I’m trying to use a COCO-style dataset, where some of the images do not contain any bounding boxes.
I tried following the the tutorial in the documentation. Since some images do not have any bounding boxes, I used a defaultdict:
img2bbox = defaultdict(lambda: [[],[]])
for image_id, data in zip(image_ids, data_by_image):
img2bbox[image_id] = data
get_y_func = lambda o:img2bbox[os.path.splitext(o.name)[0]]
This results in output similar to this for a given image:
img2bbox[image_id]
=>
[[
[1050.0, 898.0, 86.0, 21.0],
[724.0, 1864.0, 27.0, 29.0]
],
['U+4E00',
'U+309D']
]
I then create an ImageDataBunch, using the following code:
data = (ObjectItemList.from_folder(train_path)
#Where are the images? -> in coco and its subfolders
.split_by_rand_pct()
#How to split in train/valid? -> randomly with the default 20% in valid
.label_from_func(get_y_func)
#How to find the labels? -> use get_y_func on the file name of the data
.transform(get_transforms(), tfm_y=True, size=64)
#Data augmentation? -> Standard transforms; also transform the label images
.databunch(bs=16, collate_fn=bb_pad_collate))
#Finally we convert to a DataBunch, use a batch size of 16,
# and we use bb_pad_collate to collate the data into a mini-batch
This results in a warning:
UserWarning: There seems to be something wrong with your dataset, for example, in the first batch can't access these elements in self.train_ds: 176,1205
The ids in the warning message matches images without any bounding boxes.
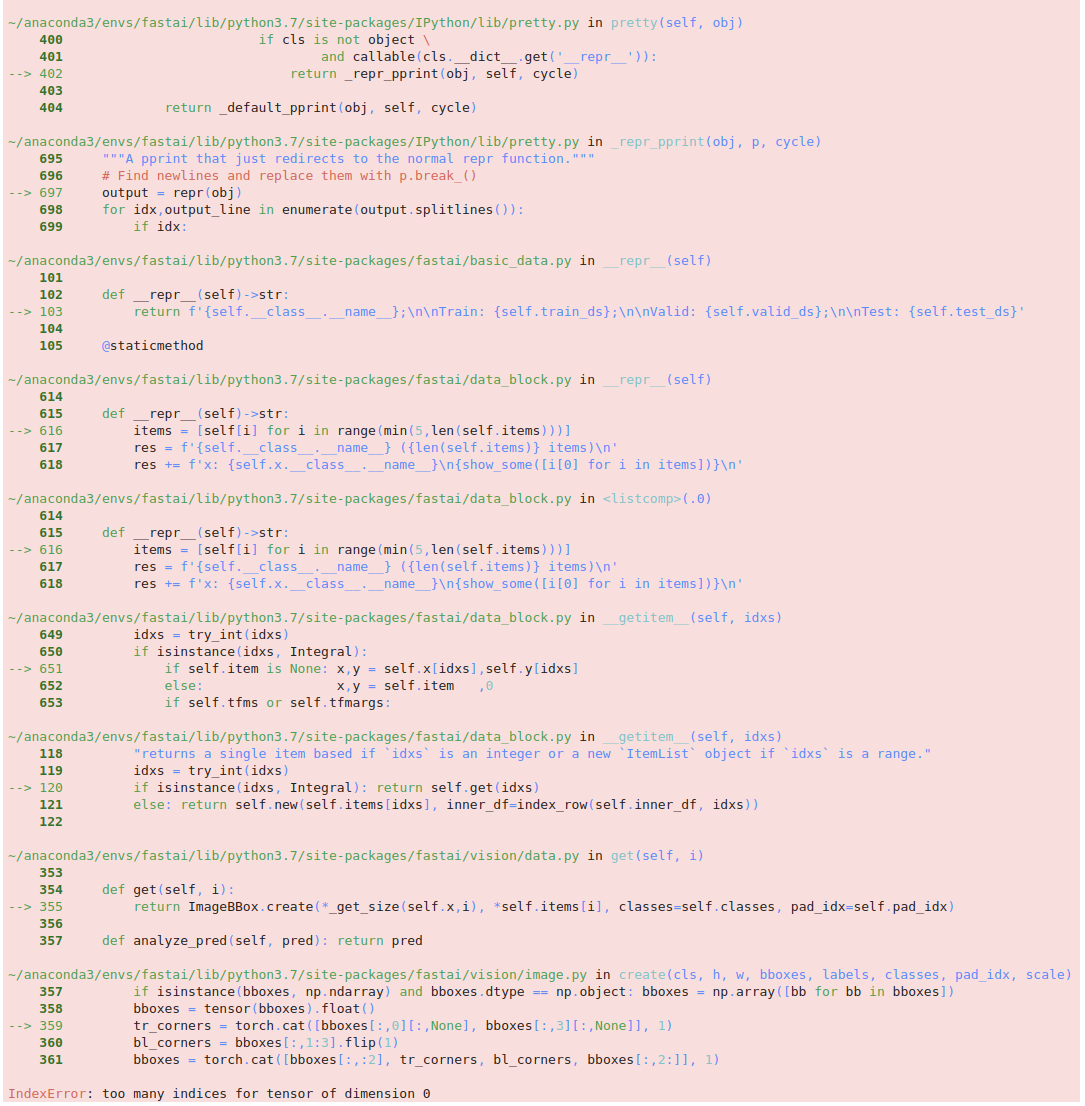
Running the following results in an error:
data
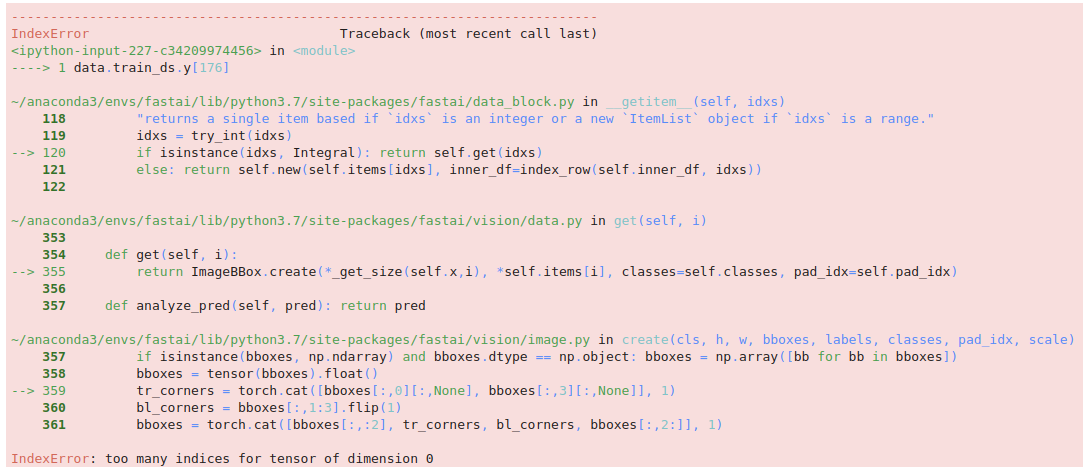
And trying to access y for an image without any bounding boxes:
data.train_ds.y[176]
If anyone have any ideas on how to make this work, I will be very grateful.