Title says it all. Since AlexNet, all the popular CNNs have been trained on ImageNet, which I suppose makes sense since I) Labeling large datasets can be a tedious task and II) ImageNet is neither too big for individuals & small research centres nor too small as to make the task too easy or boring. However, with the rise self-supervised learning, I’m bewildered that no one has tried using GIGANTIC datasets for training CNNs, especially with the abundance of non-labelled images on the internet (all the images on Google, videos on YouTube, Instagram posts, etc.). In short, why hasn’t there been any attempts at creating a GPT-3 for images?
Multiple issues come to mind, none of which I believe can truly justify the lack of research in this area:
“Small” models (i.e. basically all commonly used CNNs) can’t fully take advantage of huge datasets. Technically a valid point, but we could just try building wider & deeper networks (what GPT-3 did).
Privacy & policy issues: Although most might not legally have the ability to crawl the web and download all available images & videos, big corporations such as Google and Facebook likely can (Google’s JFT-300M, for instance)
Good question. I think your third point of lacking interest certainly plays a role, with NLP being the current hot topic in ML. Maybe there just isn’t that much interest in computer vision at the moment or the expected results of a giant model would not outweigh the cost of training?
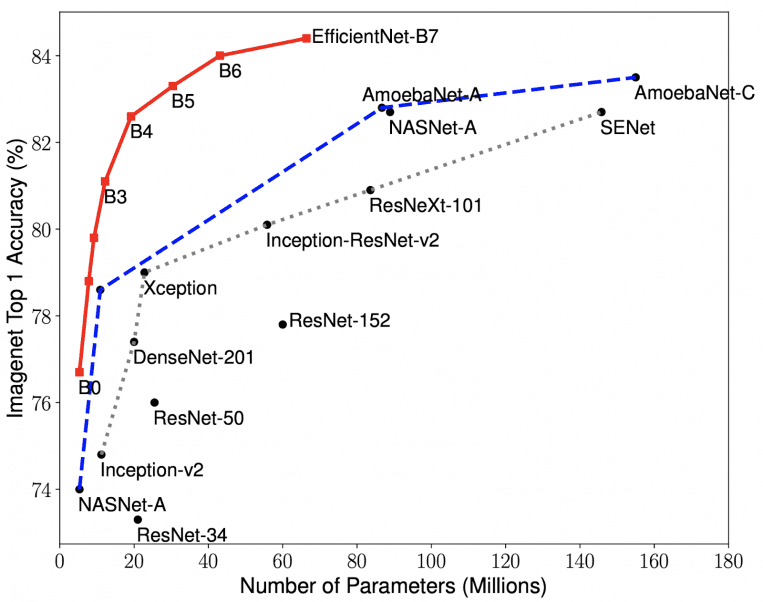
Or maybe there’s a technical reason and CNNs might just not scale as well as for example the transformer architecture? When you look at the diminishing return of adding parameters:
(Although this might look different if you increased the dataset, I guess)
Oh, and you probably read about Image GPT, quite literally a GPT for images. They used a “mix of ImageNet and images from the web” but I didn’t find exact numbers on how many images they trained on.
Thank you for your answer. Regarding the declining improvement adding more parameters yields, I think your counterpoint is very well grounded because at the end of the day, there are only so many features in images in ImageNet that CNNs can extract, and more data should certainly help. In fact, Google’s JFT-300M paper argues how more data and models with higher capacities go hand in hand (and that’s without hyperparameter tuning). Vision transformers might be even better candidates, since we’ve already seen how they can attain SOTA on big datasets.
Anyway, I’m very sad no one has tried this before. Imagine seeing GPT-3-awesome results for vision. And thank you for the link to Image GPT, I did stumble upon it during my research (as well as similar projects) but unfortunately, none of them use the amount of data I had in mind.
Thank you for your time and have a good day / evening!