I’m trying to make the leap to distributed training to speed up model development on my company’s ~10M image dataset. However, I am not sure how best to develop a model. The fastai course teaches highly interactive processes, such as using a learning rate finder, unfreezing a model, and increasing image sizes based on how training is progressing. I have seen little if any guidance on how to proceed during distributed training, which has to be done in a script rather than a notebook and doesn’t seem to play nicely with the learning rate finder or with the Python input function. Any tricks for making these techniques work or advice on how best to proceed without them?
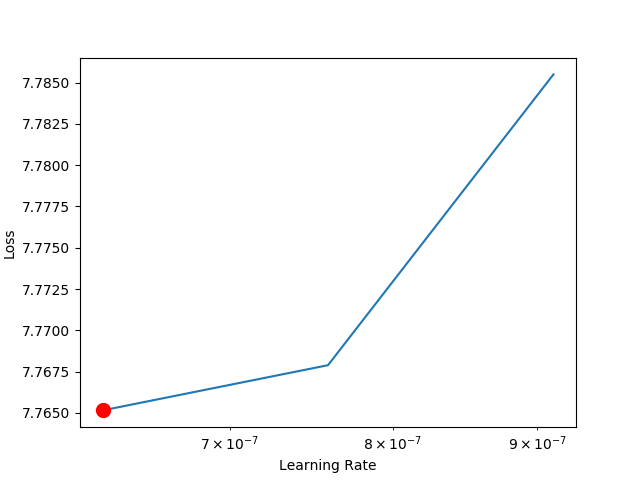
The learning rate finder will run in distributed mode, but the result doesn’t look right.
Hello,
For fastai v1, I built a Jupyter/ipython extension called Ddip ,which specifically addresses this need of distributed training in Jupyter notebook.
I intend to port this to fastai v2 asap as well.
Let me know if you have any questions.
I get an error when I run the first cell in https://github.com/philtrade/Ddip/blob/master/notebooks/Ddip_usage_fastai.ipynb:
---------------------------------------------------------------------------
OSError Traceback (most recent call last)
/opt/conda/lib/python3.6/site-packages/Ddip/ddp.py in __init__(self, n, engine_wait)
87
---> 88 try: self.client = ipyparallel.Client(timeout=engine_wait,cluster_id=f"{IppCluster.cid}")
89 except (IOError,TimeoutError) as e: raise Exception(f"ipyparallel Client() failed: {e}")
/opt/conda/lib/python3.6/site-packages/ipyparallel/client/client.py in __init__(self, url_file, profile, profile_dir, ipython_dir, context, debug, sshserver, sshkey, password, paramiko, timeout, cluster_id, **extra_args)
416 ])
--> 417 raise IOError(msg)
418 if url_file is None:
OSError: Connection file '~/.ipython/profile_default/security/ipcontroller-ippdpp_c-client.json' not found.
You have attempted to connect to an IPython Cluster but no Controller could be found.
Please double-check your configuration and ensure that a cluster is running.
During handling of the above exception, another exception occurred:
Exception Traceback (most recent call last)
<ipython-input-1-78ee041debd3> in <module>
4
5 get_ipython().run_line_magic('load_ext', 'Ddip')
----> 6 get_ipython().run_line_magic('makedip', '-g all -a fastai_v1 --verbose True')
/opt/conda/lib/python3.6/site-packages/IPython/core/interactiveshell.py in run_line_magic(self, magic_name, line, _stack_depth)
2315 kwargs['local_ns'] = sys._getframe(stack_depth).f_locals
2316 with self.builtin_trap:
-> 2317 result = fn(*args, **kwargs)
2318 return result
2319
<decorator-gen-159> in makedip(self, line)
/opt/conda/lib/python3.6/site-packages/IPython/core/magic.py in <lambda>(f, *a, **k)
185 # but it's overkill for just that one bit of state.
186 def magic_deco(arg):
--> 187 call = lambda f, *a, **k: f(*a, **k)
188
189 if callable(arg):
/opt/conda/lib/python3.6/site-packages/Ddip/magics.py in makedip(self, line)
96 gpus = self.gpu_str2list(args.gpus)
97 self.ddp.exit_group() # Exit old DDP group if exists
---> 98 self.ddp.new_group(gpus=gpus, appname=args.appname)
99 self.shell.run_line_magic("pxconfig", "--verbose" if Config.Verbose else "--no-verbose")
100
/opt/conda/lib/python3.6/site-packages/Ddip/ddp.py in new_group(self, gpus, appname, node_rank, world_size)
