Hi All,
The paper below is the approach from the winner of the ICIAR 2018 contest. The dataset consists of two components, (1) Individual Slides of tissues categorized into 4 classes and (2) Wholeslide Images of the tissue with segmented classes.
The author seemed to have created a multilabel classifier from the first dataset, and then used the second dataset as a leak. That is for the each whole slide image, he split into multiple blocks of definite size (say 224x224). He had extracted the pixel value of the mask for each of the patch and computed the average class of a patch by assigning (0= class a, 1= class b and so on).
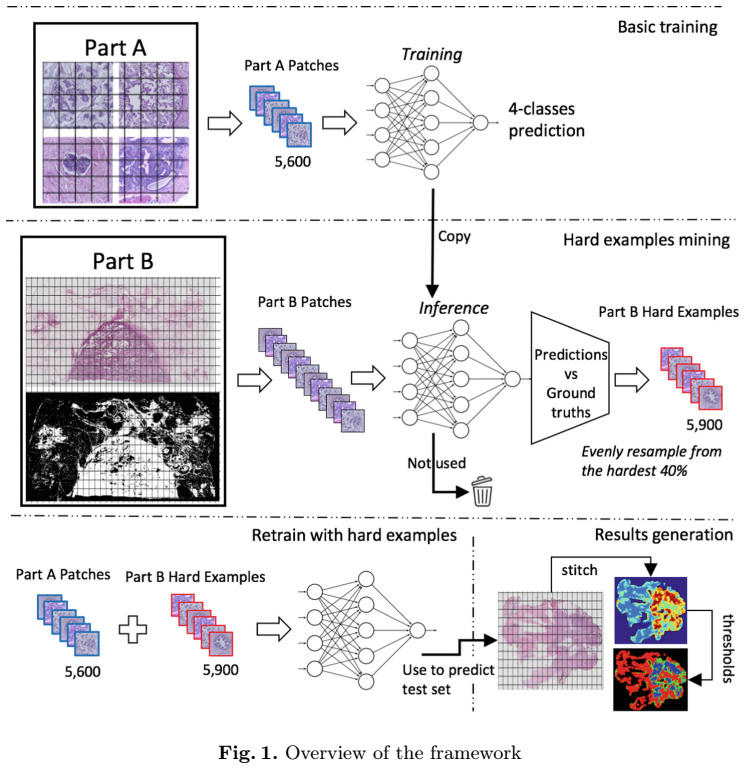
Once the predictions are made on the individual patches from dataset (2) he stitches the predictions back into original Wholeslide image dimension and creates a heatmap for the classification.
What I understand is by doing this way he has reduced the segmentation problem to a classification problem.
Has anyone else tried a similar approach? Will this approach be better to determine the masks for large scale images like histopathology slides? (In comparison to camvid lesson - part 1 v3 or dynamic Unet from part 2 advanced) Any pointers will be helpful.
Thanks.