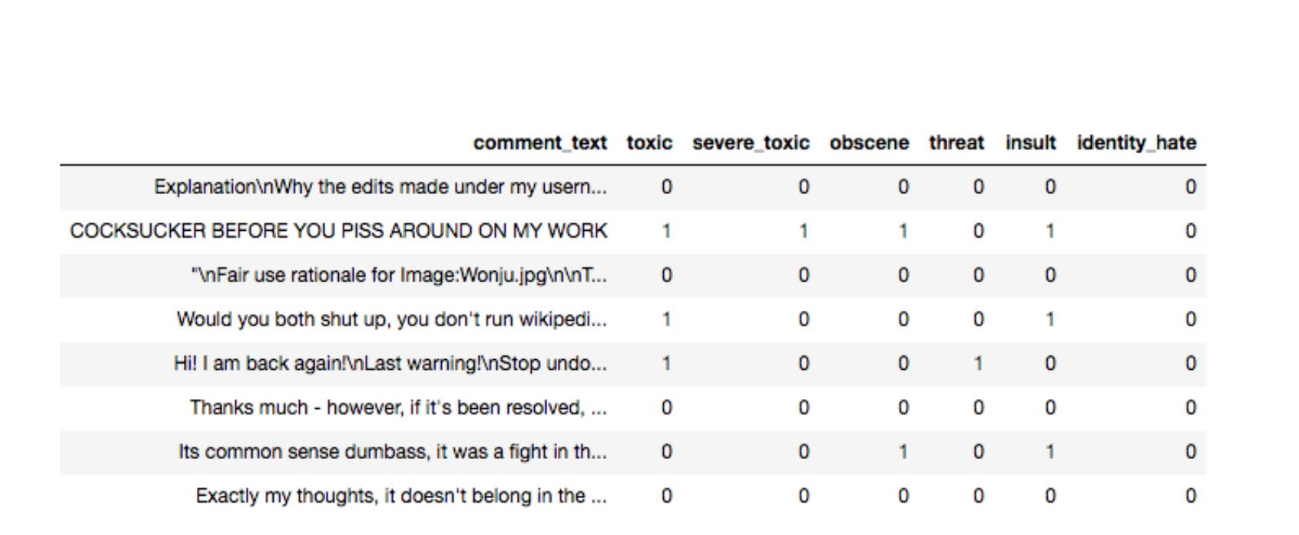
The current precision function in metrics.py return one number only, which is the average of all columns, however, I would rather it return a list as I want to see the precision of every columns instead of average. It would be great if someone can give me some suggestion or point me to the right class that I should change.
With the current model.metrics, I will have to create n precision function for n columns.
Thanks for your prompt response, I think for the prediction of bbox, it is a regression problem, and it make sense to look at average loss as individual coordinate have equal importance.
In particular, I was trying to do multi-label classification. Although the evaluation metrics is average AUC of 6 columns, there are need to monitor individual columns.
it is a imbalance dataset, certain label has much more example/ less example (thus the task for making classification for each column has different difficulty. Only monitor the average loss may loss the chance to exploit the model that maybe good at classified a particular column.
Consider an extreme case, if i have 2 models.
1 model has accuracy [ 99.9%,99.9%,99.9%,90%,90%,90%], the other has [ 90%,90%,90%,99.9%,99.9%,99.9%]. The obvious thing to do is ensemble 2 model, which I which never know if I only monitor the average.
Sure, but bbox numbers also have to be compared against each of the target box coordinates. If you use a list of predictions to compare to a Y list, simply checking for equality along the 1 axis while taking the mean should give you accuracy for each element in the list. Agree?
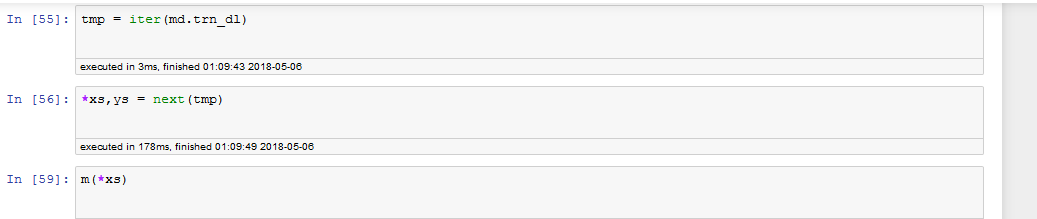
Actually, I was struggle to pass a batch to the model too. For the previous model, usually I can just do m(VV(xs)) to get a sample of output. However, for the language model classifier, I was getting self.hidden attribute does not exist when I do so. (this is another problem though, which makes debugging not easy as well.