201 Returns a list of GPU ids of the group formed.'''
202 (n_gpu, n_device) = (len(gpus), torch.cuda.device_count())
--> 203 if not self.cluster: self.init_cluster(n_engines=n_device)
204 cl = self.cluster # shorthand
205 assert n_gpu <= len(cl.client), f"More GPU ({gpus}) than ipyparallel engines ({len(cl.client)}). "
/opt/conda/lib/python3.6/site-packages/Ddip/ddp.py in init_cluster(self, n_engines)
154 return '\n'.join([cluster_info, ddp_info, app_info])
155
--> 156 def init_cluster(self, n_engines:int=0): self.cluster = IppCluster(n=n_engines)
157
158 @classmethod
/opt/conda/lib/python3.6/site-packages/Ddip/ddp.py in __init__(self, n, engine_wait)
87
88 try: self.client = ipyparallel.Client(timeout=engine_wait,cluster_id=f"{IppCluster.cid}")
---> 89 except (IOError,TimeoutError) as e: raise Exception(f"ipyparallel Client() failed: {e}")
90 print_verbose(f"Connecting to ipyparallel cluster.", file=sys.stderr, end='')
91 while engine_wait > 0:
Exception: ipyparallel Client() failed: Connection file '~/.ipython/profile_default/security/ipcontroller-ippdpp_c-client.json' not found.
You have attempted to connect to an IPython Cluster but no Controller could be found.
Please double-check your configuration and ensure that a cluster is running.
Did I miss a step?
Hello Greg,
Let’s see if we can debug this a bit. Could you please try launching ipyparallel from a terminal shell first? Then we’ll try to connect to it from a Jupyter notebook?
Step 1. Open a terminal shell, and launch ipyparallel by hand:
ipcluster start -n 4 --cluster-id=ippdpp_c
The value 4 can be changed to the number of GPUs you want to use. On my linux the output looks like:
2020-04-24 10:10:06.200 [IPClusterStart] Starting ipcluster with [daemon=False]
2020-04-24 10:10:06.201 [IPClusterStart] Creating pid file: /home/ndim1/.ipython/profile_default/pid/ipcluster-ippdpp_c.pid
2020-04-24 10:10:06.201 [IPClusterStart] Starting Controller with LocalControllerLauncher
2020-04-24 10:10:07.205 [IPClusterStart] Starting 4 Engines with LocalEngineSetLauncher
2020-04-24 10:10:37.534 [IPClusterStart] Engines appear to have started successfully
Notice the 30 seconds wait before the last message appears – ipyparallel is slow to print it out. In my experience, the processes were launched within 10 seconds. But anyway, let’s see if you get to this stage first.
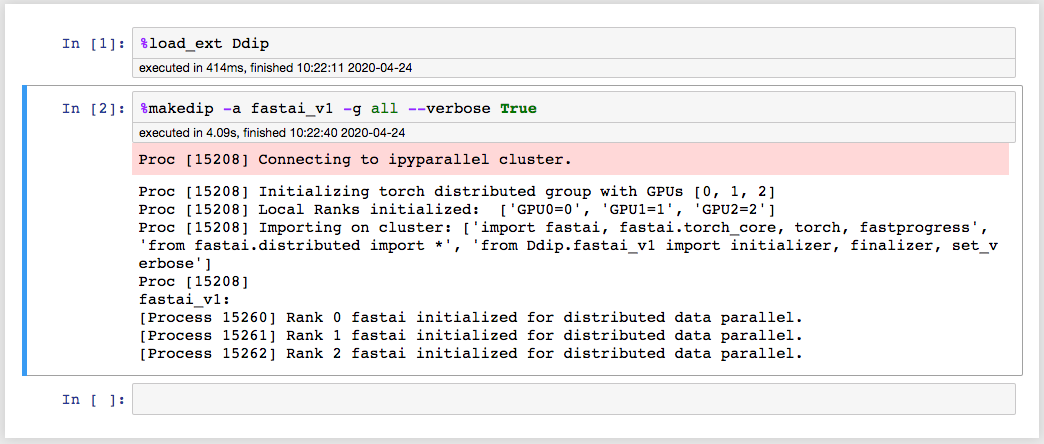
Step 2. Assuming step 1 goes through, start a brand new notebook, and execute the two ‘%’ magic lines. It should start to connect right away, because step 1 already launched the cluster of processes:
%load_ext Ddip
%makedip -a fastai_v1 -g all --verbose True
The output looks like this, on my system with 3 GPUs:
Let me know how that goes first.
1 Like
Hi Greg,
I’ve added a --timeout n option to %makedip, to let user specify the time waiting for the clusters to connect. If you install from the head of the repo:
pip install git+https://github.com/philtrade/Ddip.git
then you can try, for example, up to 30 seconds wait:
%makedip -a fastai_v1 -g all --verbose True --timeout 30
Let me know if that works for you.
Thanks.
