Greetings,
MobileODT is the first active project I’m running on Kaggle after my first pass at Part #1 and some peaks at Part #2 (couldn’t resist).
After reproducing each lesson’s notebook on its own until I understood its inner workings, I constructed a dedicated notebook building on each component showcased by @jeremy and @rachel.
I started with a basic ConvNet on the Stage 1 dataset, reduced to a sample one and made a few submissions.
Then I gradually applied the new techniques.
At this stage (version 22), I’m using the full Stage 2 Data Set:
-
using pre-trained VGG16BN weights to pre-compute last conv layer’s outputs
-
saved the different arrays
-
build a new model on top, with dense layers and made a few submissions
-
tested different learning rates, different optimizers, number of epochs
-
then Data Augmentation using Jeremy’s tip in Lesson #6 on the original training set (x 3) and concatenating it.
Note: the MixIterator approach in Lesson 7 isn’t working anymore. -
tried using different image input_size like 512x512 over the standard 224x224 of VGG, no impact (?) = threw it away.
-
used clipping of 0.93 before submitting results.
-
and countless debugging through trial and error, plus the “OOM” crashes ^!^, I’ve learned way more in this coding experience -per hour- than during all my watching and readings of Part #1.
But as Jeremy said “If and when you find a way to stop fecking around the architecture, let us know because I don’t sleep !” <= it’s me now.
My first submission got a score of 21.45.
This v22 got 1.83 (but the Sample Submission is 1.005  )
)
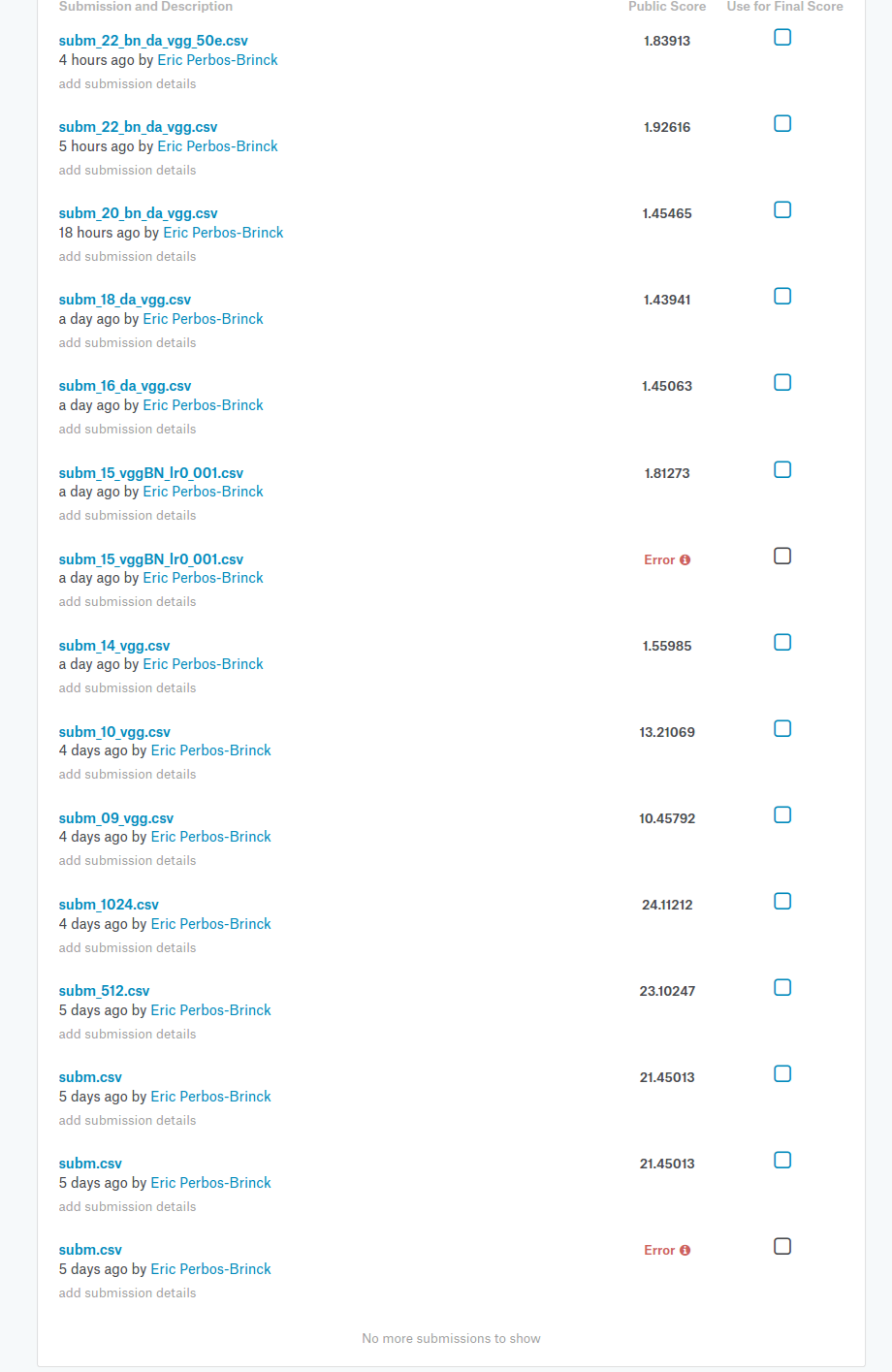
At this stage, it feels like I’ve tried everything in my current toolbox of Part #1.
If anyone among the Part 2 alumni could have a look at my notebook #22 on GitHub below and share what’s wrong/missing or how you’d approach that project yourself, I’d be super grateful.
Note: it is posted in the final-submission sequence, thus mainly ‘Load/save /results/conv-xyz.dat’ cells will seem active but all cells present were used at some point.
Fast.ai yours !
Eric