Lesson 7 also looks complete. I don’t see any more italics. ![]()
3 Likes
Thank you @nikem, @fmussari, @wyquek, @bencoman, and @gagan for you hard work on lesson 7!
Alright everybody, last one! Here’s the draft transcript of lesson 8:
2 Likes
Hi, Lesson 8 is complete. Would be great If someone could do a final skim through.
2 Likes
I’ll do it. This will be my first viewing. (I’ve been focussed on finishing my RTTT Part 4 Paddy submission.)
Review complete. Lesson 8 ready to upload.
2 Likes
Sounds like this one could be a great help for transcripts in the future sessions.
1 Like
Congratulations everybody – all the videos now have complete transcripts! ![]()
2 Likes
You are welcome, but it was mostly @fmussari - awesome work btw.
My final proof-read would be 20% of his original effort.
2 Likes
Yeah lemme give a big shout-out to @fmussari who’s been working incredibly hard throughout this course – thank you so much!
3 Likes
My pleasure. Thanks to you and your devotion to teach and code. And to all the helpful people in this forum.
Can’t wait to start transcribing Part 2! ![]()
2 Likes
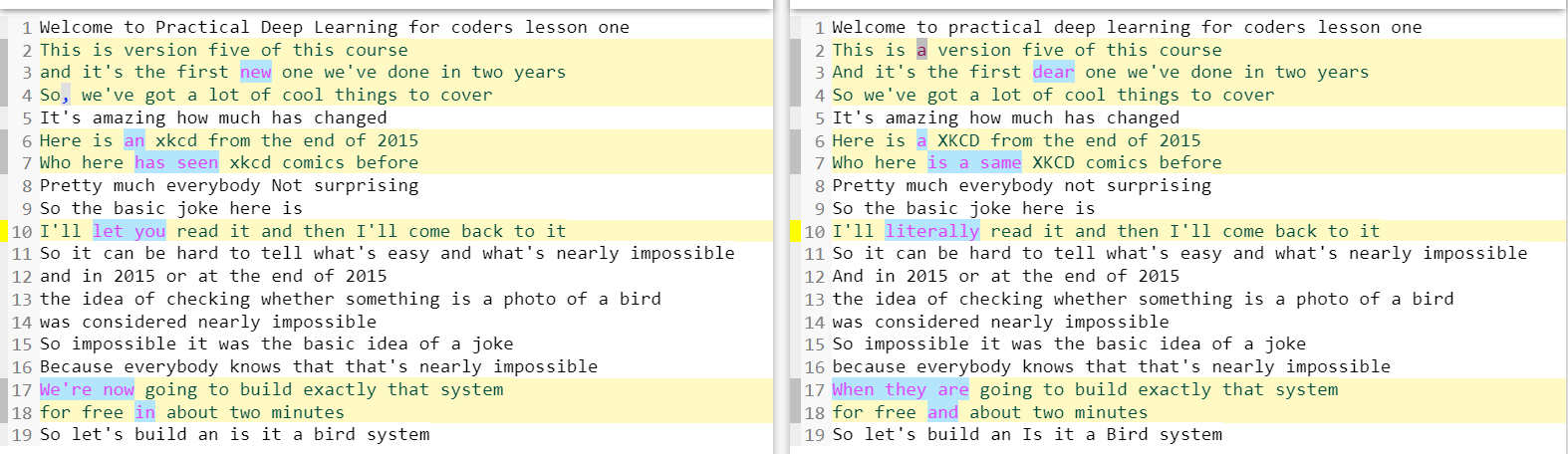
Btw, regarding automated transcription, it seems that Whisper does a great job here. I tried to download the audio and here is an example of what was recognized, a small excerpt:
Welcome to practical deep learning for coders lesson one.
This is a version five of this course.
And it's the first dear one we've done in two years.
So we've got a lot of cool things to cover.
It's amazing how much has changed.
Here is a XKCD from the end of 2015.
Who here is a same XKCD comics before?
Pretty much everybody, not surprising.
So the basic joke here is,
I'll literally read it and then I'll come back to it.
So it can be hard to tell what's easy and what's nearly impossible.
