hi thanks for the response.
It is the modified version of the chapter4 last part open ended question. where a non linearlity was added.
In the chapter there is no scratch way given to train a model for more than 1 layer and more than one set of weights.
So far I cam across this piece of implementation but still whenever I am printing w1 in the logs I see that w1 is never getting updated. that is loss is only getting propagated towards w2 and not from w2 to w1.
# one layer with 30 neurons.
# with relu activation function.
# then next layer with 1 neuron.
# then apply the sigmoid.
# the second dimension in the matrix denote the number of neurons.
## Non linear net with more than one activation functions ans sigmoid in last layer.
## This is production used neural network in today's date.
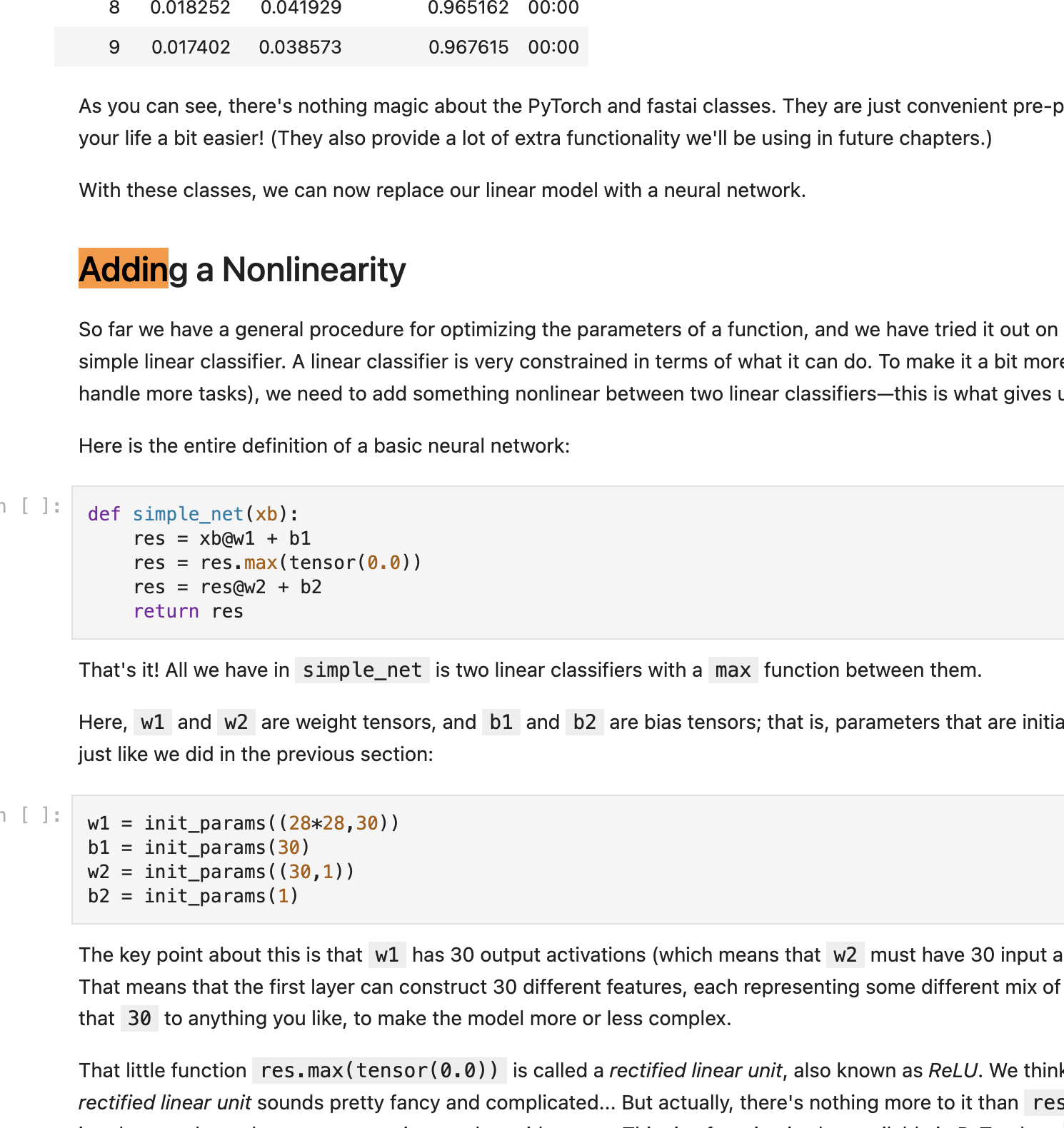
w1 = init_params((28*28,30))
b1 = init_params(30)
w2 = init_params((30,1))
b2 = init_params(1)
def complex_net(x):
res = x@w1 + b1
res = torch.relu(res) # this will not work and loss will not get propagated to next layer if torch activation functions are not used. since math is of torch thus use math functions also from torch library.
