Create a search feature for a web app that shows the information the most relevant to what the user types in the search bar. In other words, I have a bunch of tables and if the user types something like “plants”, I want all the tables that have words similar to “plant” to show up. This might be used as a way to reduce the need for labelling each table (or at least reduce the workload).
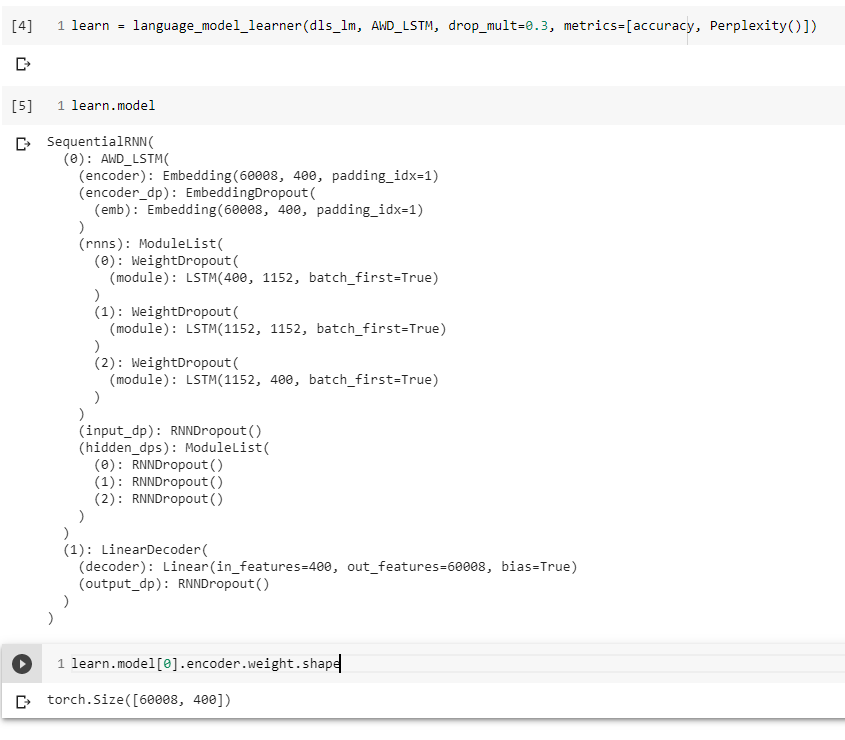
Now, I’m going to do transfer learning on my dataset. From what I understand, I can then use the new embedding matrix to find out which words are the most similar. How would I do this with the fastai library?
This seems like exactly what I want to do with text. However, I’m still confused as to what is the equivalent in fastai.text. In other words, there is no i_weight.weight in fastai.text.learner so how would I go about getting the word vectors?