Hi guys,
I’m training a collaborative filtering model and I keep getting training loss like this:
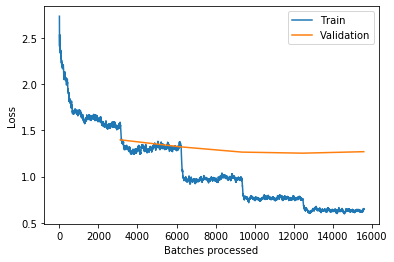
I think it isn’t a sign over too high learning rate because the loss is decreasing over time. But why this strange shape and not a smooth line?
Hi guys,
I’m training a collaborative filtering model and I keep getting training loss like this:
I think it isn’t a sign over too high learning rate because the loss is decreasing over time. But why this strange shape and not a smooth line?
If you look closely you see that the first step starts with the beginning of the orange validation loss line, i.e., the first run of the validation set after the first epoch, and then reoccurs after every (not so easy too see) new data point of the validation loss (= after the beginning of every new epoch).
So this steps are always happening when the network is seeing the data for another round in a new epoch.
In addition, these steps are less visible if you are using data augmentation because then the training examples look a little bit different every time the network is seeing them the next time.
At least this is my hypothesis. Now the question is, if you have used data augmentation in your experiment or not. 
Are you using any callbacks? My first thought was something happening in on_batch_begin. A quick scan didn’t show anything in fastai.colab (or fastai.tabular which it uses) but might have missed something or it could be some non-default callback.
You haven’t disabled shuffle? In that case it might be some particular input, but seems too regular to be that otherwise.
Or anything custom? Maybe a wrongly implemented loss function that’s taking epoch into account. But pretty wildly stabbing here.
Couldn’t really think of any other likely reasons other than something along MicPie’s line.
I’m using a custom collab arch and the only callback I’m using is CSVLogger, but I got the same pattern using just collab_learner(). The loss function is flat MSE (the same one Jeremy used in Lesson 4). Besides my architecture I didn’t change anything. Its really odd!
This is an old thread, but I just noticed the same thing today with the unmodified DotProductBias model from https://github.com/fastai/fastbook/blob/master/08_collab.ipynb. I checked that dls.train.shuffle is True and learn.cbs doesn’t have anything unusual. list(dls.train[0]) is clearly giving different results each time it’s called, so I suspect that shuffling is working.
I thought it might have something to do with the learning rate scheduling that fit_one_cycle does, but I see it even with:
learn.fit(n_epoch=4, lr=5e-3, wd=0.1, cbs=ShowGraphCallback())
(the ShowGraphCallback makes it really obvious, but it occurs even without that.)
A quick scroll through the Learner code doesn’t reveal any smoking guns. Anyone?
I found a similar behaviour using another kind of architeture. Turns out, my model was overfitting. Try increasing regularization to see if that changes anything.