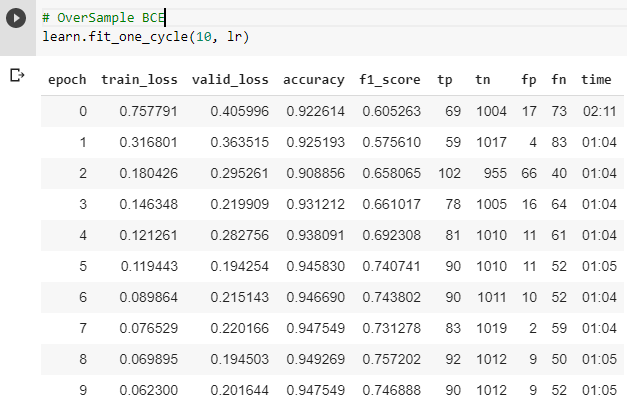
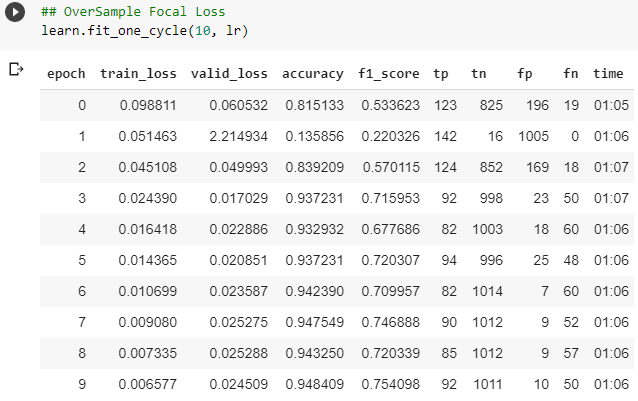
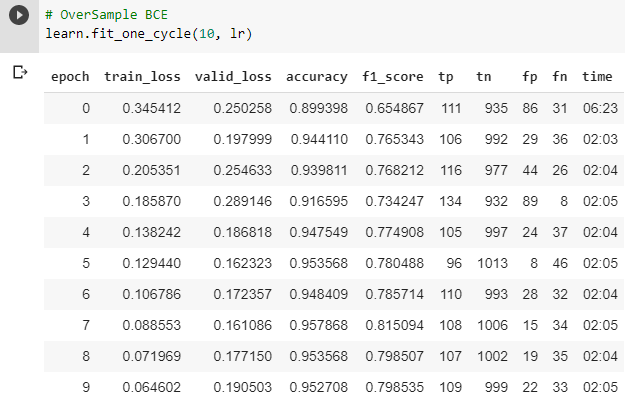
I am working with a strongly imbalanced data where the real output is 98% category A and 2% of the time category B. I have a large dataset (20 million rows) for this classification problem. I am thinking of using oversampling for training but as detecting both classes right is very important, I fail to see which loss and metric might turn out to be most useful.
I am thinking of using Matthews correlation coefficient (MCC) as a metric and I don’t know if there is a loss that might be some kind of proxy to this metric or any other similar metric (F1 score, etc).
Would you mind sharing what you think might work well?
I would try Focal Loss and oversampling as you mentioned. But I would start with the default approach without oversampling and the default loss just to have a baseline for comparison.
Then you can look where the model fails and that may give some ideas for improving those cases.
class FocalLoss(nn.Module):
def __init__(self, gamma=2):
super().__init__()
self.gamma = gamma
def forward(self, logit, target):
target = target.float()
max_val = (-logit).clamp(min=0)
loss = logit - logit * target + max_val + \
((-max_val).exp() + (-logit - max_val).exp()).log()
invprobs = F.logsigmoid(-logit * (target * 2.0 - 1.0))
loss = (invprobs * self.gamma).exp() * loss
if len(loss.size())==2:
loss = loss.sum(dim=1)
return loss.mean()
For oversampling I think the easiest way is, if you are using a dataframe, duplicate the rows corresponding to rare classes until the classes are balanced. A more memory efficient strategy would be to create a costume sampler that creates mini-batches with equal number of samples per class. The latter strategy requires however more coding and a good understanding of fastai datablock api.
Thanks… Why aren’t these already implemented in fastai?
So I specify the loss function with learn.loss_fn = FocalLoss(), right?
Also, if one is dealing with imbalanced data, should we use both Focal Loss and Oversampling or both?
You should investigate undersampling and smote as well as oversampling. Looking at anomaly detection might be useful as well depending on how your data is distributed.
For anyone who is having the same problem, here is what I did:
I found this great article that showcases a python library for just tackling animbalanced dataset called: imbalanced-learn Python library.
and It works wonders!
portion of the code implementing this library for oversampling the rare classes (I have only one) :
!sudo pip install imbalanced-learn
#check version number
import imblearn
print(imblearn.__version__)
from imblearn.over_sampling import RandomOverSampler
oversample = RandomOverSampler(sampling_strategy='minority')
XA_over, yA_over = oversample.fit_resample(df_A.iloc[:,0:10],df_A.iloc[:,10])
df_A_over = pd.DataFrame(data=np.column_stack((XA_over,yA_over)),columns=df_A.columns)
If the data within the 98% is reasonably consistent you could save yourself a lot of time and effort by just training on 1% of each class. Why bother training it on 20 million rows?
I didn’t really see things improve much, though. I’m exploring the library more to see other sampling techniques they have like SMOTE. Presently, just did RandomOverSampler.
Original counts: Negative 4898 Positive 499 Name: label, dtype: int64
I don’t know how you have your dataset set up, but I will note you shouldn’t oversample your validation set, and you should be using a metric good for imbalanced data, like AUC. The weighted dataloaders should only be oversampling the train set, but I don’t know what setup you have here.
I was doing it through the dataframe using the lib that @remapears posted above.
I have yet to do the weightedDL.
You’re right, I oversampled the valid set too, I fixed that, and I’m seeing much different results. At least, the FNs have moved a little bit, at the cost of FPs now. It is also overfitting.