Update 1
I updated my data set to have balanced images in birds and others folders.
Now the dataset folder structure is:
- minidata
- train
- birds
- others
- validation
- birds
- others
- train
I also removed the valid_pct = 0.2 in favour of using folder structures,
data = ImageDataBunch.from_folder(path=path_img, train=train_folder, valid=valid_folder,.....)
so you can see that when picking up images, birds and others have a good mix:
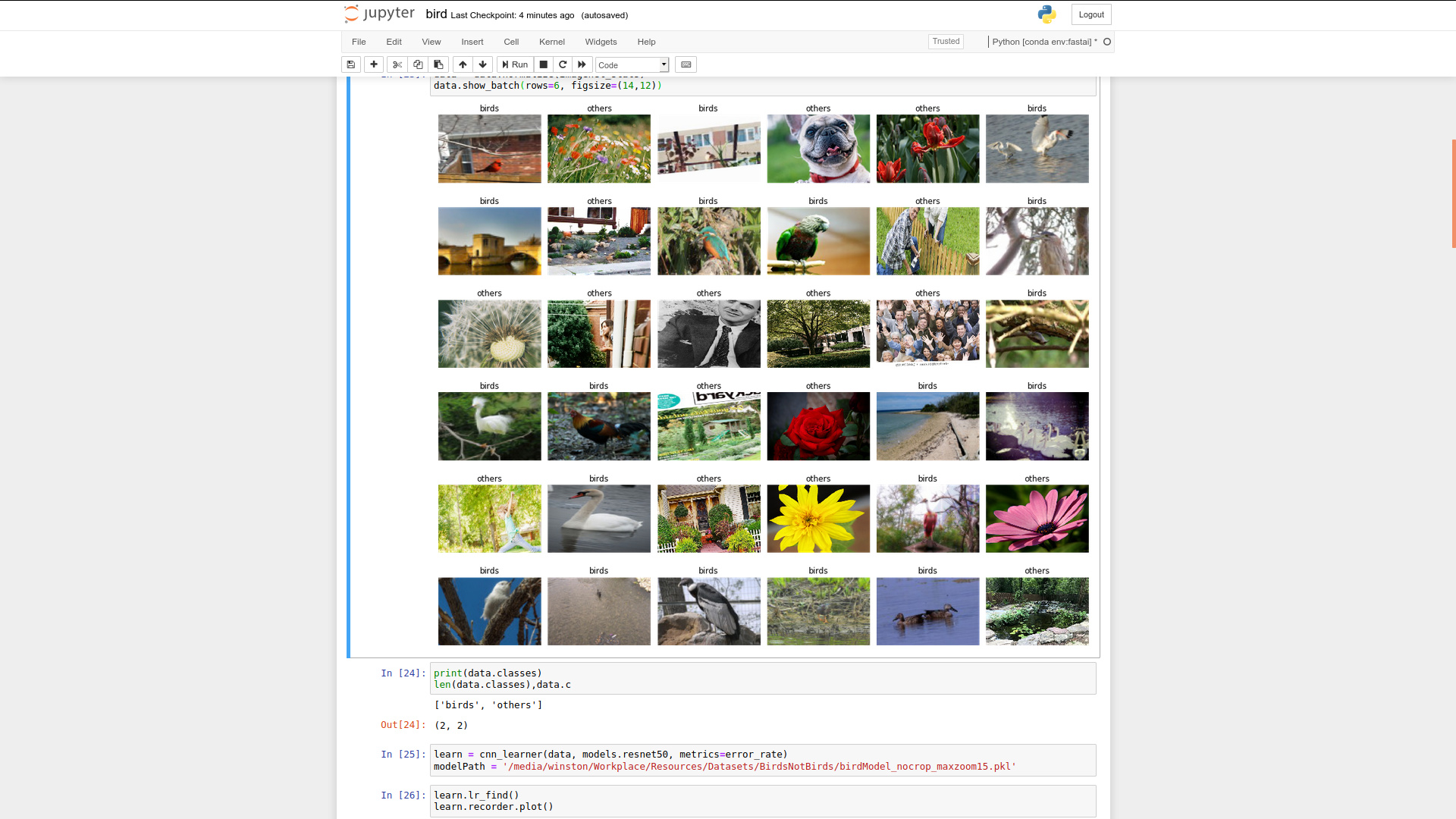
however, the train_loss and valid_loss are still becoming worse and worse.
