Hello all. I am currently attempting the Recognizing Faces in the Wild challenge on Kaggle. The task is to determine if two people are blood-related based solely on images of their faces.
The labels look like:\
F0002/MID1 and F0002/MID3 mean that In Family F0002, MID1 is related to MID3 (the first row in the above figure).
More information about the dataset:
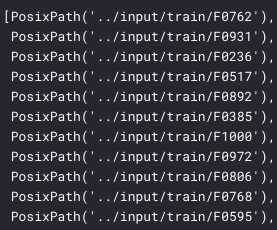
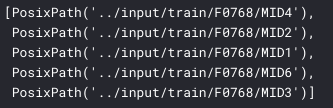
the training set is divided in Families ( F0123 ), then individuals ( MIDx ). Images in the same MIDx folder belong to the same person. Images in the same F0123 folder belong to the same family.
The training images are contained in a folder which contains images from 470 families and its structure looks like (a small snap):
Now if you zoom into a folder of a particular family, you get:
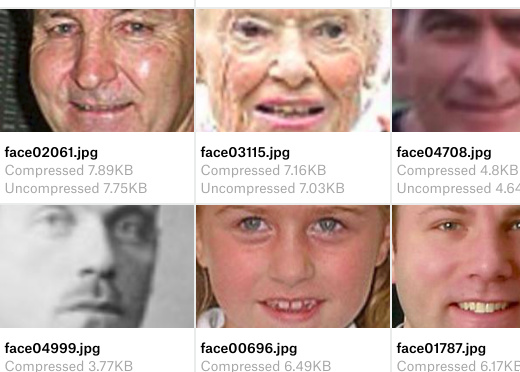
Given all this data, you are to build a system that would take image-pairs as given in the test set and will predict if they are blood-related or not, The images from the test set look like:
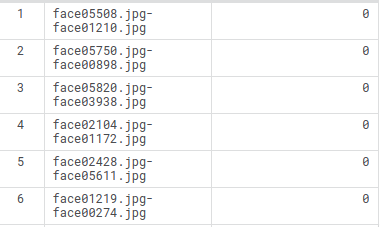
The prediction file contains image-pairs like:
And accordingly, we have to predict if they are related.
On this problem statement, I am struggling to understand how do I make the data bunch to feed that to a model. Any clue and pointers would really be helpful.
Thank you very much for your suggestion. I had constructed the dataset initially (basically an Image -> Image mapping) from the .csv file. Here’s the Kaggle Kernel of that: https://www.kaggle.com/spsayakpaul/data-exploration-recognising-faces-in-the-wild. After that, I could not figure out how should I proceed. You will see a Unet in the kernel though, but it was kind of a no-brainer.