Hi all,
After doing the first few fast.ai lessons and trying out some mask detector tutorials online, I decided to build a detector for whether medical gloves completely cover the sleeve of a medical gown.
Source
Colab Notebook: https://colab.research.google.com/drive/1BQMtg4FWED5aO04rfMdJ80wrjFxMKbTf?usp=sharing
Google drive data (images and model weights):
https://drive.google.com/drive/folders/1NRinqNLkGXqQ8latixzN9IuMsy_CwWoq?usp=sharing
While the model trains to a ~90% accuracy, it doesn’t perform as well on test sets (as seen in the colab)
Question: How important is it that training images are unique/diverse?
The way that I have collected data for now is by generating it myself (can’t think of a way to scrape the data from online). I have a python/opencv program running my webcam to capture myself wearing the gown and glove, then pose detection to crop to where the glove meets the sleeve. It captures every consecutive frame (~20fps) so does the fact that there isn’t massive variation between the images pose an issue? If you look in the gdrive, I do try to vary the position of the glove and gown. eg pulling the sleeve further up.
I’ve deliberately collected similar images because I found that the test sets, which were similar in background and lighting were performing poorly. I assumed that if I collected more data with a plain background and yellow-ish lighting, I would have more data to better predict for the test set. Is this assumption wrong? Would it be better to make each picture truly unique eg. having a different background (perhaps swapping out the background virtually with photoshop?). for the model to better generalise?
Valid

Invalid
Also, I know all these images have a yellow color cast (been working on this in my spare time during the evenings). The next set of data, I’ll try better lighting conditions to see if it helps.
I also note that my training cycles metrics seem to be weird. Especially because accuracy hits 1.When the valid_loss increases at epoch 7, is that a sign of overfitting?
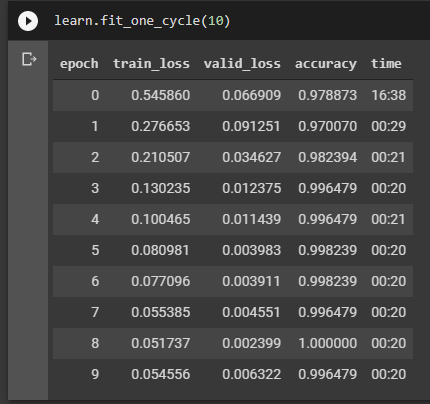
If you could give some guidance, that’ll be much appreciated.