And when i unfreeze and try to fit using new learning rate from the curve the result is still the same
This keeps happening no matter how many times i run from start with my dataset . Despite the training_loss being grater than the valid_loss the model has predicted accurately with 99% confidence when tested with completely new images not included in the dataset.
It would be great if someone could explain me where i’m going wrongand how to fix it considering that i’m actually missing something.
Maybe you have not many validation samples? You could also try different architectures and see, how they behave (resnet9 or resnet34 e.g.). Without more information hard to help you.
I have tried with resnet34 and resnet18 but there was no difference. Haven’t tried resnet9. Will do it and check. I had around 35 images per class, all in one folder and used from_name_re method of ImageDataBunch to load them. As far as i remember that method creates train and validation sets itself and so i didn’t mention any validation set.
P.S: I forgot to mention that my dataset is very different from the dataset used to pre-train the resnet model.
my dataset consists of two different types of IDs used in our organization.
If it’s classifying new images correctly, then it sounds like things are working. Even though the training loss “should” be lower than the validation loss, it seems pretty common for the reverse to be the case.
I think @tank13 has made a point: If the validation set is very small it can happen that the model actually classifies it with smaller loss than the training set (e.g. because “easy” examples all ended up in validation set, while all the “hard” ones ended up in the training set). Did you try varying the split size?
you may be right. I will try again with a bigger validation set andcheck.Also after digging the forums for a while a found another post where a guy was having a similar problem.
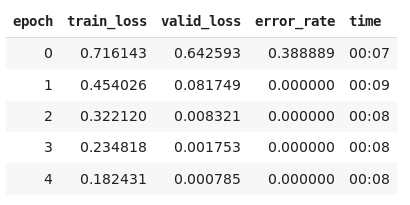
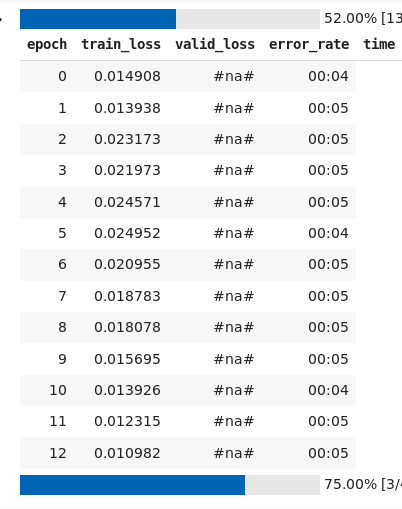
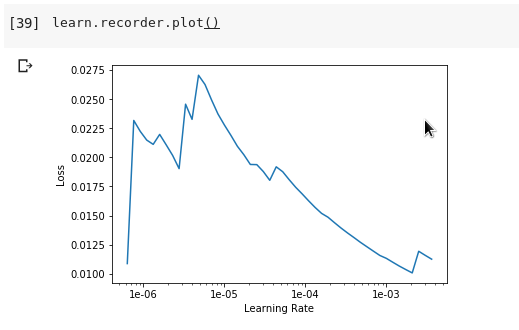

 Even though the training loss “should” be lower than the validation loss, it seems pretty common for the reverse to be the case.
Even though the training loss “should” be lower than the validation loss, it seems pretty common for the reverse to be the case.