batch sizes for different datasets.
Yes, if no shuffling is involved, torchtext sorts data by the word length of the text object (because we define sort_key as def sort_key(ex): return len(ex.text), as in cell 115 of this notebook), and in the case of ties, it breaks them by preserving the original order. So I would sort my data by those two factors too. It does that because it tries to group texts with similar lengths together in a batch to feed into the model.
Oh sweet! Yeah I had also modified the source to return an additional iterator for test, otherwise it would break.
We should create a PR for these changes, you think?
Yup. I was just looking at this.
Was trying to set it = 1 but keeps throwing an exception.
Absolutely!
Okay, do you want to do it? It’s 4am here for me …
At least one other person is also getting this error
I don’t think I’ll be able to get to it today though (have a bunch of errands to run). Some time next week, realistically.
Okay, I’ll try to work on it later too. Or maybe someone else will get to it.
I still didn’t get the ordering to work. I trust that your method works as you say. Do you see anything wrong with my code?
Summary
nlp.py
trn_iter,val_iter,test_iter = torchtext.data.BucketIterator.splits(splits, batch_sizes=(bs, bs, 1))
in my notebook:
md2 = TextData.from_splits(PATH, splits, 1) #setting all bs to 1, just for making predictions
m3 = md2.get_model(opt_fn, 1500, bptt, emb_sz=em_sz, n_hid=nh, n_layers=nl,
dropouti=dropouti, dropout=dropout, wdrop=wdrop,
dropoute=dropoute, dropouth=dropouth)
m3.reg_fn = partial(seq2seq_reg, alpha=2, beta=1)
m3.load_encoder(f'h2_adam1_enc')
m3.load_cycle('h1',3)
val_preds,y = m3.predict_with_targs()
res = np.argmax(val_preds,axis=1)