Thanks that is great! Could it be that there are more fully connected layers there? Really not sure lol.
p.s. I went and bought the RTX 2080 Super Aorus! Just came so haven’t tried, will benchmark on pix2pix since it’s the model I use the most.
Thanks that is great! Could it be that there are more fully connected layers there? Really not sure lol.
p.s. I went and bought the RTX 2080 Super Aorus! Just came so haven’t tried, will benchmark on pix2pix since it’s the model I use the most.
hi guys, I am having trouble deciding which GPU to pick for my DL rigs. Which one would you recommend?
2080 Super $750 (new)
2070 Super $600 (new)
1080 TI $550 (used, never used on crypto-mining)
Thanks
I do not consider the 2080 as a cost-effective option: it got the same amount of memory as the 2070, and delivers ~15% more speed while costing substantially more.
That leaves us with the 2070 vs 1080ti.
The latter is still the best option in terms of memory for money. It will be faster than the 2070 while operating in fp32, but a bit slower in fp16 (note that pascal cards are capable of operating in fp16 mode, thus effectively doubling the vram size, but the performance gains are maginal when compared with the RTXs).
Since both of them cost more or less the same we can summarize as follows:
It scales very well. I forgot the page address, by I did read a report by pugetsystems in which they benchmarked two titan rtx both with and without nvlink. Two cards scale rather well even without nvlink.
If you want the blower version, buy the quadro rtx 6000. It has identical specs. But bear in mind that just one slot of separation would provide the necessary space for two titans to breath, given the case has a good overall airflow.
I am really happy with my RTX2080ti, btw you can get 2 x 2080ti for the price of a titan.
Actually, you can get two and half 2080ti for the price of a single titan 
But there are other considerations in favour of a single titan… For example… While it’s true that two 2080ti have more or less the same amount of memory of a single titan, not all the stuff one could work with is parallelizable. If you are forced to work with a single card, 11Gb could be a limiting factor.
I urge you to try and train a big efficientnet (b5 to b7) upon a single 2080ti. You’ll have an unpleasant surprise.
P.S.: Your tabular data repo is great!
Of corse a bigger card is better, but you can paralellize training if your batchsize is bigger than 1.
Yes, but the big question is: can you do it always?
Probably not, it depends a lot on the type of data you work with. I almost never work with high res images, or other heavy data. So for my workflow, two cards would be better. Gosh, I would love to have a second card right now =).
@balnazzar which repo?
Not an inconsiderable piece of work. ![]()
Hehe, I just wondered, because that’s my timeseries repo, and I am currently working with tabular models. Assembling Image+Tabular data.
Keep us posted ![]()
Posting here since it’s somewhat the “main rtx thread”, afaik.
I previously owned a couple 1080TIs, sold and replaced with three 2060 Supers since I had numerous issues with convergence as I used the Pascal cards in 16-bit computation. Convergence did not occur in some cases, and when it occurred, it was slower with respect to 32-bit computation.
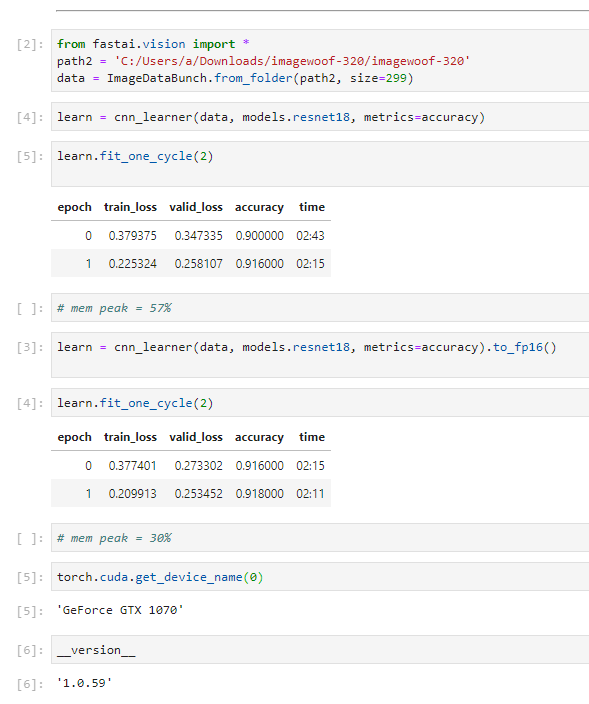
Now I am at my parents’ for Christmas vacation, and I’m using my father’s PC (windows and a GTX 1070). Since I was doing a toy project of mine with such machine, I noticed that fp16 actually converges, as of now, even with Pascal, so I ran a more systematic experiment. Look:
I used imagewoof since I wanted data upon which convergence is somewhat a bit harder with respect to MNIST or cifar.
