rain and overcast conditions, i.e. totally different. Rain is not an expected use case of course, so I’m undecided about including these photos in training.
attempting to hold camera at a consistent height and walk at a steady pace (simulating a robot :)).
less conscious bias towards “easy” cases!
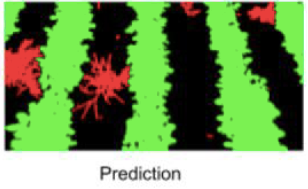
With no retraining accuracy is down to 60%. It’s clear thistles need better representation in the sample. Like the drone examples above, if the thistle is quite blurred one tends to get negative (~grass as the negative sample is dominated by Gavin’s grass photos).
Ordered a pixhawk px4 and motor controller to make a simple ground rover (M8T RTK GPS). This guy- https://www.youtube.com/user/ktrussell/videos - has some inspiring vids of an autonomous lawnmower and useful posts on the ardupilot forums. I reckon pixhawk+ardurover will be easier to quickly setup compared to AgOpenGPS for truly autonomous usage. Given up on drone.
Wrote a cleaner pipeline to slice images and get the model predictions. On my i7 MX250 laptop I can process a photo (~1600 * 400 px window split into 8x2 16 blocks of 224x224) in ~0.3 seconds.
Aiming to consistently scale each 224x224 px to represent around 30cm blocks, regardless of which camera I use. At this resolution processing 2m x 1m/sec seems easily doable (ignoring turns at end of field)- say 1 hectare in 1.5hrs.
The method I used to prepare the samples is too optimistic (tends to put the dock in the middle of the 224px bloc) compared to real life usage if using the same approach as Gavin (i.e. classifying each block instead of detecting object, a la YOLO). I am inclined to stick with the classifier so am now splitting the photos using the same pipeline model will be run with (and then tagging the little boxes).
I wrote a labelling tool, along the lines of what Gavin suggested above. It loads a photo, runs the prediction pipeline (i.e. split into blocks and generates a prediction). The image with the prediction is shown and you can press a single key to classify it (i.e. ‘g’ for grass, ‘t’ for thistle, ‘d’ for dock etc- all keys chosen near to each other for speed) and move to the next one. Currently it shows even high confidence predictions but I might skip those. I might also add an auto accept feature so that if you don’t override the model prediction in e.g. 1 seconds then it will be accepted. It’s only a super basic UI (with tkinter) atm.
I plan to tidy it up and put on github in due course.
We intentionally have clover sown in the grass and this is tripping up the model- will add an extra class. Planning to also add more to identify more common plants in the grass (not all for spraying)- dock, stinger, thistle, dandelion, buttercup, plantain weed, clover. I may try sigmoid final (i.e. sum of scores needn’t add to 1) to acknowledge that a few clips have thistles and docks! (Not actually needed for spraying but may help model discrimination in training).
Nice work, can’t wait to get back on it. Should be finished the harvest in a couple of months then I might dedicate a day a week to building the rover.
Look forward to seeing the rover!
I experimented with auto-accepting confident predictions . However, the model isn’t quite good enough yet. It’s fine at picking out actual grass and docks but has too many false positives on e.g. predicting dock on clover or buttercups (I haven’t retrained yet with those as a separate class and the negative class is dominated by plain grass).
Now I’ve got photos from different fields, lighting conditions, cameras etc. I strongly suspect the 90-95% accuracy reported in papers and forums are optimistic (compared to real life) due to how the images are captured and processed.
Here is a first version of the labelling tool. Not sure if it’s useful as it’s rather specific to my work flow- I may even add the download from google photos (with rclone).
[Hope these little updates aren’t clogging up the thread!]
Changed target to simply spray/dontspray.
‘dock’:‘spray’, ‘thistle’:‘spray’, ‘grass’:‘dontspray’, ‘stinger’:‘spray’, ‘clover’:‘dontspray’, ‘buttercup’:‘dontspray’, ‘dandelion’:‘dontspray’
(The reason for not spraying dandelions is that where they’re a problem basically it needs blanket spraying not spot spray).
Seems to work ok, model is simpler (fewer parameters), and deciding whether to spray is the ultimate decision.
Added shear and brightness to the augmentation.
91% accuracy on my 1100 test sample (60/40 split).
Included a lot more clover and model now distinguishes it from docks (although it can still be improved):
Thistles barely scraping over (the test image below is one of the better ones really). Not totally too sure what’s up here- maybe that most of the training thistles are from (cereal) field margins with soil background.
