I am mostly running into large datasets these days. Be it on kaggle or on other platforms and i mostly run into memory full errors in my crestle or aws instances. How do people in this forum deal with that?
GPU memory or RAM?
I’ve been able to mitigate GPU memory issues with batching I’ve yet to find a good software solution to fix RAM shortages.
i am talking about the memory of the disk to store datasets
I guess the only way is to buy a bigger volume as soon as at the end of the day you need to store the data somewhere to feed into model 
1 Like
@abhigupta4981
I am also facing the same issues. When i am working on large data sets I am getting
RuntimeError: CUDA error: out of memory
I am taking batchsize=32
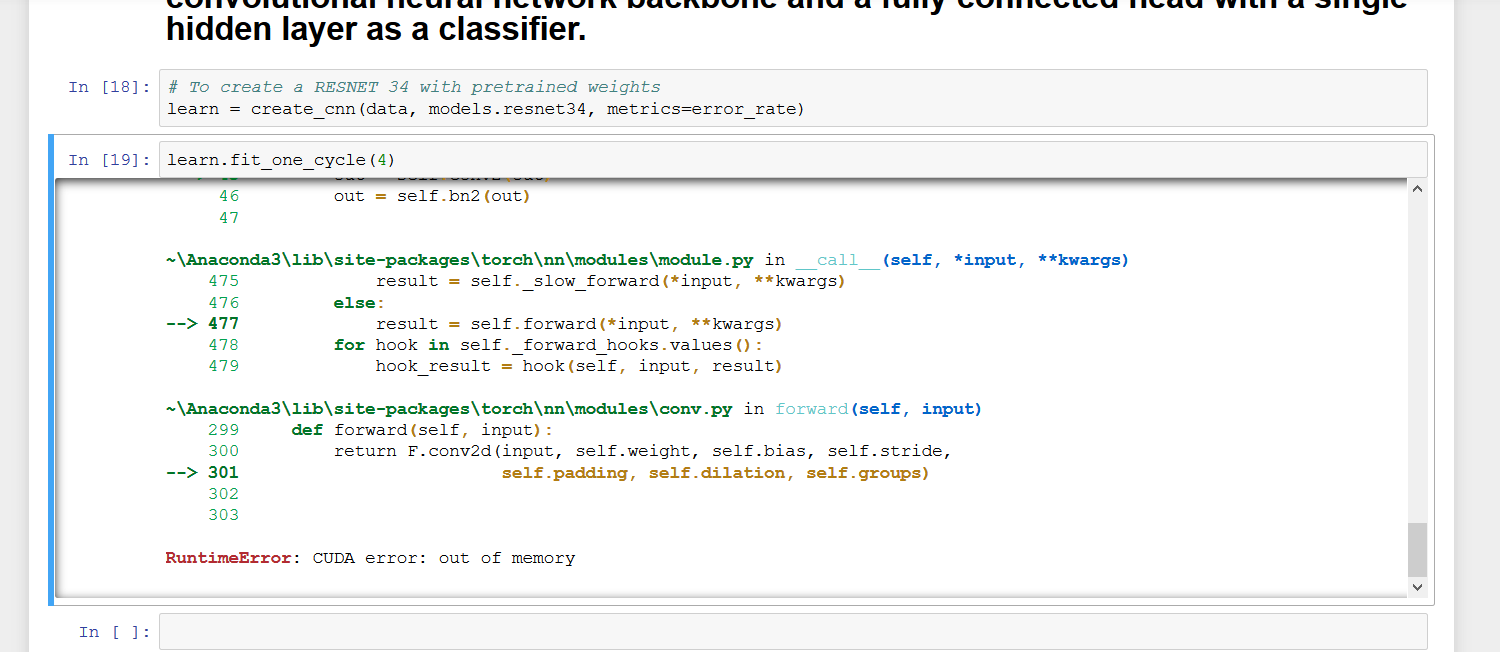
Please suggest how to deal with large datasets . If i am uploading these datasets in crestle or salamander it is taking lot of time to upload but if I am running these datasets in my system directly I am facing
RuntimeError: CUDA error: out of memory
Laptop configuration:
16GB RAM
4GB Nividia Graphics card
Thanks,
Ritika
@ritika26 jeremy had suggested to decrease the batch size for systems with small resources. You should try decreasing the batch size to 16 or 8. Or the other option is instead of uploading datasets to crestle, you can wget or curl the dataset.
1 Like
Thanks for the quick response. I am already using the small batch size. Can you please share any documentation on wget or curl the dataset.??
You might want to watch the first lecture of Machine Learning (fast.ai) where jeremy walks you through of the steps to download the dataset.
Here’s my approach:
- Delete Windows: No more gaming-time to grow up.
- Try Random sampling from the dataset.
For ex:if my disk can hold 30% of the data, train with 8 different samples. Then try running the same on AWS or GCP once I have a good understanding of what I want to do.
Generally I’ve learnt: No matter how big your dataset is, always try to build a quick baseline. No matter how simple or plain it be-use 1% of the data, use 0.5% of the data but first thing is to validate a few ideas.
Ex: Use 1% of the data-check accuracies with a few architectures, after having an idea-use 2% or 5% of the data, re-validate my ideas.
Note: This isn’t the best approach-just my approach to things given that I’ve a small (compared to dataset size) Storage disk.
2 Likes
if you have the link of the dataset to download, you can use wget <link> in the terminal by going to desired location. It will download the dataset.
Thanks @init_27 . I will watch the first lecture of ML (fast.ai) and will follow the steps shared by Jeremy.
1 Like
Thanks @abhigupta4981
Yes, the only way to get rid of this error is to reduce your batch size or image size parameters. Otherwise, you need more GPU memory.
If you want to upload or download a lot of files quickly I suggest use something like “GNU parallel”.
It is available here https://www.gnu.org/software/parallel/ and for most Linux distributions can be installed from package repositories.
Parallel will let you run concurrent tasks like for example, run multiple “wget” commands. All you need to do is feed it a list of command and tell it how many to execute at a time until completion.
Example: parallel --jobs 10 --eta < text_file_with_commands.txt
This will execute 10 commands from the text file in parallel and provide an estimated time of completion.
2 Likes
Thanks @devforfu
Thanks @maral. Let me try this solution
Thanks I didn’t know about that. It will be a lot of help