When we calculate the gradient, my understanding is that this is the effect on the loss function for each individual weight in the neural network holding the other weights constant. So for example, if we have just two weights w_1 and w_2, we might get a gradient that suggests if we decrease w_1 slightly while keeping w_2 constant, the loss function will decrease, and similarly that if we decrease w_2 slightly while keeping w_1 constant, the loss function will decrease slightly.
But it could be the case that if we were to increase both w_1 and w_2 at the same time, that would result in an even greater decrease in the loss function. And we’ll miss this when we calculate the gradient because we are calculating a partial derivative for each weight “in isolation” so to speak. Is that right? If that’s right, is this just a long-winded way of describing local optima vs. global optima in the loss function?
I was thinking about this during the lessons that covered neural networks that take pictures as input, where it seems like the pixels should be extremely dependent on each other, and given that I’m surprised that gradient descent “works” on pictures at all. Is there some intuition for why gradient descent works in these cases?
Edit: now I’m kind of thinking out loud here – is this problem what the convolution layers are addressing? E.g., by reducing the number of weights in each layer to a point where we expect the remaining weights are less dependent on each other in each successively smaller layer, because the convolutions with high activations are “grouping” the most dependent pixels in an area into a single activation / weight in the next layer?
That is, I’m surprised that the vector of all the partial derivatives always gives us the steepest ascent, since my intuition (which is apparently wrong!) would be that taking the set of all the partial derivatives wouldn’t handle cases where two of the variables were correlated / dependent. However, I don’t follow any of the responses in that Stack Exchange, so I’m starting to wonder if it’s not that my intuition is poor, but rather that the reason this “works” is non-obvious.
Edit: I’m talking to myself a bit here, but after grilling ChatGPT on this for a while, I may have been too hard on my gut ChatGPT tells me that the gradient is the direction of steepest ascent only when the local area of the function is linear and smooth – so, in my example above of two weights being highly dependent, that assumption would not hold: if the two weights were highly dependent on each other at that particular point in the loss function, that point would be exhibiting non-linear behavior and so the gradient would not be guaranteed to be in the direction of the steepest ascent at that point. Would love if someone who understood the math better than I did would confirm this (I tried searching for confirmation online bit didn’t find much on a first pass.)
I’ll try and explain my understanding as best as I can. I’m definitely not a Math PhD but I believe my general intuition about this is on the right track for the most part.
I think to help gain an intuition on why gradient descent does work it’s helpful to look at weight updates as infinitesimally small (approaching zero) where what you described doesn’t happen and isn’t a factor. Once you’re comfortable with the intuition/theory on why why it does work with infinitesimally small weight updates then you can start to think about weight updates not actually being infinitesimally small so the concern you raised is valid and causes problems in practice and what you can do to fix them. I think your concern can get in the way of understanding the intuition on why it does work. I’ll try and elaborate:
Theory/Gradient Descent Intuition:
When the updates to the weights are infinitesimally small, the behavior of the loss function in response to these changes can often be well approximated by the partial derivatives. This is because, in the limit of very small changes, the loss function can be approximated as a linear function of the weights, and the interactions between weights have a negligible effect. You can think of the other weights as effectively not changing because the changes are infinitesimally small approaching 0. The same holds true for all weights updated together as part of a single set up weight updates.
For sufficiently small steps, the gradient provides a good approximation for the best direction to move in order to decrease the loss. The assumption of linearity holds reasonably well, allowing the method to iteratively move towards a local minimum.
In the limit when updates are infinitesimally small what you described ‘doesn’t happen’.
