Hi, in lesson 3- imdb, notebook. We trained a LM and saved the encoder and use it as the input layer of Classifier. I have the question, in fastai, can I extract the encoder output itself i.e. if I feed the encoder a string, it output a d dimension vector as encoding?
1 Like
@evan.xiong. I had this same question, wrote up the solution here.
Short answer is:
def process_doc(learn, doc):
xb, yb = learn.data.one_item(doc)
return xb
def encode_doc(learn, doc):
xb = process_doc(learn, doc)
# Reset initializes the hidden state
awd_lstm = learn.model[0]
awd_lstm.reset()
with torch.no_grad():
out = awd_lstm.eval()(xb)
# Return final output, for last RNN, on last token in sequence
return out[0][2][0][-1].detach().numpy()
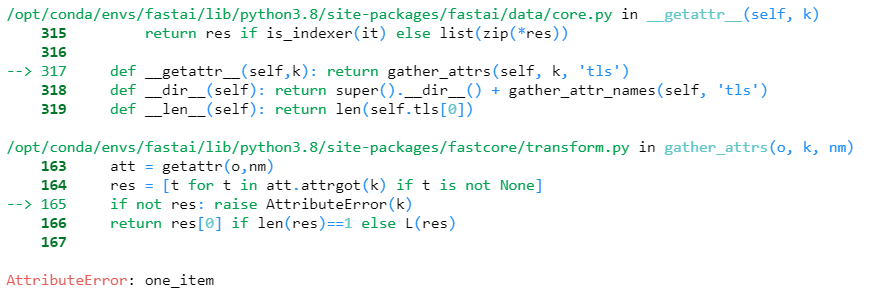
@Alden Hi, In your Blog you created the object using TextLMDataBunch right…? I have encountered a problem where i created Data using Datablock from dataframe and trained the model and saved it. Now,I am trying to get the encodings of a test documents but got an attribute error “one_item”.
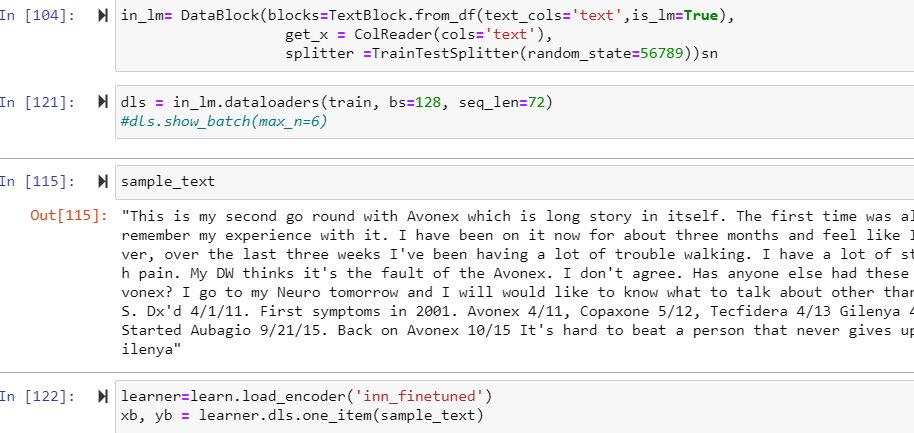
I am new to this library. I have seen that fastai released second version. Is there any changes in the code to get the encodings…?
Hello Alden,
I loved your article and the approach to extract the document embeddings from the encoder. However, this approach takes 4 min for 500 records (seq length of 72), which is very high latency for productionizing a application. Have you faced such problem? Or is there any faster way of extracting the encodings of text from encoder?
Regards,
Chaitanya Kanth.
1 Like