So this question is a little immature since I haven’t done much research, nor looked at how Jeremy goes on about it, so sorry about it, but I wanted to get people’s opinions anyways.
As referenced here, PyTorch seems like it converts image arrays (pixel values in range [0-255]) to a normalized value between [0,1]. The doc doesn’t really say how this is done. This is quite counter-intuitive to me. I’d have thought that “Batch Normalization” layers were precisely made to address this issue (i.e. normalize input values using a batch mean and variance). Also, after PyTorch normalizes these values, does it make sense to use popular pretrained networks and weights, where you’re supposed to subtract a provided RGB mean value?
There’s no particular standard - in our case this is handled inside fastai.transforms, so you can look at the code there. The default transforms are at the bottom of that file.
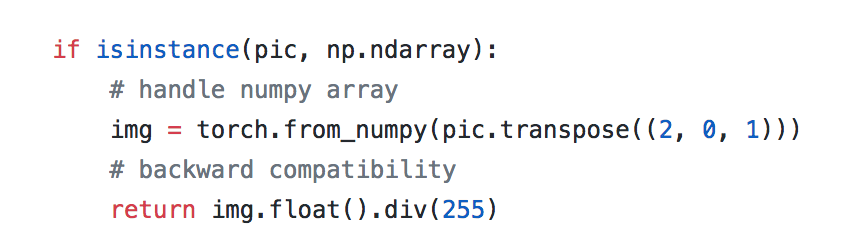
Okay… so I finally had the chance to look at the source code: both at how we normalize the pixels in the fastai library, and how torchvision.transforms.ToTensor(…) does it.
In both the cases, the pixel values are divided by 255. See attached images:
And this blows my mind… because, Keras or Tensorflow did not endorse that, while just every PyTorch examples show the usage of this transformation. More theoretically, I thought the best data was the one that was centered around 0 and had a variance of 1. For that, batch_norm layers subtract by the mean and divide by the variance. Even during fine-tuning on VGG, I know instructions abound on subtracting (your) training data by the mean RGB values of the imagenet.
What are the effects of just dividing by 255? Is it really the same, because we are simply linearly scaling the pixel values? Or would there be other implications…
I appreciate, in advance, anybody’s feedback to this question.