And in 2015 or at the end of 2015,
the idea of checking whether something is a photo of a bird
was considered nearly impossible.
So impossible, it was the basic idea of a joke
because everybody knows that that's nearly impossible.
When they are going to build exactly that system
for free and about two minutes.
So let's build an Is it a Bird system?
Compared to what was done by community members (edited a bit to split into separate lines):
Welcome to Practical Deep Learning for coders, lesson one.
This is version five of this course,
and it's the first new one we've done in two years.
So, we've got a lot of cool things to cover!
It's amazing how much has changed.
Here is an xkcd from the end of 2015.
Who here has seen xkcd comics before? …
Pretty much everybody. Not surprising.
So the basic joke here is…
I'll let you read it, and then I'll come back to it.
So, it can be hard to tell what's easy and what's nearly impossible,
and in 2015 or at the end of 2015
the idea of checking whether something is a photo of a bird
was considered nearly impossible.
So impossible, it was the basic idea of a joke.
Because everybody knows that that's nearly impossible.
We're now going to build exactly that system
for free in about two minutes!
So, let's build an “is it a bird” system.
Sure enough, there are some differences, like missing quotes or different punctuation/capitalization. But content-wise, looks amazing.
I would run it on the whole course and compare to what is done by @bencoman and @fmussari if that’s ok? Would be interesting to look at the difference.
P.S. feels like one less topic for jokes about nearly impossible things in coding.
3 Likes
There are a few online diff checkers that provide a nice visual. This one from https://www.diffnow.com/
Jeremy wanted a highly accurate transcription particularly to aid non-native english speakers. Excluding puncuation (which does aid comprehension) I count four errors from Whisper that impact comprehension. This is a 2.5% error rate, which at 140 words/min is 1 error per minute, which would be annoying. So a human is still needed in the loop.
The Whisper error rate looks about the same as the built-in Google translate. It would be interesting to compare Whisper that to, and also whether the errors can be fed back into tuning Whisper to these particular videos.
3 Likes
If anyone is interested in a fun project, maybe try fine-tuning the whisper model using all my course videos I’ve done since 2017. I dunno how hard/easy it is to fine-tune the model or what resources are required… I suspect a fine-tuned version would work quite a bit better.
2 Likes
Yes, that’s a good point. It is definitely not perfect.
But fine tuning the model should be indeed helpful. Also, I did the transcript using tiny.en model which is the smallest one. I would also try other.
I’ll keep looking into this, maybe it is possible to run it on a custom dataset. Also, I guess it is a good candidate to be included into transformers hub. (If it is not there yet?)
2 Likes
Btw, I downloaded all available recordings from the channel and applied Whisper models of different sizes to get some baseline performance results. Next step would be to actually try fine-tuning the model. One interesting observation is what Jeremy (re)twitted (if I am not mistaken, don’t remember the exact tweet) is how it collapsed on some examples:
And I think that's a lot of different types of different types of
different types of different types of [...] APL things, what does mean to
boxes and so on. And so, and so, and so, and so, [...]
I guess this performance deterioration is the most problematic result for applying the model “out of the box.” Hopefully, I’ll manage to fine-tune it quickly and see if results improve.
2 Likes
Ok, fine-tuning Whisper requires some work. As the repo doesn’t include training branch, but only the inference part. In principle, one needs to prepare the input in the right format (audio fragments plus tokenized descriptions), and also come up with the loss function.
Meanwhile, I tried using bigger variants of it and the results are rather weak. Of course, it could be that I have some bug in my snippet that extracts the audio and captures from the videos. But at the moment, the idea of easy to use, out of the box transcription tool didn’t work out for me. (FYI, here is the code to download and transcribe lectures.)
When I computed WER scores (similar to how it is done in the Whisper’s example), I got this:
WER (tiny.en): 26.24%
WER (base.en): 25.19%
WER (small.en): 15.50%
WER (medium.en): 18.13%
Not what I expected ![]()
There is a file with reference captions done manually and texts produced by different sizes of the models. Again, could be some bug in the implementation. But anyway, I’ll take a closer look to understand why it doesn’t work as expected. Maybe the recordings are too long, and it seems that the model collapses somewhere in the middle, as the previous message shows.
2 Likes