I read the SAGAN paper and tried to implement the self-attention module. However, the implementation that I saw in the fastai repo is a bit different from the one proposed in the paper. Concretely, the fastai implementation does not have the 1x1 convolution that is circled in red in the picture below.
I would want to know why that convolution has been taken out.
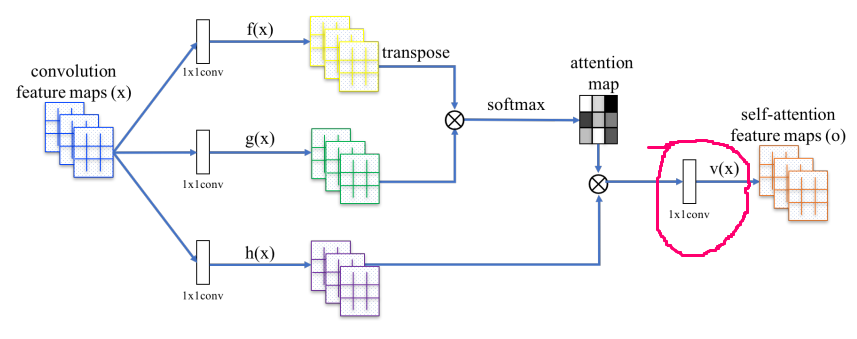
The fastai implementation can be found here.