It is similar to COCO, so I am using ObjectItemList. I have made a function to get annotations in the same format as needed by ObjectItemList. For reference, I show screenshot below.
The screenshot of COCO.TINY following the data_block docs
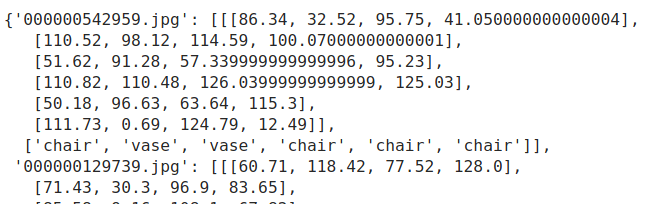
Below is the screenshot of my annotations
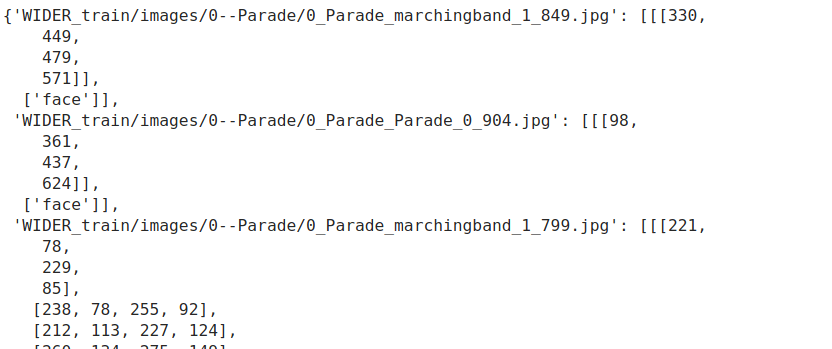
They are of the same format so the annotations are correct. I think the problem is specifying some paths.
path = Path('/home/kushaj/Desktop/Data/WIDER/')
# Below is file structure of path
├── wider_face_split
│ ├── readme.txt
│ ├── wider_face_test_filelist.txt
│ ├── wider_face_train_bbx_gt.txt
│ ├── wider_face_val_bbx_gt.txt
├── WIDER_train
│ └── images
└── WIDER_val
└── images
I have combined the annotations for the train and valid images and given that dict the name of annot. Then I created get_y_func = lambda o: annot[o.name]
My databunch code
data = (ObjectItemList.from_folder(path)
.split_by_folder(train='WIDER_train/images', valid='WIDER_val/images')
.label_from_func(get_y_func)
.transform(get_transforms(), tfm_y=True, size=(640,640))
.databunch(bs=8, num_workers=8, collate_fn=bb_pad_collate))
But I am not able to get any images in my dataloaders. When I check len(data.train_dl) is gives 0