A few things to notice:
I’d like to ask @jeremy if he made some fancy trick to the library to make convergence in fp16 possible even with Pascal and/or if maybe the latest Pytorch has something like that.
Note that I was unable to achieve decent convergence with my 1080TIs even with Nvidia Apex installed.
Note: Jeremy, I’m tagging you since you participated in this thread and so it should be pertinent to you. Thanks.
I think it’s important to clarify this, since many deep learning practitioners, and especially beginners, don’t have deep pockets. If convergence occurs even with Pascal (in any use case), it would mean that one can buy a 8gb card (1070) on ebay for ~200$, or a 11gb card (1080ti) for ~450$ while still being able to effectively double the VRAM. In such convenient way, one can spare a lot of money with respect to the expensive RTXs.
Really it’s just due to ongoing improvements from NVIDIA with cudnn and AMP, and @sgugger has been fixing things along the way too.
Thanks Jeremy! ![]()
So I think we could summarize some points.
I don’t know about that - many models get 3x or better speed improvements!
Having a 3X speedup is a really nice thing, and even for stuff which gets more modest speed gains, better having them than not. One can perform a lot more experiments in the same amount of time, ad avoid the frustration of waiting forever to train big models.
But allow me a couple of considerations:
First and foremost, I am rather bothered by the fact that Nvidia is blithely exploiting its de facto monopoly. The price ranges have shifted upwards (the previous consumer top dog, 1080ti, had an average price of 750$, now the 2080ti retails for 1300$). Clearly not satisfied, they ceased to improve the memory amount too: previously, for each generation they doubled (or almost) the memory amount: see for example Maxwell and Pascal.
But from Pascal to Turing we got the same amount of memory per segment (8gb for midrange, 11gb for top-tier) for substantially higher prices. It’s clear they want to squeeze every penny from us…
Note that meanwhile the state-of-the art models keep growing in size, see for example teh transformers and the big efficientnets
But then with 16-bit computation you almost double your memory. True, but is seems you can do it with Pascal too. You’ll just got to wait more to finish your training.
For everyone not operating in a time-critical production environment, I think the fundamental question is: is there something i can do with Turing that cannot do with Pascal. If the answer is no, as it seems, I think we shouldn’t second these crazy price policies, otherwise they’ll feel forever encouraged to give us less in exchange for more money.
As a footnote, see: https://blog.exxactcorp.com/whats-the-best-gpu-for-deep-learning-rtx-2080-ti-vs-titan-rtx-vs-rtx-8000-vs-rtx-6000/
Here, the BASE model trained using the RTX 2080 Ti (based on vanilla settings for transformer model) clearly is inferior. Note: BIG model failed training on 2x 2080 Ti System with default batch size.
It was two 2080ti. 2600$ worth of GPUs and one cannot even train a transformer decently??
These were my two cents.
Finally, could you tell me about one example or two upon which you got the 3x speedups? I am eager to confront the 2060super and the 1080ti systematically. Thanks.
My goal isn’t really to send NVIDIA a message, but to get the best price/performance ratio I can. At the moment that probably means using a GTX 2070.
IIRC we got 2-3x perf increase with fastai2’s AWD LSTM. NVIDIA have examples with up to 5x difference. Using DALI is a good idea if you’re doing vision stuff BTW to ensure you’re feeding the GPU fast enough.
DALI is really interesting, although I didn’t have the chance to try it till now. Will do asap, though.
Same here. When I ditched my 1080TIs, I opted for the 2060 super… It gives you some 5-8% less performance w.r.t the “old” 2070, but for less money. Honestly, I made the transition since the 1080TI is still very popular among gamers, and selling them I was able to get three 2060S just adding 100eur. Thinking about adding the fourth right now…
And still, I really hope to see fastai working with ROCm soon (https://rocm.github.io/pytorch.html). Think about the Radeon VII: almost half the cost of a 2080ti, and 16Gb of VRAM. Capable of 16-bit computation, too.
Note: I have no interest in AMD stocks.
Allow me to bother you with one last question: did you ever encounter some deep learning task you could not parallelize with DataParallel? (In other words, something for which one single titan rtx would have been required since you couldn’t use three 8gb-class cards)