I’m not sure if this is a problem with just BERT or if it’s a problem with all transformer based architectures … but it seems like they would fail in token level classification tasks where there are inputs greater than the max_len setting would allow.
Is this a problem with all the transformer base models (e.g., BERT, XLM, XLNet, RoBERTa, etc…)?
Is there a way to overcome this, what seems to me a problem at least, when using BERT for such tasks?
I am new to fastai forums, so forgive me if my understanding of your question is off-base, but if you are referring to in general the training of BERT-like models on sequences of greater than 512 in length (not just specifically an issue around token level classification tasks), then from my understanding it is not possible.
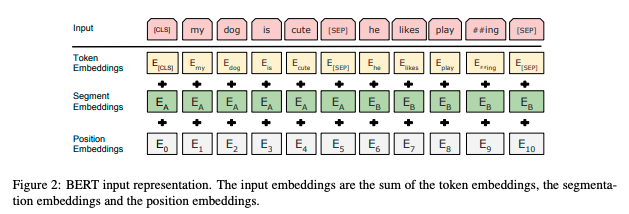
This is because, as noted in the original BERT paper, each input embedding is the summation of a position embedding + segment embedding + token embedding, with these position embeddings capped at 512.
If you need to train longer sequences, you can use the Longformer. Quoting huggingface quoting the paper:
"Transformer-based models are unable to process long sequences due to their self-attention operation, which scales quadratically with the sequence length. To address this limitation, we introduce the Longformer with an attention mechanism that scales linearly with sequence length, making it easy to process documents of thousands of tokens or longer."
I stumbled upon this question because I am also interested in token-level classification (with any type of model, not just BERT) using fastai. Is there already way to do so using fastai library?
[edit, just realizing you posted this Sept 2019, not Sept 19th…
we can solve this by creating overlapping datapoints (sequence of tokens) where (n+1)th datapoint has starting few tokens same as (n)th datapoint’s last few tokens. Eg: fix max_len = 256, if ur sequence has length of 300 then create 2 datapoints, first one from [0:256] and second one from [256-x : 300] here x is user defined.