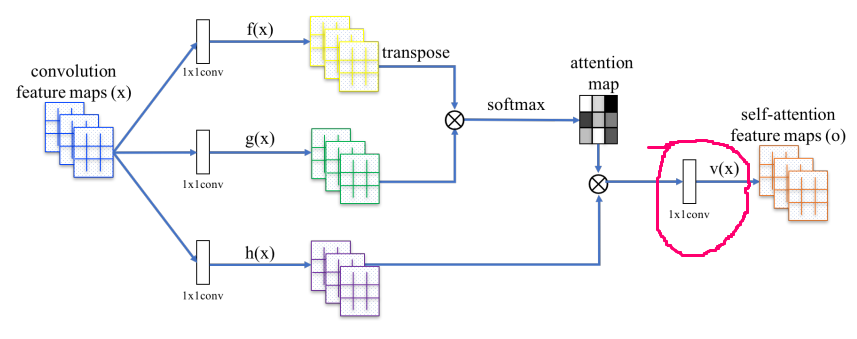
I read the SAGAN paper and tried to implement the self-attention module. However, the implementation that I saw in the fastai repo is a bit different from the one proposed in the paper. Concretely, the fastai implementation does not have the 1x1 convolution that is circled in red in the picture below.
I would want to know why that convolution has been taken out.
I’m not sure why it’s not present in the fastai implementation. Have you tried running some experiments with and without it? Do you think it’s doing meaningful computation? I think comparing results with and without might help build some intuition as to why that’s the case here (as I highly doubt it’s accidental).
@kofi@orendar the current implementation is based off the work of Jason Antic. I discussed with him today and here’s the basic TL;DR:
His implementation is based on the SAGAN paper. Later in the BigGAN paper they said SAGAN did it wrong. So the correct implementation to do so in fastai is to look at the PooledSelfAttention2d.
I’m going to run a few experiments today and see how it compares on ImageWoof, though I would expect a boost in accuracy
To add on a bit: the only place we use the “broken” SA is in the DynamicUnet. Otherwise we use Seb’s SimpleSelfAttention (in xresnet). While it should be a simple drop-in replacement from SelfAttention -> PooledSelfAttention2d, it doesn’t seem to quite be the case