I was going through the elmo paper . I came across this equation.
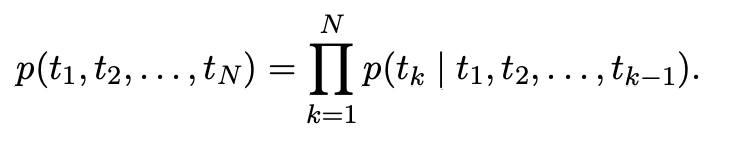
I’ve come across this equation in many papers. But I’m a little confused as to how this translates to python code. Has anyone done this
I was going through the elmo paper . I came across this equation.
I’ve come across this equation in many papers. But I’m a little confused as to how this translates to python code. Has anyone done this
I don’t know the exact equation that you are mentioning but this looks like right side of the equation is the product of conditional probability equations.
For the analogy, suppose that you know the probablity of the raining (let’s call it p1) when you know the clouds are black and temperature is below 20 C
Also you know the probability of the clouds are black (p2) when (given) it is raining and temperature is below 20 C
Finally the probablity of temperature is below 20 C (p3) given it is raining and clouds are black
Right side of the equation is p1 * p2 * p3 (for this example we have 3 p, but it can vary according to the problem)
For the python code part, if you are storing the values of corresponding p’s in , for example, a list you can iterate through it with for and multiply them
#l is the list containig the p values
prod = 1
for e in l:
prod = prod * eSo I read a little more on this. https://www.analyticsvidhya.com/blog/2019/08/comprehensive-guide-language-model-nlp-python-code/
This link was pretty helpful.
That probability equation is something referred to as the chain rule of probability which is basically joint probability of a sequence by using the conditional probability of a word given previous words. I guess language models were probably derived from here.
I’m only confused now as to how this translates to the softmax. So in a language model when we try to predict the next word do we take the log softmax of this one word with the sum of log probabilities of all the words in the corpus. Realistically that seems to be the way for me