Hi guys, long time no see. Recently I am re-implementing the RPN (Region Proposal Network from faster rcnn), using deepfashion dataset. I mainly refer to this project: https://github.com/yhenon/keras-frcnn
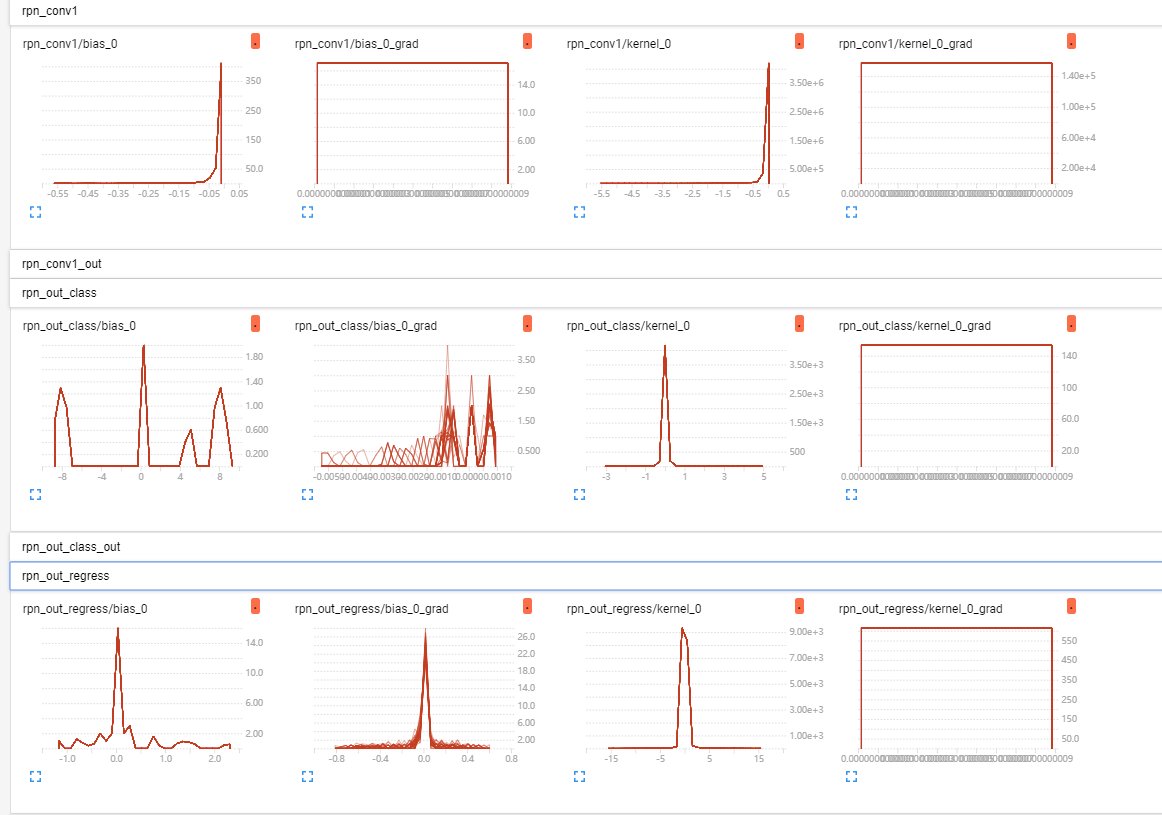
Here’re my training tensorboard histogram:
loss curve:

As you can see, the loss didn’t decrease any more after the first epoch, and the gradient and kernel weights histogram is so wired, seems they are not update anymore.
All of the images from DeepFashion dataset just contain only 1 ground truth bbox, like this:

I’m wondering if it’s because the number of regions examples that generated from only one bbox is not enough for training, as we know the image from the Pascal dataset often contains more gournd truth bbox, so the paper author suggests sampling 256 regions. But my dataset can only generate 50 regions per image on average!
Any ideas will be appreciated, I’ve stucked here for weeeeeeeks.