res = res@w2 + b2
return res
def mnist_loss(predictions, targets):
predictions = predictions.sigmoid()
return torch.where(targets==1, 1-predictions, predictions).mean()
def calc_grad(x, y, model):
pred = model(x)
loss = mnist_loss(pred, y*1.0)
loss.backward()
def batch_accuracy(x, y, model):
pred = model(x)
# loss function not equals to accuracy as lost dunction penalizes
# 0.99 probability with a loss of 0.1 but in accuracy is probability is 0.99 then it clearly is a valid class and we need to compute this accuractely.
acc1 = (pred > 0.5) == y
return acc1.float().mean()
def train_a__complex_net_epoch(x, y, model, lr = 0.0001):
calc_grad(x, y, model)
w2.data -= lr * w2.grad.data
b2.data -= lr * b2.grad.data
# print("W2 DATA", w2.data, w2.grad.data)
# w2.backward()
# b2.backward()
w1.data -= lr * w1.grad.data
b1.data -= lr * b1.grad.data
print("W1 DATA", w1.data, w1.grad.data)
w2.grad.zero_()
b2.grad.zero_()
w1.grad.zero_()
b1.grad.zero_()
for i in range(3):
train_a__complex_net_epoch(train_x, train_y, complex_net, lr=0.1)
print(batch_accuracy(valid_x, valid_y, complex_net), end = '\n')
Output is like.
W1 DATA tensor([[-1.8053, -0.8775, 0.6938, ..., 0.9554, 0.2526, -1.1141],
[ 1.6942, 1.7738, -0.6138, ..., -1.8349, -0.7304, 0.0407],
[-1.0632, -0.8974, -0.7251, ..., -1.3899, 0.6839, 1.1826],
...,
[ 1.7208, 0.9560, 0.2970, ..., -1.0092, -0.8471, -2.4497],
[-0.1379, -0.1619, -0.6100, ..., 0.8664, -0.5725, 1.0455],
[-0.7145, -0.8339, 0.4436, ..., -1.8590, 0.4673, 1.4599]]) tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
tensor(0.5505)
W1 DATA tensor([[-1.8053, -0.8775, 0.6938, ..., 0.9554, 0.2526, -1.1141],
[ 1.6942, 1.7738, -0.6138, ..., -1.8349, -0.7304, 0.0407],
[-1.0632, -0.8974, -0.7251, ..., -1.3899, 0.6839, 1.1826],
...,
[ 1.7208, 0.9560, 0.2970, ..., -1.0092, -0.8471, -2.4497],
[-0.1379, -0.1619, -0.6100, ..., 0.8664, -0.5725, 1.0455],
[-0.7145, -0.8339, 0.4436, ..., -1.8590, 0.4673, 1.4599]]) tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
tensor(0.5515)
W1 DATA tensor([[-1.8053, -0.8775, 0.6938, ..., 0.9554, 0.2526, -1.1141],
[ 1.6942, 1.7738, -0.6138, ..., -1.8349, -0.7304, 0.0407],
[-1.0632, -0.8974, -0.7251, ..., -1.3899, 0.6839, 1.1826],
...,
[ 1.7208, 0.9560, 0.2970, ..., -1.0092, -0.8471, -2.4497],
[-0.1379, -0.1619, -0.6100, ..., 0.8664, -0.5725, 1.0455],
[-0.7145, -0.8339, 0.4436, ..., -1.8590, 0.4673, 1.4599]]) tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
tensor(0.5535)
Notice the zero gradients in w1.