So …
I’m working on updating my article/code on building mixed tabular+text datasets to v.2 and I’m trying to add the text tfms to the existing Pipeline built by the Tabular class.
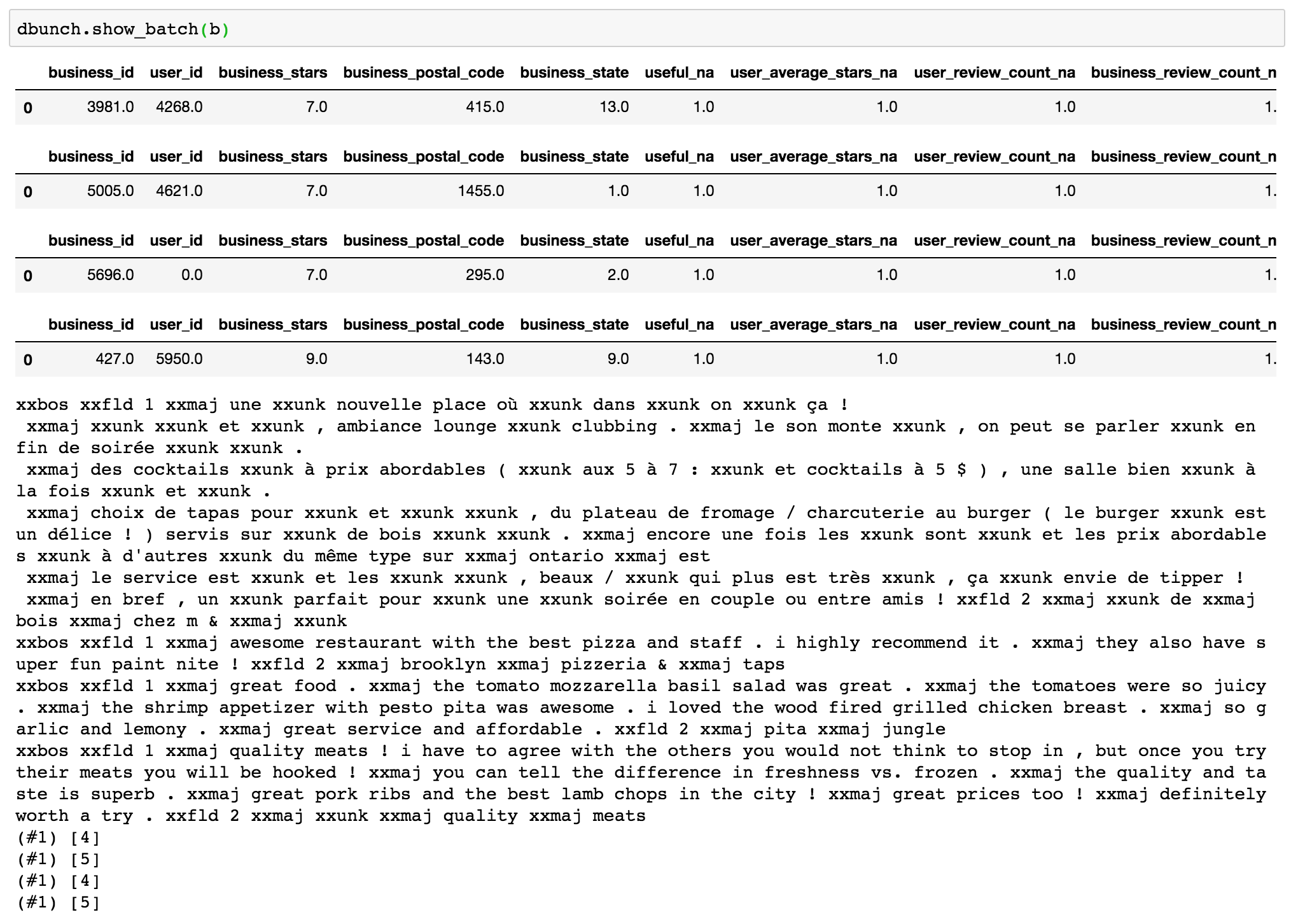
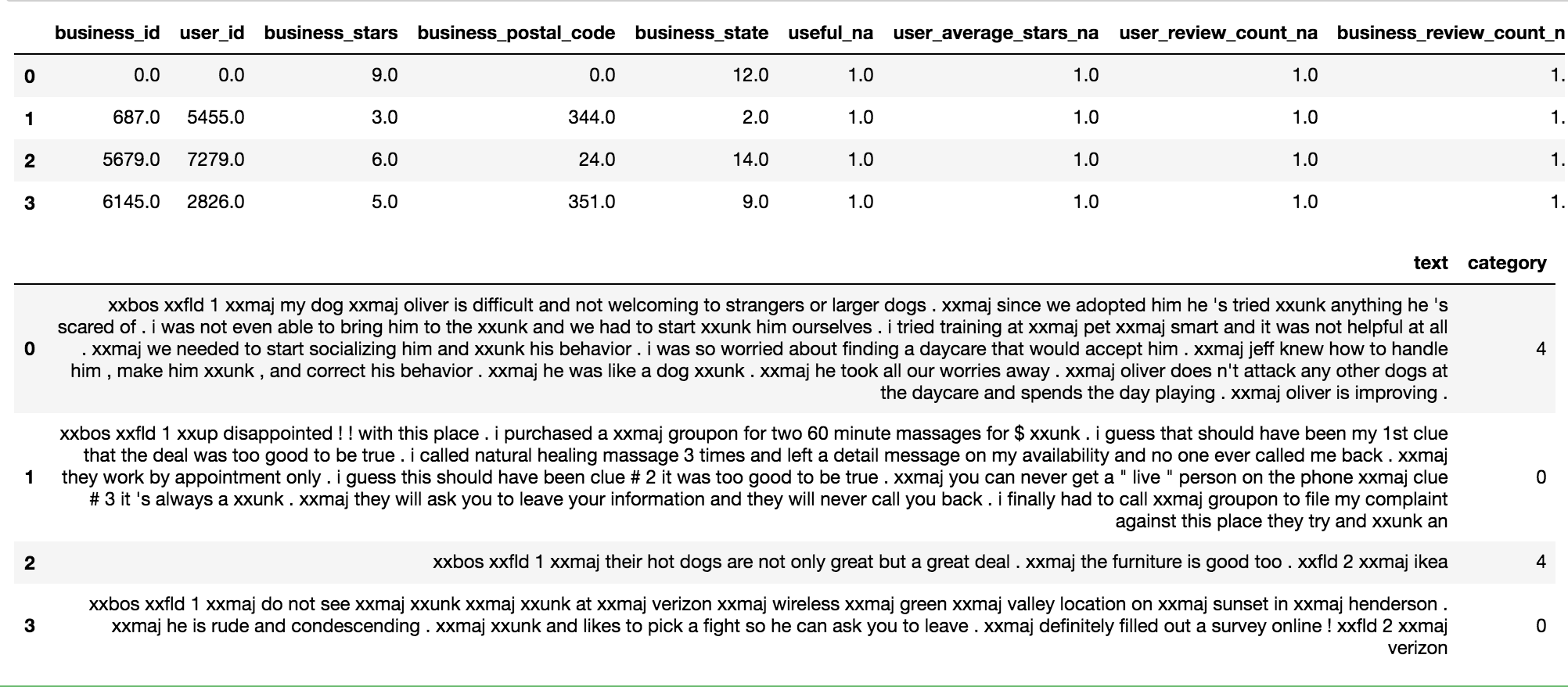
So far I have this:
cat_names = ['business_id', 'user_id', 'business_stars', 'business_postal_code', 'business_state']
cont_names = ['useful', 'user_average_stars', 'user_review_count', 'business_review_count']
text_names = ['text', 'business_name']
dep_var = 'stars'
lm_vocab = pickle.load(open("vocab.pkl", "rb"))
text_tfms = [Tokenizer.from_df(text_cols=text_names), Numericalize(vocab=lm_vocab)]
tab_procs = [FillMissing, Categorify, Normalize]
@delegates(Tabular)
class MixedTabularPandas(TabularPandas):
def __init__(self, df, text_names=None, text_tfms=None, vocab=None, **kwargs):
super().__init__(df, **kwargs)
self.text_names, self.text_tfms, self.vocab = L(text_names), text_names, vocab
self.procs += L(self.text_tfms)
@property
def all_col_names (self):
return self.cat_names + self.cont_names + self.text_names + self.y_names
But this line self.procs += L(self.text_tfms) doesn’t seem to accomplish that (I tried to use pipeline.add() and that didn’t work either).
Any ideas?