For the rover: tested RTK with u-blox M8T and rtk2go.com stream about 30km away. Ordered some little solenoids and will get friend to 3D print nozzles to target 25 x 25cm blocks.
Tried lighter nets and alternative input scales like 96x96, 128x128, 160x160 to try to speed up model run speed. Conclusion: 160x160 with e.g. mobilenet is a decent compromise. Also played with dropout and another dense on output. Requires longer training (basically all layers) at lower LR (and more conservative ReduceLROnPlateau policy etc). Eventually gets similar accuracy to transfer learning from the DeepWeeds ResNet50 but with 40% faster execution- makes Jetson Nano look maybe feasible (even running RTKlib and basic optical flow for navigation and DroneKit). This has got me quite excited as previously I envisaged having my laptop strapped on
To benchmark speed on modest hardware model was dumped in tflite format and the android example app modified to run it. Quick play and it’s surprisingly responsive. It is more sensitive to scaling than expected though.
With GPU acceleration on my phone it’s achieving <50m/s for prediction. So, not as fast as resnet50 on laptop… but a lot quicker than imagined and this is without quantization or other attempts at optimisation. Jetson Nano might just be doable.
Consciously aimed to collect more thistles in pasture. No noticeable problem with detection in static well focused images now but in live usage they still need attention.
Using an XBox controller for tagging is quicker and feels less arduous/more like a game
Google Colab used now but vast.ai is tempting (I concluded model needs retraining from scratch … again … but this time with blur augmentations).
We really need your advices guys, I am getting mad/frustrated with online python editors to retrain a pretrained alexnet on 224x224 for thistles, 2 classes. We intend to use the pth model for jetson nano inference, image classification.
With Ben we took a lot of pictures with our smartphones and use a script to crop into them so we have about 2000 of “Background” and 2000 of “Thistles”.
We successfully trained the model on Kaggle but couldn’t download the .pth from the ./kaggle/working/output directory and despite looking at forum and trying:
from IPython.display import FileLink
FileLink('/kaggle/working/best_model_ben.pth')
That didn’t work, same for creating a .zip file. So we switched to Colab and enabled our favorite GPU but the uploading is slooooow and each time you reconnect you end up losing your data. Also we are not sure why but when we try to upload more than 100 files or so at a time, we end up loosing the connection to Colab, plus we have to manually move them (the left panel doesn’t support drag and drop for the already uploaded files).
Training on the jetson nano itself is possible but the batch size has to be reduced to 4 samples and the SD card is not looking happy with the gigabytes of photos.
I usually train on my desktop with a nvidia GPU but our goal was more to do it online.
So do you guys have a good way to do it (probably because I am a n00b at this)?
What do you guys recommend for storing large datasets? Google Drive?
You were saying that 160x160 was optimized for you case. Do you recommend any sizes? The basic jetson nano one is 224x224, is there a point going 1000x1000?
Final (I promise) question, we ended up finding tutorials online for jetson nano for retraining image classification but we were wondering if you had any in mind/you recommend?
I am good thanks but busy with work and not enough time for autonomous spraybots Hope you are too!
Colab
I am not sure about Kaggle but for Colab:
Yes Google drive. (However, I also experimented with vanilla google cloud storage, which means you can put a service account key in your notebook and not do the auth each time)
Yup it is slow if copying lots of small files- zip them! I have about 19k images and copying/unzipping isn’t a big deal.
I have the same /gdrive symlink on my laptop and colab so don’t need to fiddle with paths when pasting code I’ve written locally.
Save checkpoints periodically to /gdrive.
I use rsync to keep the local and remote directories mirrored.
My training is usually 3-4 hours so the 12 hour limit is OK. I do get occasional random kills though.
I am not sure what you mean here. You can run shell commands (with wildcards), e.g. !mv ./src/*.jpg dest .
Overall yes Colab is a faff but the price is good General pros/cons of cloud, vast.ai etc vs desktop GPU are well covered elsewhere so I won’t bore you with those. I’ll use paid cloud (Google out of familiarity/laziness rather than because I’ve done exhaustive research on what’s best :)) when hopefully this project gets more serious.
Jetson Nano
I think training on Nano would be painfully slow and I don’t see the advantage over training on your desktop. I have been running mine headless (no keyboard/mouse/screen connected) for checking model performance etc so think the experience would be closer to cloud (i.e. you still have to sync training datasets etc).
