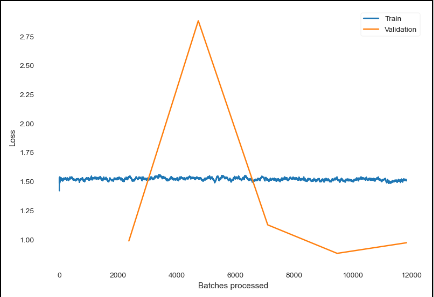
I am very new to fastai and ML in general. I have been training a tabular model to predict a status based on sensor readings. The problem i am having now is that the validation dosent happen nearly as much as the training. When i print out the learn.recorder.plot_losses(), I am given this plot.
I would like to validate more frequently, as this dosent. Do you have any idea how to change this?
Any help is greatly appreciated:)
In general you train for one epoch (= one pass through your training data), then you validate and then you move on to the next epoch. Note that the x-axis shows batches processed, not epochs processed so naturally you will have more steps of training than validation.
In your case validation happens only after more than 2000 batches processed. If your training set is very large this can be ok. However, you might need to train longer. The more disturbing part of the plot is that your training loss doesn’t seem to be going down during training.
Could you provide more info, e.g. training/validation set size and batch size?
The trainingset is a panda dataframe which is aprox. 150000 rows. Same for test-set. Validation is now 10000, using the split_by_idx-method. The batch size i haven’t set, so i assume it is the default 64. Would it help if i posted the code here?
Yes, it’s probably 64 so you end up with ~2300 batches per epoch. That seems alright. I don’t think the validation frequency is a problem here. You could theoretically write a callback that validates more frequently than at the end of each epoch, but that’s not trivial and I have never seen that.
Since it’s not a bug, I’m not sure if sharing your code helps here. But of course you can post it.
Here a few tips that might help you:
start with a small subset of your data. Once everything is working, move on to the full size
try a random forest instead of tabular learner. It’s simpler, more robust and more interpretable
before worrying about generalization, make sure your model can fit the training data
okey, i will try with a smaller set. I will also try out the random forest learner:)
Thanks again for the help and useful tips stefan, really appreciate it!