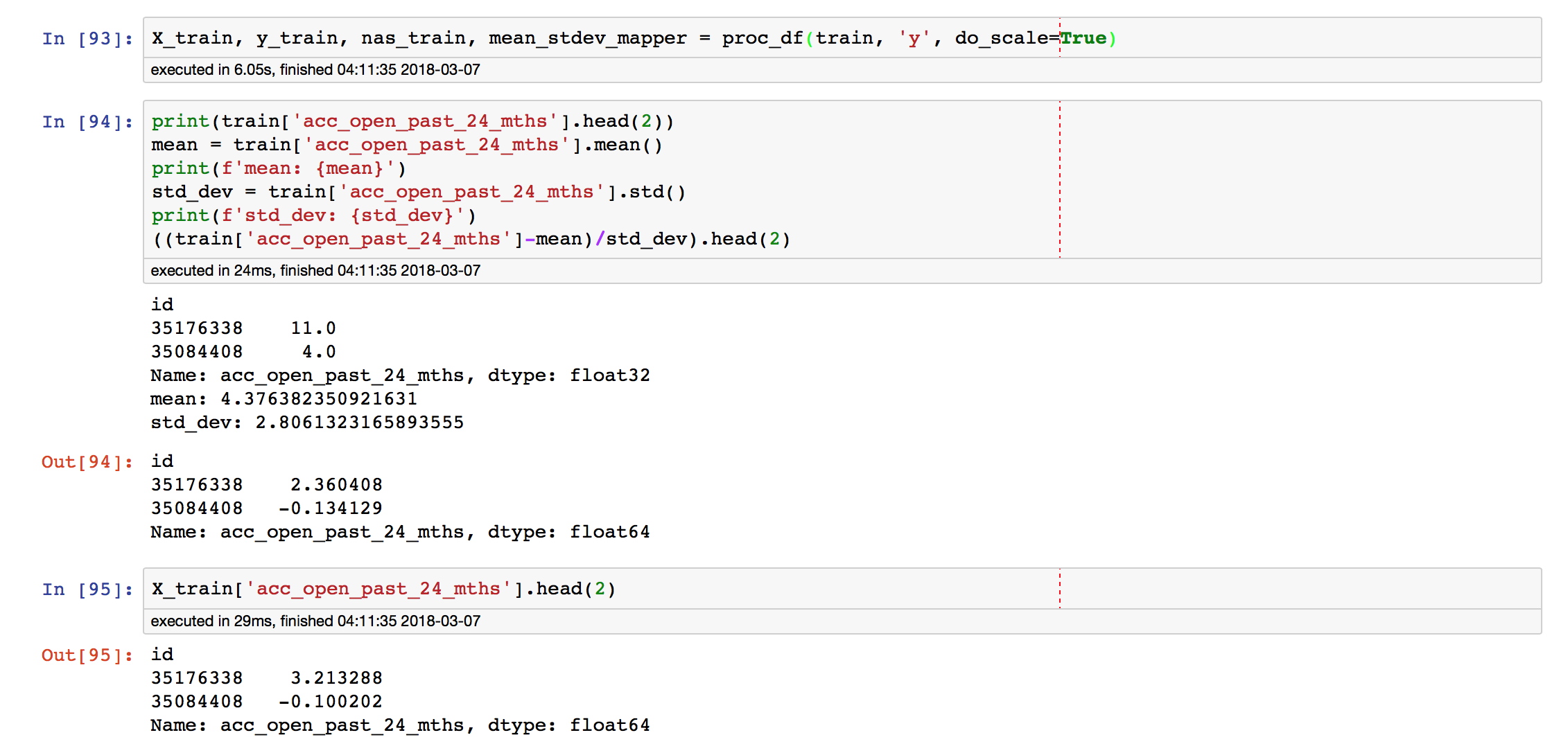
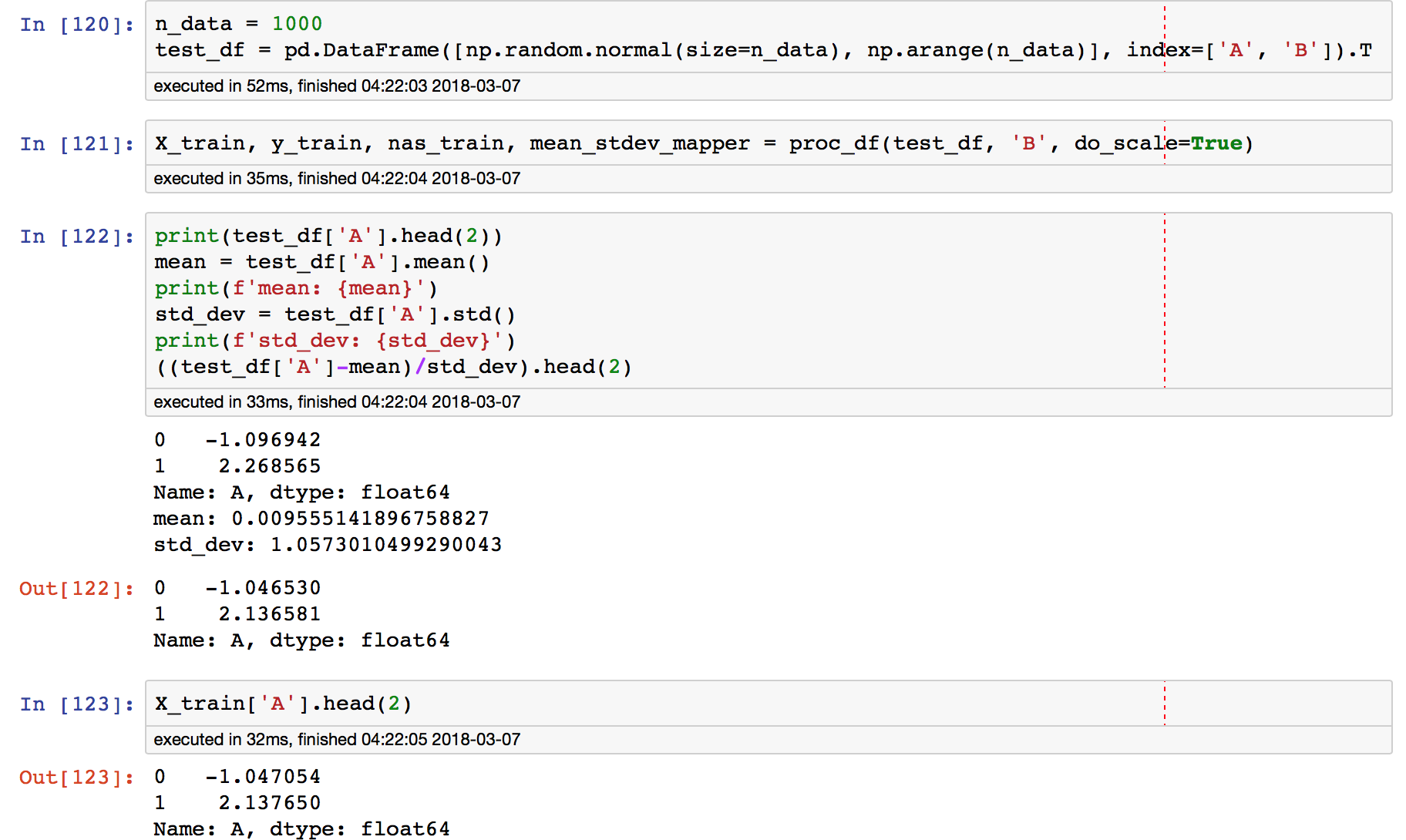
How is proc_df standardizing values?
Docstring says do_scale will standardize each column. Standardizing to me means (original_value - mean)/(standard_deviation). As my screenshot shows, I’m not seeing that.
I found that in my actual data, the discrepancy was due to proc_df filling null values with median values before standardizing. Doesn’t this make the variance of the data appear less than it actually is (making an array a lot longer with the same value should reduce the variance right)? I guess I’ll make a slightly altered proc_df that temporarily drops nulls before fitting the StandardScaler, fits the StandardScaler, fills nulls with median, and then normalizes.
This doesn’t explain the discrepancy in my trivial example though, which has no nulls. Still wondering about that.