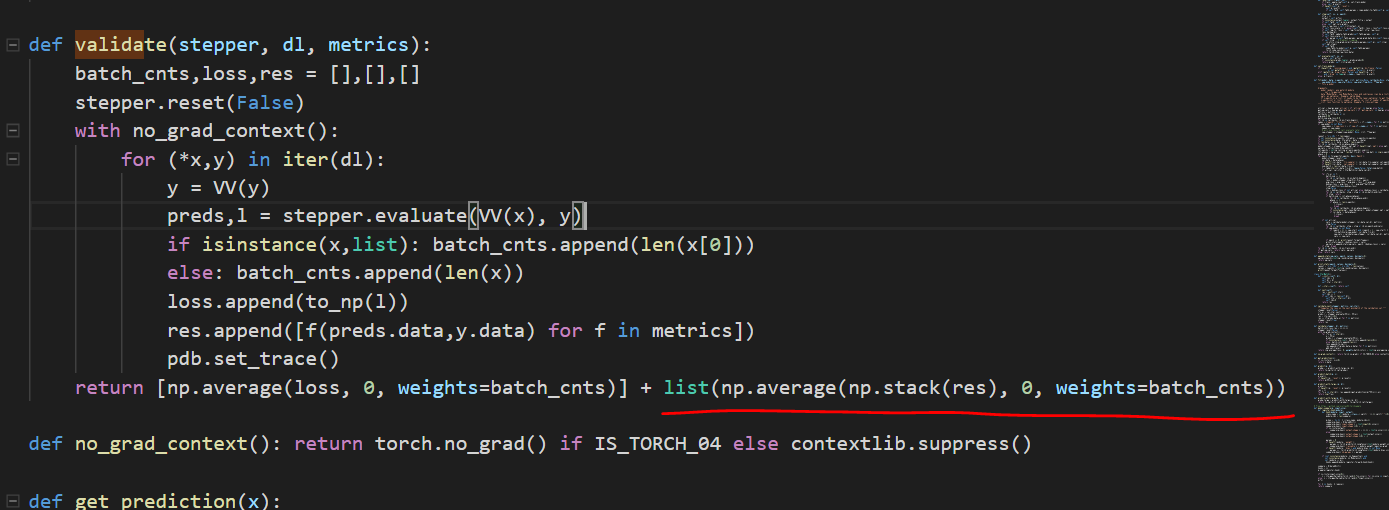
I try to read through the source code, I think the reason why it does not work as it use a np.stack, which expect a list only. If i return a list with a custom metric, it become list of mix of elements and list, and thus doesn’t work. My instance just hang and I cannot get into it.
I had a similar problem when passing 2 lists as input to the model where the lists could have different lengths. np.stack will complain about the sizes.
so, i wrote a custom metric but didn’t run it as part of the eval at the end of each epoch. I was manually taking the preds and calculating accuracy separately.
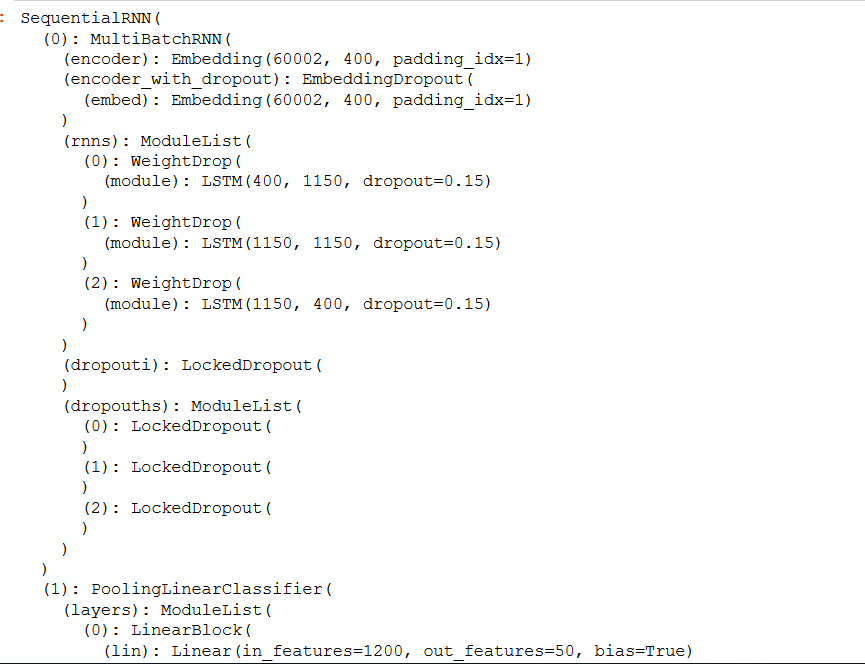
Could you guide me how to save the output? I actually struggle to change the model structure, as the Language model class is not as straight forward, which have multiple funciton call and use a sequentialRNN.
I want to change the output to sigmoid layer (As required by binary cross entropy), but I cannot find where I should modify the code, as a result. I actually tweak the crit directly, I use a custom_loss function, to add a sigmoid layer in the end. It would be much easier
In this case you define the model your self. How could I add a layer on top of the current model? I use the default get_cnn_classifier model, which return a SequentialRNN.
I would like to do 2 things.
add sigmoid layer at the end( I test the nn.functional.binary_cross_entropy_with_logits, which does not take a sigmoid for you, it is expecting a log(sigmoid) - log(1-sigmoid) instead)
tweak the model output so that I can actually save the prediction and thus do whatever metric i want outside the fit function.
the sequential RNN returns an output which is a list of 3 things.
[0] the o/p of the classifier module
[1] the o/p of the backbone with dropouts applied
[2] the o/p of backbone minus the dropouts.
You can take [1] or [2] and pass it to your module if you wish.
Also, remember…if you want to write your custom logistic loss crit and you don’t have a squashing fn like sigmoid, you need to clamp(clip in numpy) the values or the log will blow up.
Could you point me to the source code where you find these? I was trying to see what the output is but I don’t know where I should read.
the sequential RNN returns an output which is a list of 3 things.
[0] the o/p of the classifier module
[1] the o/p of the backbone with dropouts applied
[2] the o/p of backbone minus the dropouts.
Ah, I see it now. Thanks, really appreciate your help. My last question is how do I pass a sample to the model for evaluation? the usual way seems not working.