You’ll want to make a seperate databunch for just it, and pass in the ImageList to the validation when you want to run analysis via learn.validate(). The reason is the test sets in fastai are unlabeled. So here we can make a labeled test set to work with. An example using tabular is shown below:
Notice here that I make a separate databunch, classes is to ensure they have the same classes, and the processor is to make sure they align correctly transformation wise. If you need it I can quickly write one for an ImageList in a moment but see if you can’t work it out yourself first. Also notice the split_none() on the test set databunch.
Then when you are ready to use it and validate, you can do the following:
How do I set aside validation Set , from a dataframe ? Looking at the code of fast.ai, this from_df set the valid_pct to 0.2 which means 20% data is kept aside for validation set automatically ?
Below is my code , when I plot learn.recorder.plot_losses() , it doesn’t show the validation loss graph.
from sklearn.model_selection import train_test_split
train, test = train_test_split(df, test_size=0.2)
Followed by you can go through and run through the datablock api and pass in a train and validation dataframe (see the API for ImageList). If you need help with that let me know
Hi,
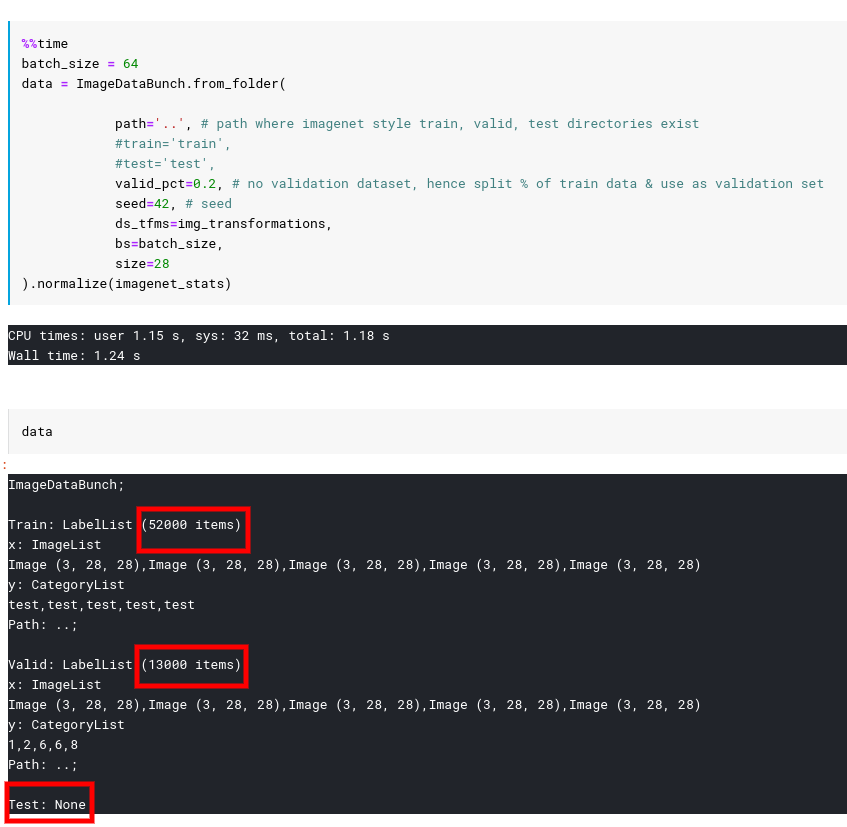
I have an image net style folder i.e. with ‘test/’ ‘train/’ and ‘valid/’ sub folders. When I create an imagedatabunch from this folder structure like this:
I faced a very similar issue today where I *did not * explicitly pass the test folder as part of ImageDataBunch.from_folder. This caused them to include test images as part of training dataset.
Here’s databunch creation code which also added test as one of the labels to be present in Confusion Matrix as you can see it includes all the images from the child directories as part of the training set (Test dataset is NONE).
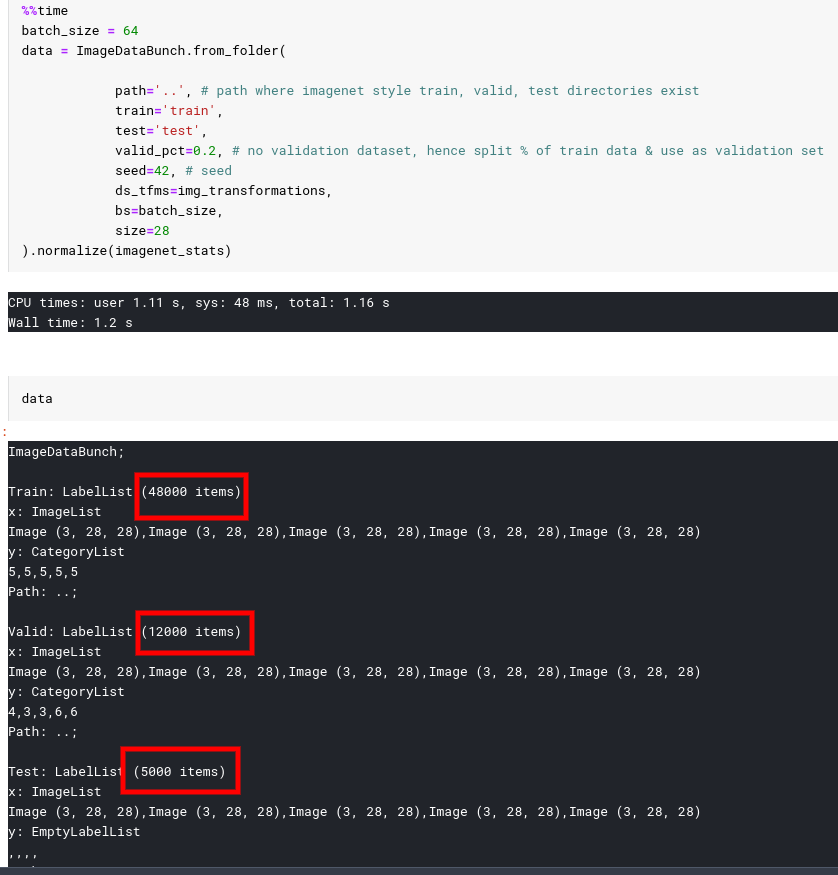
After fixing the data bunch code creation and explicitly specifying the train, test directory names, we can confirm that the databunch is created correctly.
Note that the factory methods are only there for the beginners and to grab “easy datasets”. You should learn to use the data block API which is far more flexible (and let you control which folders to include/exclude )
Hi All,
Wants some help, I want to apply quantile transformation(or any other transformation into the image) and the want to extract HOG features followed by multiple other features. And then want to give that feature set a input for my CNN learner.
How can I create that data frame in fastai? and pass to CNN learner and to validate the test data set how to apply all that and validate the test data set.

 )
)