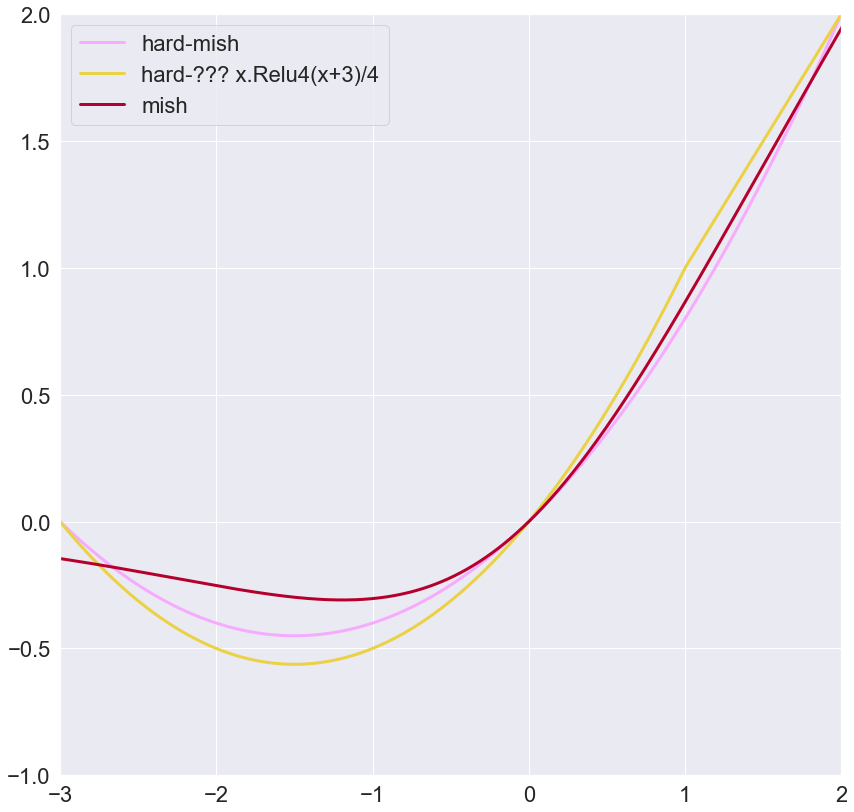
I recently read the mobilenet v3 paper and they used an approximation for swish called hard-swish: x.Relu6(x+3)/6. I extended this to mish and found that x.Relu5(x+3)/5 also seems to be a good approximation for mish. I guess hard-mish would be a good name. Here’s the notebook with my workings.
Can you shift the minima to -1? And also for the unnamed function curve (marked as yellow) in the 2nd figure, I see a discontinuity at x = 1. Based on intuition we want the function curve to be as continuous as possible, can the function be made purely smooth in the positive domain like for instance just have the effect on yellow line and keep the positive domain as ReLU?
For instance if f(x) = yellow line, then maybe we can write it as:
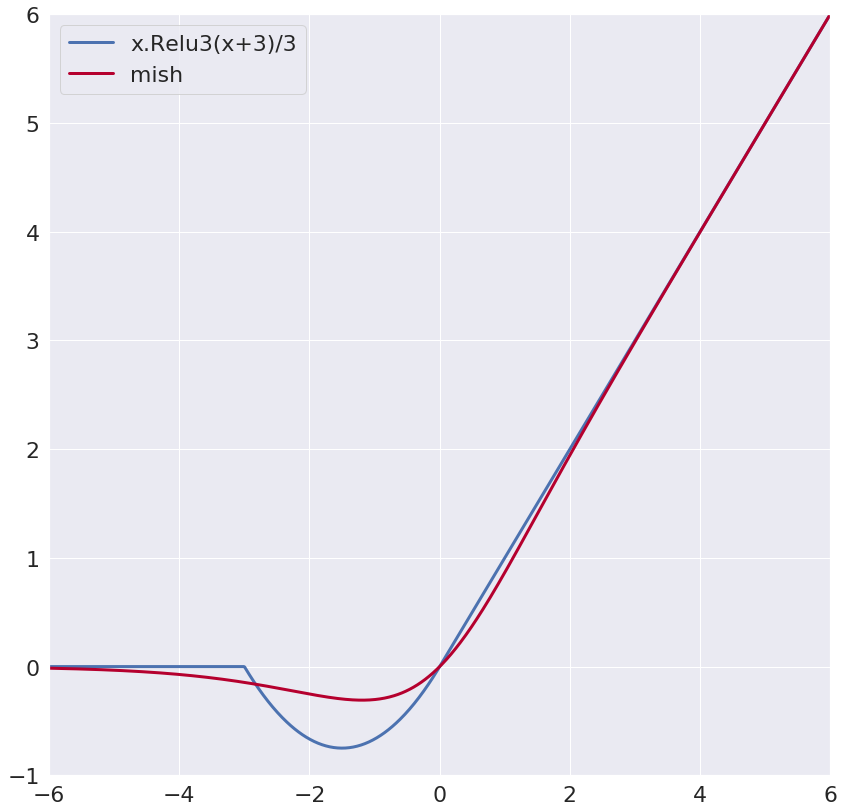
Thanks. I think the closest to those comments is x.Relu3(x+3)/3. It’s pretty smooth and goes further towards -1. All of the other functions (including hard-swish) actually have a slight discontinuity where the Relu part is equal to the divisor. The equivalent problem area is x=0 for the Relu3 function, but it doesn’t seem to have a discontinuity.