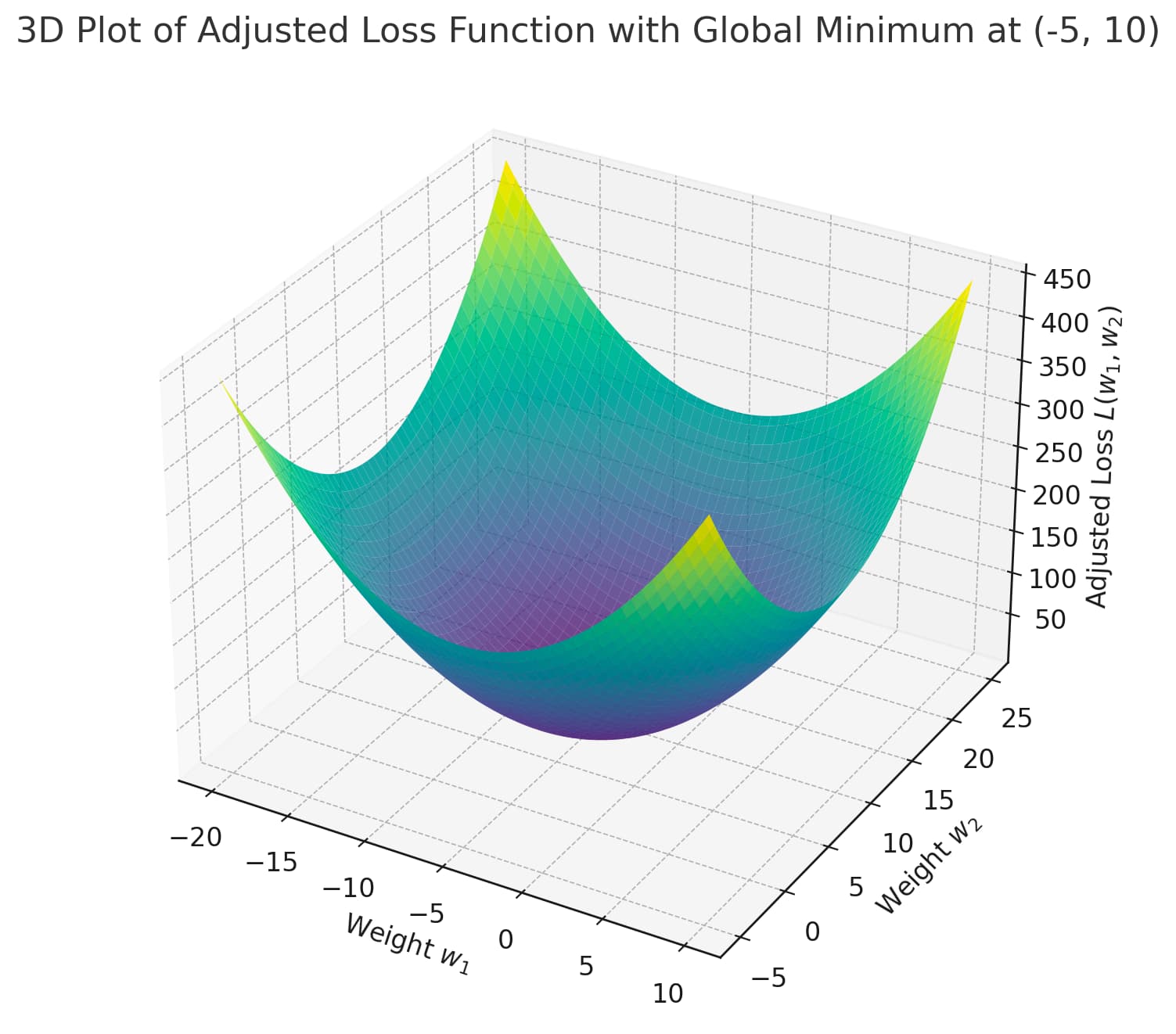
If you pick a point on this graph which represents the loss surface (loss values) for 2 weights and consider an infinitesimally small area around the point there are gradients for w1 and w2 that tell you which direction you need to step to decrease the loss. Taking an infinitesimally small step in that direction will essentially always take you to a new position on the loss surface where the loss has decreased by the maximum amount possible by taking the infinitesimally small step.
In Practice
Weight updates are not actually infinitesimally small so what you described is entirely possible and does happen. The linear approximation may not be accurate over the size of the step taken, and the interactions between the weights can become significant. This can lead to phenomena like overshooting a minimum, getting stuck in saddle points, or converging to local minima instead of the global minimum.
However also in practice the gradient descent process described by the theory has been proven to work in general. There are of course lots of exceptions and situations where it doesn’t work or isn’t optimal and there are a lot of other ‘tricks’ that have been discovered to help alleviate some of the problems with naive gradient descent like choosing operations that generate a smoother loss surface, variable learning rates, learning rate warm up and cool down, learning rate selection, momentum and cycling momentum, etc.
So I guess in summary, when you’re trying to build an intuition on why gradient descent does work (which is probably what you want start with) look at weight updates in the limit as infinitesimally small where the partial derivative for each weight does tell you the correct direction to step. Once you’re comfortable with that intuition then start to think about the cases where this doesn’t hold true and how to fix or improve the very real problems that it does cause.