Image resolution
Yes I found that 160px x 160px had only a marginal drop in accuracy compared to 224 x 224 (for image scale ~30cm x 30cm). However, I saw the Jetson Nano can run the 224 x 224 fast enough so figured there was no point compromising. All the models I have tested in the wild are 224^2 (even on my phone). At similar scaling I think 1000^2 px will be totally overkill. If you can get it working fast enouh on a Nano then more power to you I guess I know you guys are using PyTorch/Fast.ai but at 224^2 the TensorFlow-TensorRT fp16 optimised model still runs just about fast enough for me in Python, making deployment easier. For higher resolution you might need to use the C++ API if you also want your Nano running RTK-lib, maybe some pydrone kit helpers etc. I skimmed the code in jetson-inference and it doesn’t look too bad but have had no time to try. That’s a lot of waffle to say I’d stick to 224^2!
No idea for pyTorch/fast.ai but I did look for TensorFlow/Keras and can’t recommend any really. Most focus on TensorFlow 1.x whereas the new JetPacks have TF2.x and I already switched to TF2.x for everything else and resent adding tf.compat.v1 everywhere haha. I did install TF1.15 in a venv but decided it was too much faffing. My current process (not great even with bash glue):
Train with Colab default version (currently TF2.3.0) and Keras, making no special consideration of deploying to Nano.
h5 copied to Nano.
groan Nano TF2 version is actually 2.2.0, which has some irritating change for Keras models that I forget → need to redefine network and model.load_weights(…) rather than load_model directly. Model then saved for version on Nano and can be run fine. [When Jetson TF is updated this step won’t be necessary. Alternatively I could just use TF2.2.0 on Colab.]
Model is optimized with TensorFlow-TensortRT (fp16 mode).
Update on my project
Since I am writing, here’s an update of what I’ve been playing with this last month or so.
Had another field test with webcam, this time with fixed focus and fast exposure- much better but was already getting dark. https://youtu.be/Z8HcImINGg8
For faster photo acquisition/tagging I experimented with a simple html5 webapp on my phone where you can snap, tag then upload straight to google cloud- the dream is to have regular automatic retraining of the model based on what people upload and the nano could pull updates [Removed the URL because there’s no auth on it but I’ll add firebase soon
As a learning toy I built a little ArduRover bot to run some GPS missions (no RTK yet and still needs tuning). It’s basically 2x cheap cordless drills from ebay and some plywood! Junk CD for GPS grounding plate… it’s foil, right?
The steering params needs tuning. Then rebuild with big wheels, RTK and mount the Jetson Nano. There’s already USB power onboard.
WoW, thank you so much Peter for all your answers, that really helps
(You wouldn’t happen to be living in NZ so we are actually neighbours without knowing it?)
After passing my frustration with Kaggle, Ben and I decided to use Colab and jetson Nano. We had a problem of it shutting down (apparently randomly). It turned out to be that the battery PCB (from waveshare) we had couldn’t provide the 5A at MAXN. A benchtop power supply takes care of it now. thing down.
We love the idea of splitting the image into 6 and plan to do the same. Ben wrote the script to do it for training images, we will do it for the live camera feed.
At the end of the week, we will swap the nano for a TX2 and its 256 CUDA cores (from Uni) and see if that makes a difference.
But you know what set us back at least 1 day of messing around, those folder-like files created automatically by jupyter: “.ipynb_checkpoints”. It was present in the dataset folder but didn’t show up on the notebook’s file explorer. It shows up however when you do a “ls -la” in the folder. Like in the picture below.
The only error we got during training, whatever the device/cloud used, was a CUDA error , that’s it. So we wrote a script to nuke recursively all the directories, not sure if this is the correct way to do it but for now, it works and we didn’t have any problem so far.
What happened is that the training script probably thought this folder was a class and contains training images but couldn’t open it so it sent us an error. What a stupid and sneaky problem. Well, frustration over .
We have ordered an 8 (we only need 6) relay board (5V so we can power it with the jetson nano) and we are going to use 6 of the 21 GPIO of the jetson to connect to the relays and eventually turn on solenoid valves as you guys did.
Glad if my ramblings help! I am not in NZ sadly… but if I visit it’d be great to see your project! Is this related to PhD or just for fun?
