In Chapter 9, we create a Random Forest to predict auction prices in the “Blue Book For Bulldozers” challenge, and then we try to determine how important each column in the dataset was to making our predictions:
def rf_feat_importance(m, df):
return pd.DataFrame({'cols':df.columns, 'imp':m.feature_importances_}
).sort_values('imp', ascending=False)
fi = rf_feat_importance(m, xs)
fi[:10]
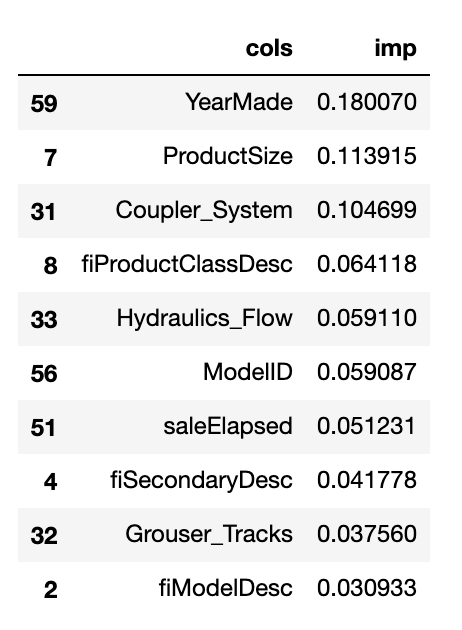
My question is, I don’t see how or where the values in the “cols” column are matched up with their corresponding values in the “imp” section. I printed out df.columns and m.feature_importances_, and I do see that the importances are sorted from highest to lowest, but I don’t see a common attribute which would help Pandas match a given importance to its respective column:
df.columns
=> Index(['SalesID', 'SalePrice', 'MachineID', 'saleWeek', 'ModelID',
'datasource', 'auctioneerID', 'YearMade', 'MachineHoursCurrentMeter',
'UsageBand', 'fiModelDesc', 'fiBaseModel', 'fiSecondaryDesc',
'fiModelSeries', 'fiModelDescriptor', 'ProductSize',
'fiProductClassDesc', 'state', 'ProductGroup', 'ProductGroupDesc',
'Drive_System', 'Enclosure', 'Forks', 'Pad_Type', 'Ride_Control',
'Stick', 'Transmission', 'Turbocharged', 'Blade_Extension',
'Blade_Width', 'Enclosure_Type', 'Engine_Horsepower', 'Hydraulics',
'Pushblock', 'Ripper', 'Scarifier', 'Tip_Control', 'Tire_Size',
'Coupler', 'Coupler_System', 'Grouser_Tracks', 'Hydraulics_Flow',
'Track_Type', 'Undercarriage_Pad_Width', 'Stick_Length', 'Thumb',
'Pattern_Changer', 'Grouser_Type', 'Backhoe_Mounting', 'Blade_Type',
'Travel_Controls', 'Differential_Type', 'Steering_Controls', 'saleYear',
'saleMonth', 'saleDay', 'saleDayofweek', 'saleDayofyear',
'saleIs_month_end', 'saleIs_month_start', 'saleIs_quarter_end',
'saleIs_quarter_start', 'saleIs_year_end', 'saleIs_year_start',
'saleElapsed'],
dtype='object')
m.feature_importances_
=> array([0.18308708, 0.12255999, 0.10670719, 0.06363137, 0.03278396, 0.05066305, 0.05594856, 0.04974523, 0.03900085, 0.03983336, 0.02957461, 0.04450207, 0.02110357, 0.02251339, 0.02173253, 0.01700456,
0.02101174, 0.03604535, 0.01987074, 0.00971266, 0.01296814])
My goal is to ensure that in the future, I’ll be able to create a similar DataFrame and be confident that I’m looking at a correct match-up between columns and importances.