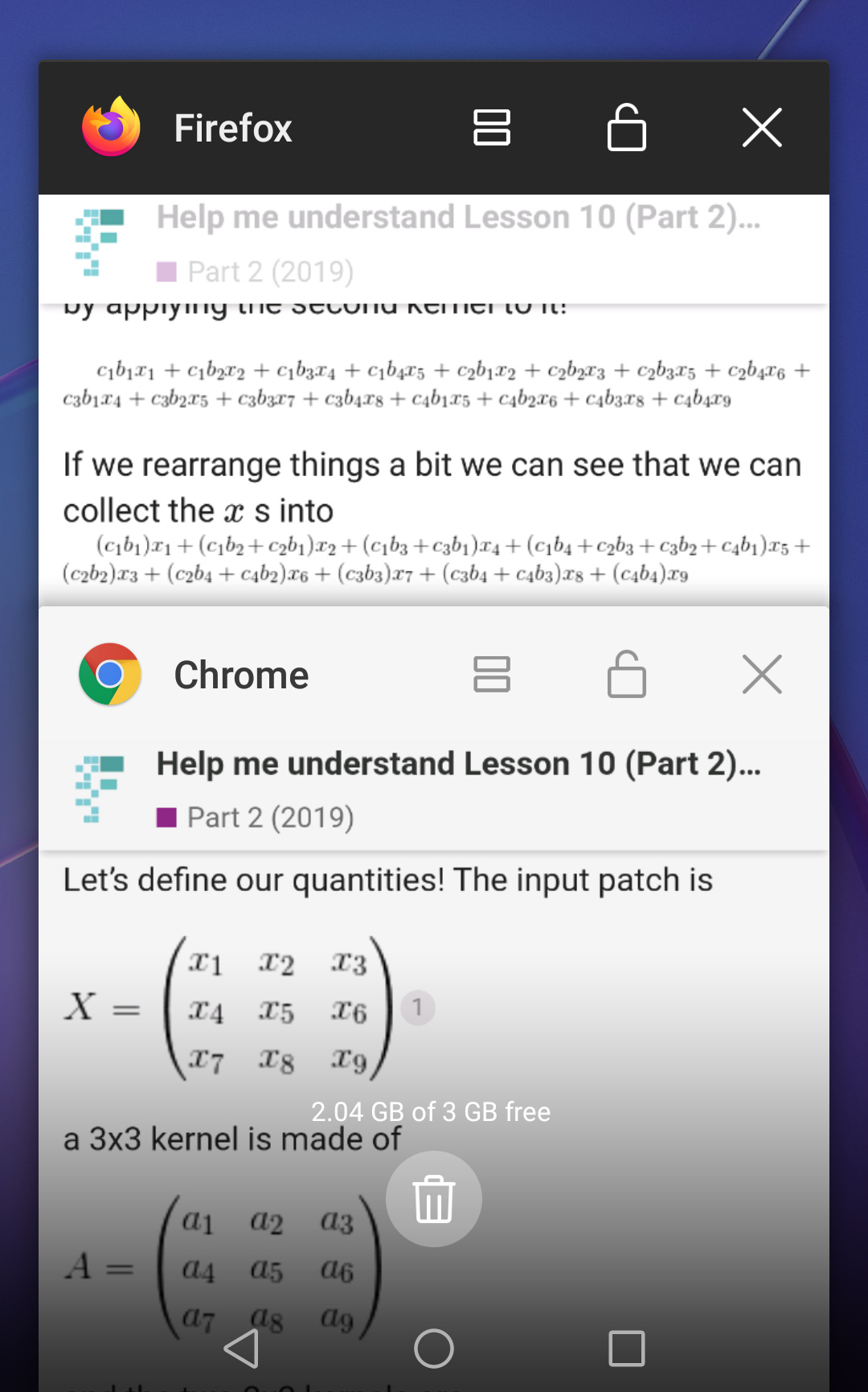
Let’s define our quantities! The input patch is

a 3x3 kernel is made of

and the two 2x2 kernels are

Now, let’s apply the 3x3 convolution to the input, the result is

When instead we apply the 2x2 convolution in serie, we get first

by applying the first kernel to the input and then
 + c_2 \left( b_1 x_2 + b_2 x_3 + b_3 x_5 + b_4 x_6 \right )+ c_3 \left(b_1 x_4 + b_2 x_5 + b_3 x_7 + b_4 x_8 \right) + c_4 \left( b_1 x_5 + b_2 x_6 + b_3 x_8 + b_4 x_9 \right)$$")
by applying the second kernel to it!

If we rearrange things a bit we can see that we can collect the x s into
 x_1 + (c_1 b_2 + c_2 b_1) x_2 + (c_1 b_3+c_3 b_1) x_4 + (c_1 b_4 + c_2 b_3 + c_3 b_2 + c_4 b_1) x_5 + (c_2 b_2) x_3 + (c_2 b_4+c_4 b_2) x_6 + (c_3 b_3) x_7 + (c_3 b_4 +c_4 b_3) x_8 + (c_4 b_4) x_9$$")
and so this is where we compare this result with the initial application of the 3x3 to the inputs (recall that it was this below)
If we equate the two results we can see that for them to be equivalent we must have
 = a_1 \ (c_1 b_2 + c_2 b_1) = a_2 \ (c_2 b_2) = x_3 \ (c_1 b_3+c_3 b_1) = a_4 \ (c_1 b_4 + c_2 b_3 + c_3 b_2 + c_4 b_1) = a_5 \ (c_2 b_4+c_4 b_2) = a_6 \ (c_3 b_3) = a_7 \ (c_3 b_4 +c_4 b_3) = a_8 \ (c_4 b_4) = a_9 \end{cases} $$")
but you can verify easily that when you try to solve this wrt to the kernel A (considering all of B abc C as given), this is trivially a system of 9 equations in 9 unknowns. I’ve laid out all you need to find the values of A!
(In layman terms, the 3x3 convolution can exactly reproduce the result of the two 2x2 convolutions if we do not take the non-linearities into account)
The problem comes from when you try to solve it the other way around, wrt to B and C! Unless we restrict some values of A, exactly one to be precise, this is a system of 9 equations in 8 (!!!) unnknowns, the values b_1, ... b_4, c_1, ... c_4, so the system has no solution!
Again, informally speaking this means that (non-linearity notwithstanding) the two 2x2 kernel cannot in general reproduce exaclty the result of a single 3x3 convolution!
The same of course apply to 5x5 versus two 3x3 kernels though, and we know that in practice often we get satisfactory results as well, but this is how you prove “formally” that a single bigger kernel is in general more expressive.
I hope that clear! 
EDIT: argh! equations are not rendered! Give me a sec while I work on a solution! 
EDIT2: saved? yes! Thanks codecogs