It looks like my cluster is starting, but it’s repeating prefixes in the pid file names:
root@9753372fd521:/fastai# ipcluster start -n 4 --cluster-id=ippdpp_c
2020-04-24 20:01:50.337 [IPClusterStart] Starting ipcluster with [daemon=False]
2020-04-24 20:01:50.338 [IPClusterStart] Creating pid file: /root/.ipython/profile_default/pid/ipclusteripcluster-ippdpp_c.pid
2020-04-24 20:01:50.338 [IPClusterStart] Starting Controller with LocalControllerLauncher
2020-04-24 20:01:51.342 [IPClusterStart] Starting 4 Engines with LocalEngineSetLauncher
2020-04-24 20:02:21.658 [IPClusterStart] Engines appear to have started successfully
root@9753372fd521:/fastai# ls /root/.ipython/profile_default/pid/
ipclusteripcluster-ippdpp_c.pid ipcontrolleripcontroller-ippdpp_c.pid
That explains the error I’m getting. If I rename those files and the corresponding files in ~/.ipython/profile_default/security, I get a new error:
Proc [494] Connecting to ipyparallel cluster................
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-4-90007d89c179> in <module>
1 get_ipython().run_line_magic('load_ext', 'Ddip')
----> 2 get_ipython().run_line_magic('makedip', '-a fastai_v1 -g all --verbose True')
/opt/conda/lib/python3.6/site-packages/IPython/core/interactiveshell.py in run_line_magic(self, magic_name, line, _stack_depth)
2315 kwargs['local_ns'] = sys._getframe(stack_depth).f_locals
2316 with self.builtin_trap:
-> 2317 result = fn(*args, **kwargs)
2318 return result
2319
<decorator-gen-157> in makedip(self, line)
/opt/conda/lib/python3.6/site-packages/IPython/core/magic.py in <lambda>(f, *a, **k)
185 # but it's overkill for just that one bit of state.
186 def magic_deco(arg):
--> 187 call = lambda f, *a, **k: f(*a, **k)
188
189 if callable(arg):
/opt/conda/lib/python3.6/site-packages/Ddip/magics.py in makedip(self, line)
96 gpus = self.gpu_str2list(args.gpus)
97 self.ddp.exit_group() # Exit old DDP group if exists
---> 98 self.ddp.new_group(gpus=gpus, appname=args.appname)
99 self.shell.run_line_magic("pxconfig", "--verbose" if Config.Verbose else "--no-verbose")
100
/opt/conda/lib/python3.6/site-packages/Ddip/ddp.py in new_group(self, gpus, appname, node_rank, world_size)
203 if not self.cluster: self.init_cluster(n_engines=n_device)
204 cl = self.cluster # shorthand
--> 205 assert n_gpu <= len(cl.client), f"More GPU ({gpus}) than ipyparallel engines ({len(cl.client)}). "
206 assert max(gpus) < n_device, f"Invalid GPU id {max(gpus)}, highest allowed is {n_device-1}"
207
AssertionError: More GPU ([0, 1, 2, 3]) than ipyparallel engines (0).
Hello Greg, thanks for the debugging info.
! bizarre !
To debug, try launching the ipcluster without the --cluster-id option, then run the following script from another shell:
#!/usr/bin/env python3
import ipyparallel, os, IPython
t = 10
cid = None # or "foobar" to match "ipcluster start .... --cluster-id=foobar"
cl = ipyparallel.Client(timeout=t, cluster_id=cid)
print(f"ipyparallel {ipyparallel.__version__}, IPython {IPython.__version__}")
print(f"Connected to {len(cl)} engines. pids: {cl[:].apply_sync(os.getpid)}")
Play with t and cid to see if it’s a timing or other issue.
That works, but whenever I set a cid with ipcluster I get files with names like ipcontrolleripcontroller-test-client.json.
I have been running inside a docker container. Outside of the container I don’t have the issue. I’ll check versions and if necessary give up on docker.
It looks like the file naming issue is a bug in ipyparallel==6.2.5; pip install ipyparallel==6.2.2 solved that problem.
I filed an issue on ipyparallel: https://github.com/ipython/ipyparallel/issues/408
I see there’s a PR that appears to fix it: https://github.com/ipython/ipyparallel/pull/407
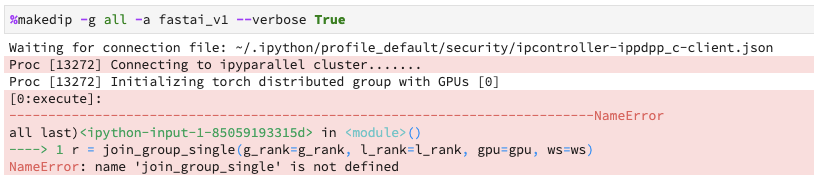
Hi Greg, sorry I haven’t had time to look at this yet.
join_group_single() should be imported on the fly as part of the initialization, I wonder if the python libraries are setup all well in the ipyparallel cluster/engine processes. But let’s take this discussion to the Ddip's github repo perhaps? Thanks for trying out my stuff 