I’m having problems with applying rf model to some tabular data, this is histogram of target variable:
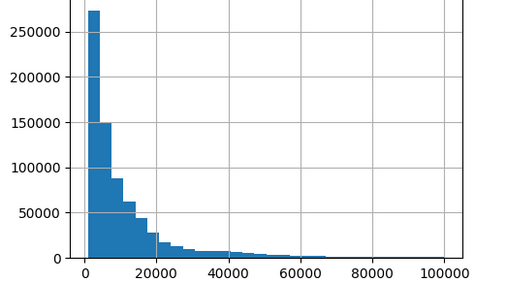
Tried to combine over with under sampling, but that lead to the lower accuracy.
Any ideas how to improve accuracy?
Not sure if it’s standard practice—but what if you tried applying log to the target variable and then using that during training?
Thanks, will try and let know!
1 Like