Yes, it is, however with CUDA optimization, we were able to get it faster and more closer to ReLU. You can find the CUDA optimized version of Mish here - https://github.com/thomasbrandon/mish-cuda
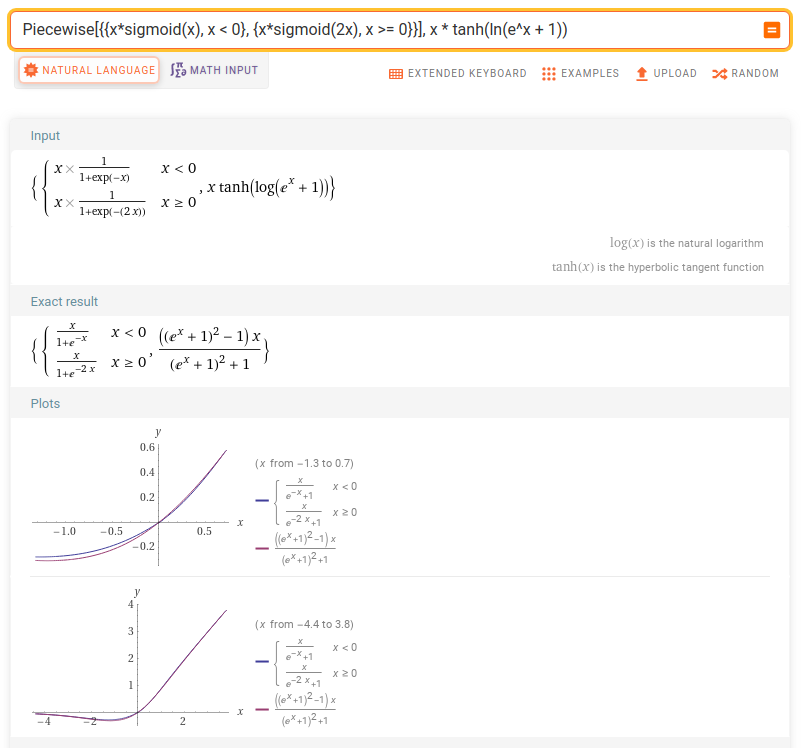
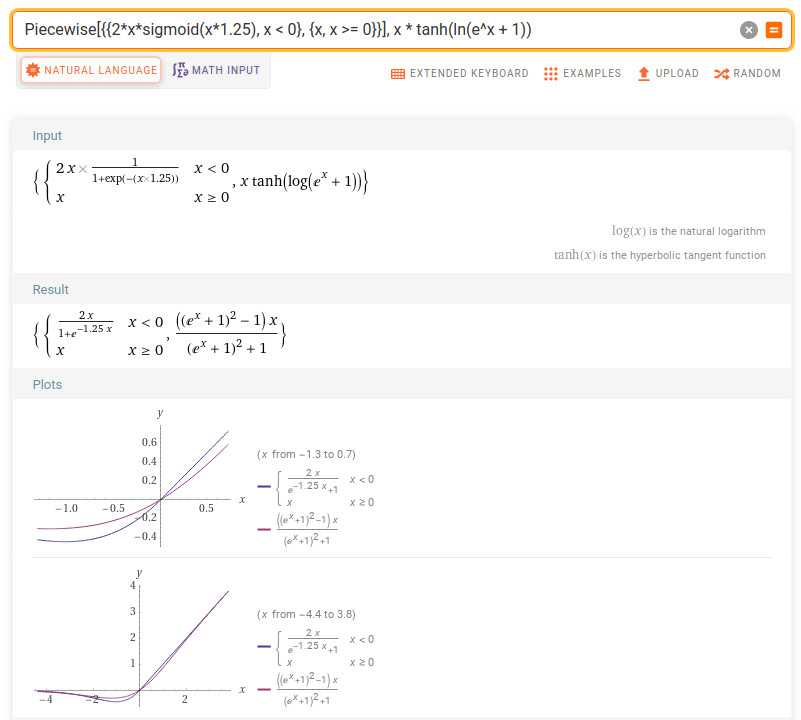
I was thinking that SWISH should be more efficient to compute than MISH, and I found this piecewise function based on SWISH which follows MISH closely:
approx_mish(x) =
x * sigmoid(x) for x <= 0 (SWISH with β = 1)
x * sigmoid(2x) for x >= 0 (SWISH with β = 2)
I noticed this after reading the unpublished APTx paper. Their proposed APTx function to approximate MISH turns out to be just SWISH with β = 2, it’s not a distinct function and it’s not very close to MISH for negative x, but it was thought provoking.
The Cuda MISH or hard MISH would likely be a better option.
I also had an idea that it would be possible to change the activation functions for a model after training, by running some epochs while gradually lerping from the old to the new activation function. This might enable to do the bulk of training with an expensive activation function, but perform inference using a cheaper function such as ReLU or hard-mish. I don’t know if such fine-tuning to change activation functions has been tried. We could also try fine tuning to prune down a model to use fewer neurons.
The performance of Cuda MISH is only 20% slower than ReLU so I guess it’s okay as it is, but perhaps it would be cheaper to use ReLU if running inference on a CPU or a weaker GPU.
I thought maybe it would be good for an activation function to be linear for all positive x, like ReLU. The following one is quite close to MISH, but linear for positive x. The gradient at the origin is 1, but not smooth there. The minimum is near (-1.023, -0.446), south east of MISH’s minimum near (-1.192, -0.309).
linear_swish(x) =
2x*sigmoid(1.25x) for x <= 0
x for x >= 0
Thanks @jeremy for tagging me. Been a while since I have been following this thread.