I use lr_find() to find the best lr and applied:
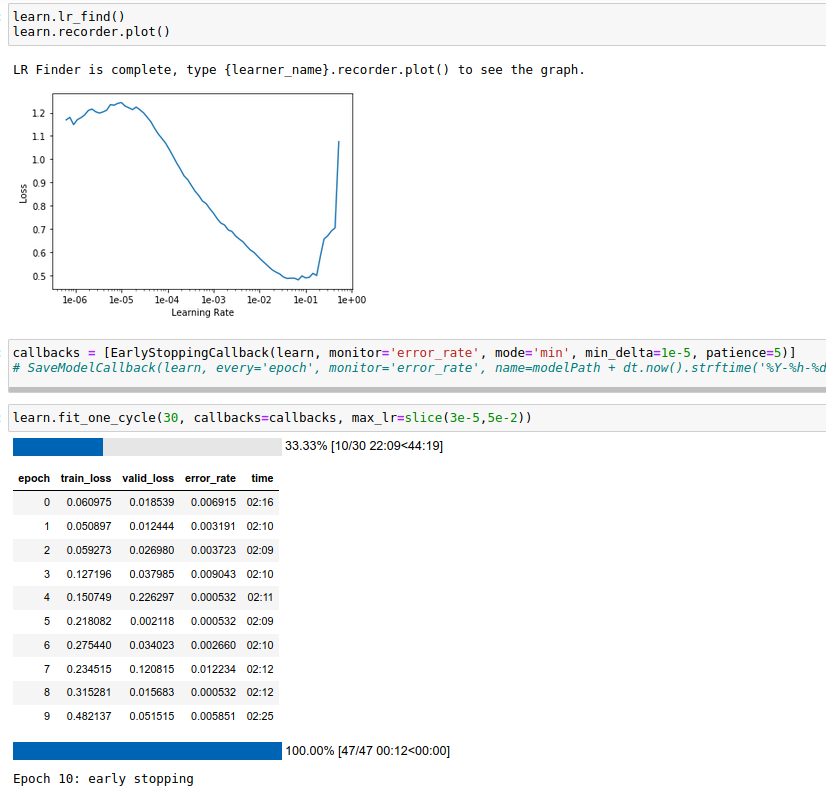
Unfortunately, the train_loss and valid_loss are decreasing
Here is my code:
from fastai.vision import *
from fastai.metrics import error_rate
from fastai.callbacks import EarlyStoppingCallback,SaveModelCallback
from datetime import datetime as dt
from functools import partial
path_img = '/path to Datasets/BirdsNotBirds/minidata'
train_folder = 'train'
valid_folder = 'validation'
tunedTransform = partial(get_transforms, max_zoom=1.5, )
data = ImageDataBunch.from_folder(path=path_img, train=train_folder, valid=valid_folder, ds_tfms=tunedTransform(),
size=(299, 450), bs=40, classes=['birds', 'others'],
resize_method=ResizeMethod.SQUISH)
data = data.normalize(imagenet_stats)
data.show_batch(rows=6, figsize=(14,12))
learn = cnn_learner(data, models.resnet50, metrics=error_rate)
learn.lr_find()
learn.recorder.plot()
callbacks = [EarlyStoppingCallback(learn, monitor='error_rate', mode='min', min_delta=1e-5, patience=5)]
learn.fit_one_cycle(30, callbacks=callbacks, max_lr=slice(3e-5,5e-2))
Please help.
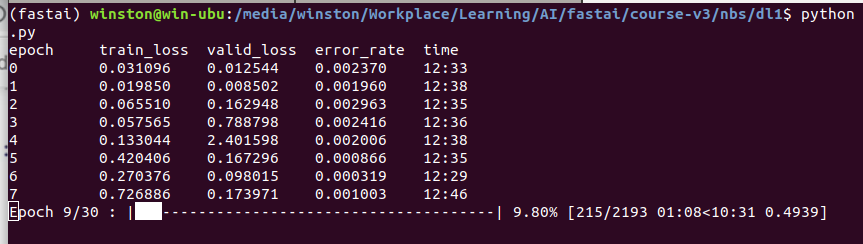
I have 2 classes: birds(100K images) and others(7K images)
folder structure:
- data
- birds (100K images)
- others (7K images)
data = ImageDataBunch.from_folder(path=path_img, bs=40, valid_pct= 0.2, ds_tfms=get_transforms(), size=(299, 450), classes=['birds', 'others'], resize_method=ResizeMethod.SQUISH)
data = data.normalize(imagenet_stats)
learn = cnn_learner(data, models.resnet50, metrics=error_rate)
callbacks = [EarlyStoppingCallback(learn, monitor='error_rate', min_delta=1e-5, patience=5)]
learn.fit_one_cycle(30, callbacks=callbacks, max_lr=slice(1e-5,8e-2))
According to the Lesson 2, @jeremy 's advice:
if train_loss > valid_loss it means: learning rate is too high or too few epochs
Then I adjusted my LR several times, still I am facing this issue: train_loss is getting worse.
Please help~!
