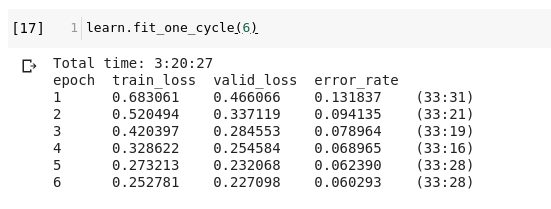
Ok here’s what happened. No matter how hard I try changing epochs or learning rate val_loss is still lower than train_loss. I’m trying to do a classification of my native language script alphabets, with 84 classes. Here’s my code and result’s by far:
Code: https://colab.research.google.com/drive/1o2uGnYfD4IX2ij7M2ZrHcqpN-FFk_Lom
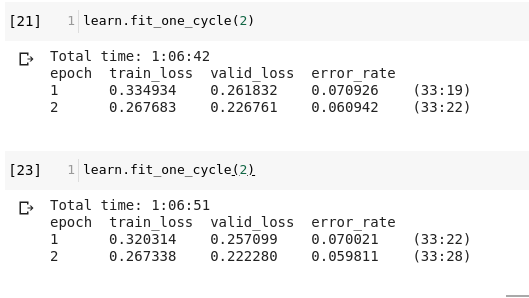
Now the problem is, colab is dying often(after 4 hours once, and after 6 hours of train another time yielded no result), and is slow(taking about 1sec for a batch, and I have a huge dataset); so after training of say 6 epochs (almost 3.5 hours) if I find a few more epochs would have made it. But to add two epochs will add a 5 hour penalty, since I have to run learn.fit_one_cycle(8) instead of learn.fit_one_cycle(2) which will take 1 hr more. I can’t use learn.fit_one_cycle(2) because as you can see from the screenshots the loss is increasing (and it should because the learning rate should’ve decreased I guess, instead it is increasing). It will be very helpful if someone can say how to bypass this problem.
You can save the trained model using learn.save(‘example-model’) and skip retraining it again, like what Jeremy showed in class.
For Colab, it will be saved in your dataset folder, in a folder named ‘models’. It will have a file extension .pth. Download it to your local drive (say desktop) and upload into Colab when you are ready for next round of training (say after you re-initiate Colab).
To let Colab find the saved model, you have to put back the .pth file in ‘models’ folder, which is in your dataset folder. You may need to create folder named ‘models’ and put in under your dataset folder.
To upload file into Colab, use:
from google.colab import files
files.upload()
it will prompt you to upload file. Select the file and upload starts. However, this method is very slow.
Alternatively, upload the .pth file (saved model) to a cloud storage (say Dropbox). Create a share link. Upload the file using:
!wget -O example-model.pth share-link
Then move the file:
!mv example-model.pth dataset/models
Please refer to the Colab platform post for more specific info.
That was what I would exactly do, but as you can see my problem is not that. My problem is, if I somehow set the epochs too low, due to the nature of 1cycle policy, it makes no sense to add new training code. Eg. If I started running learn.fit_one_cycle(6), then after two epochs realise that 6 epochs won’t be enough, I can’t just write learn.fit_one_cycle(2), making it 6+2=8; because at the 7th epoch of learn.fit_one_cycle(8) learning rate should have decreased instead of increasing.
I have found a temporary solution, that is to run learn.fit_one_cycle(2, max_lr=slice(None,0.0003)) instead of learn.fit_one_cycle(2) which has max_lr=slice(None,0.003,None). This keeps the learning rate low.