@sswam In regards to run-time comparison you might be interested in this evaluation
At the end, I feel while per epoch run-time/ FLOP cost is important, I am more concerned with total compute budget, i.e., epochs for convergence \times run-time per epoch. Even though Mish might be 20% slower per epoch, it ideally in most cases converges earlier than ReLU with mostly better performance. So in my opinion, incremental changes like improving run-time per epoch of Mish can be very beneficial for certainly different hardware, its just not as significant since any smooth function with composition of functions are inherently by design more expensive than ReLU. But the avenue is certainly open to explore, if you could demonstrate some results with the approximation you proposed on ImageNet or equivalent large-scale benchmarks, it can definitely be a significant contribution.
APTx offers similar smoothness and gradient flow benefits as MISH but with lower computational overhead. For example:
APTx with α=1, β=0.5, γ=0.5 exactly replicates SWISH(x, 1).
APTx with α=1, β=1, γ=0.5 exactly replicates SWISH(x, 2).
APTx closely approximates the negative domain of MISH with α=1, β=0.5, and γ=0.5.
APTx closely approximates the positive domain of MISH with α=1, β=1, and γ=0.5.
APTx with α=1, and γ=0.5, with the approximation improving as β increases and converging to ReLU in the limit β → ∞. In practice, setting α=1, β≈10⁶, and γ=0.5 already produces a close approximation of ReLU.
Installation
To install the APTx activation function in Python (with Pytorch), simply run:
pip install aptx_activation
APTx Neuron, is a novel, unified neural computation unit that integrates non-linear activation and linear transformation into a single trainable expression. The APTx Neuron is derived from the APTx activation function, thereby eliminating the need for separate activation layers and making the architecture both optimization-efficient and elegant.
To install the APTx Neuron in Python (with Pytorch), simply run: pip install aptx-neuron