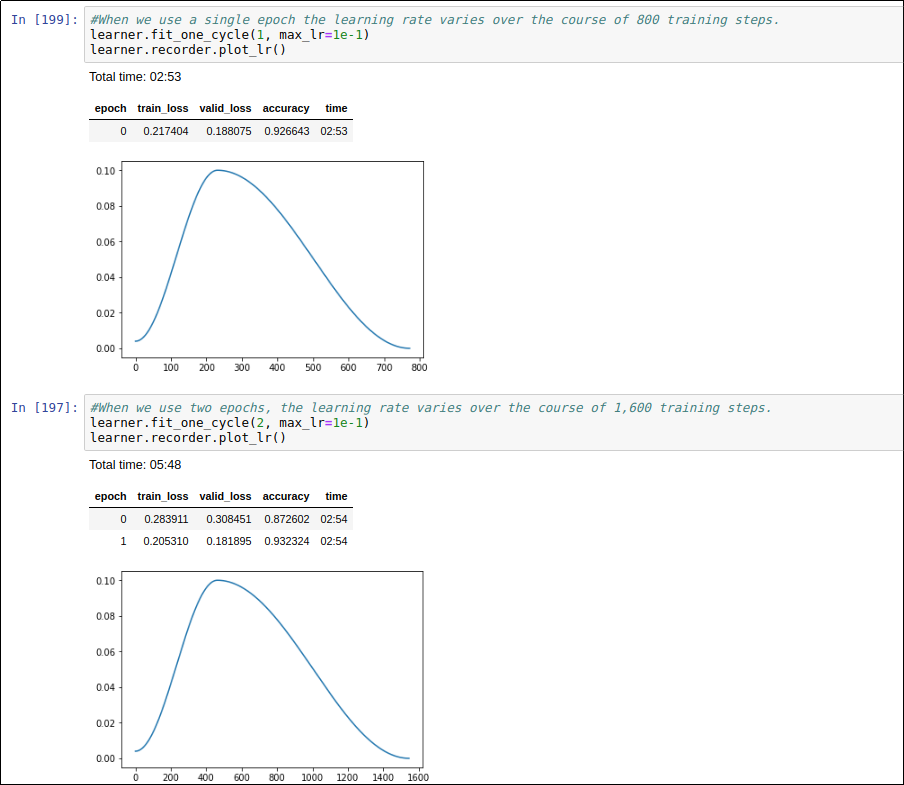
I have had a lot of success with .fit_one_cycle() and find it helps my models train quickly.
One issue I see is that the number of epochs I choose changes my learning rate schedule. For example, if I use 2 epochs, I vary my learning over the course of both epochs. If I use 1 epoch I vary it over the single epoch. See below image for example:
I’m wondering if anyone knows whether it is better to use .fit_one_cycle() over the course of say 20 epochs or of it is better to call .fit_one_cycle()20 times for a single epoch.
The reason I ask is because it is often difficult to know how many epochs I should be training for. One strategy I see a lot of people use on Kaggle (typically without cyclical learning rates) is to use learning rate decay and resets. They make sure to save their best network which is basically a form of early stopping. This is appealing to me because I don’t know how many epochs to use when I’m training a variety of neural network architectures.
The idea of one cycle is to use just one cycle. Usually I start by calling .fit_one_cycle() several times with a few epochs to see how the performance improves and then if I did for example 5 cycles of 4 epochs I will try one cycle of 20 epochs to see if results improve
It does take some trials to find the best number of epoch. Looking at the curve for the validation and training losses you will over time develop a good sense for best number of epochs.
fit_one_cycle is a much more efficient approach (to training than the stagewise reduction og learning rate etc. that most researchers use
This is a good question and I can understand your reasonning here.
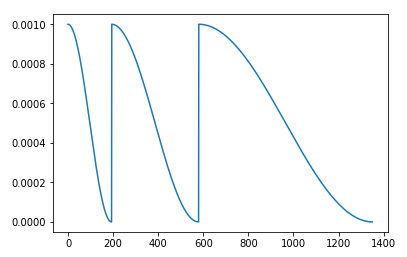
Actually, in the last year fastai course, the state-of-the-art technique to train a model was to do multiple cycles to perform what is called Stochastic Gradient Descent with Warm Restarts (see Figure below)
Apparently, while it gave very good results compared to the more basic training schedules like LR decay, Early Stopping, … the One-Cycle Policy that is used now is even better ! It can also produce what is called super convergence (see https://sgugger.github.io/the-1cycle-policy.html for a really good blog post from @sgugger about it).
Also, I suggest you to take a look at the Callback documentation (https://docs.fast.ai/callbacks.html#List-of-callbacks), you will see that nothing stops you from using fit_one_cycle with other techniques like early stopping, etc
Thanks for the blog post. One question still remains though: How is he choosing the number of epochs? For example the experiments in the linked notebook use:
Max LR 0.8 with 95 Epochs
Max LR 3 with 50 Epochs
Max LR 3 with 70 Epochs
It feels like I have to know ahead of time how many epochs I am going to need. This is in contrast to early stopping where I didn’t need to know this information.
The reason this is relevant to me is that I am often trying to train all of resnet34, resnet50, resnet101, resnet152, densenet121 etc. Currently I’m just roughly estimating how many epochs I “feel” like it should take, but I was hoping a more systematic approach might exist.
Yes the number of epochs is a parameter that you have to tune manually, along with the Learning Rate. But while the choice of LR can be tricky and requires some experience (to correctly read the lr_find graph), there is less room for mistakes in the choice of the number of epochs.
Indeed, it is difficult to make your model overfit due to a too high number of epochs (see Lesson 2 where Jeremy had to remove all regularization and data augmentation to get close to something looking like overfitting), so the worst that can happen by choosing a too high number of epochs is that you may loose your time (and money if you use cloud services), but it won’t hurt your models so much.
Again, fastai also supports Early Stopping, so maybe choose a high number of epochs (say 100) for your different models and make them stop if the loss isn’t improving for a while, just in case
In my past practice I have used shallow algorithms, identifying the best set of tuning parameters via a grid search with cross-validation. While I appreciate the value of interactivity in the Jupyter Notebook in terms of learning how these models train, ultimately I question this ‘hunt and peck’ approach to tuning parameters, in this case, number of epochs and cycles. While the grid search space for deep learning models would be vast, I wonder if it be more efficient in the long run, comparing to manual tweaking on my couch until past midnight.
I take a pragmatic approach. I choose a learning rate that looks good via the learning rate finder, then I run for however many epochs I feel like waiting for. If the model still has room to run, I’ll repeat the process at a slightly lower learning rate until the model stops improving or starts to overfit.