Power- I haven’t seen the waveshare board but thanks for sharing. are you powering through the header pins? I had been using a cheap buck converter -> micro USB and this was actually able to run the model in 10W mode just fast enough in TF-TRT so I wasn’t concerned (with hindsight though it was throttled). With the Logitech C920 webcam the green power light was blinking (which I assume means low power) even without running the model. Hence I ordered the next cheapest buck- XL4015, claimed 5A (seems dubious), photo below. Got it today, soldered a barrel connector on and ran my test sample with the webcam switched on.
Now the model does run faster, great! However, with the GPU sustained at 100% and webcam on the poor XL4015 was getting melty. In real life the GPU would have a short break after each batch and the webcam doesn’t need 30fps but I just ordered the next cheapest (claimed 10A!) as it also needs to drive the little solenoids.
TX2- is that for the rover and is it not overkill? Or you want to go at Bilberry.io / Blue River speeds? (I think I read they are using TX2s).
Edit I ran longer tests with webcam capturing at 1fps and GPU at 100%. In defence of the XL4015 there was no voltage drop (I measured with multimeter) and with a little heatsink it didn’t feel so hot. The Nano temp reached ~54C (no fan). I’m happy to continue with this config at least till attaching the solenoids.
Trying to do something every month. The Google X Mineral announcement was both motivational and demoralising- I think the market will get competitive soon but I will continue trying even if the dream agtech startup feels too ambitious right now haha!
I haven’t done any more models but did build a full size experimental rover.
Friction drive didn’t work well especially in the wet so I’ll use 53t chainrings with a adapter on the disc mounts and drive it through an 11t cog- 11x53 will be just about manageable gearing. Rear jockey wheel will be upgraded to bigger wheel from kids bike. Frame will be extruded aluminium.
Happy new year everyone playing with deep learning ag robots!
Thanks for the link Aidan… but it’s a tease because no serious model details are discussed
It’d be interesting to know network architecture they’re using e.g. plain Mask RCNN or something custom.
I didn’t make mega progress (usual lack of time excuse!) and it was mostly on the robot rather than deep learning (i.e. not so interesting for this forum).
Robot improvements- alu frame, chain drive, 2*12ah AGM batteries (only 1 fitted currently), temporary mast and boom for camera, rear jockey pivot has proper bearings, …
The main problem is that it throws the drive chain on bumps- needs better tension and alignment.
Generally everything needs improvement before running it in the field.
Jetson Nano now has a little SSD1306 OLED screen to show model output and other useful stats ( useful ref: https://github.com/JetsonHacksNano/installPiOLED )
The nano lives in the ice cream tub on the mast. At the moment it’s totally independent of the pixhawk (incl. power). Hopefully getting them talking with dronekit/mavlink will be straightforwards. Currently when the robot starts I SSH in (with WiFi) and run the capture/model script in screen .
I hope LoRa WiFi will reach the initial target fields and 4G dongle won’t be necessary.
For the modelling part the vague idea is:
a) do an early pass with the robot just to gather lots of data (no spraying)
b) build features via self supervision
c) use those to train a preliminary classification model based on the existing tagged data
d) tag a small sample from new 2021 data (trying to ensuring key features are represented) for fine tuning and testing
Generally I’m hoping to avoid tagging lots of new data… any tips welcome!
thanks for resurrecting this thread but no progress from me
Have you done anything on it?
Random comments:
I did buy a uBlox F9P and better aerial for the robot but not fitted.
I saw there have been a couple of self supervision papers for weeds- haven’t read them but nice to see the subject is gaining traction.
Small Robot Company seem to be making progress with the ML side (including self/semi supervised and occlusion). However, they are taking a different approach where a robot does a first pass taking high res photos that are analysed offline to identify weeds etc.
Have been testing out the M8p with a base station too getting great results down to less than 10cm only issue is we are quite hilly and Reception between the base and rover can be ticky.
Just looking to revisit the computer vison side again. I’m not very experienced at that/software etc… only a mechanical engineer. The rover hardware is my jam.
Small Robot Company- don’t know them personally but full disclosure is that I invested last year so have been following investor updates. Their head of ML (a job which I actually applied for ) seems to have got stuck in well despite not having a farming background. Their grand vision is per-plant farming with a dedicated robot for taking photos and ML done in the cloud (rather than real time identifying weeds for spot spraying). At the moment I’m not 100% convinced their concept will scale well vs https://hummingbirdtech.com/ on the one hand (drone/satellite photos+cloud grunt) or John Deere/BlueRiver (real time processing on traditional tractor/sprayer with massive market of existing customers) but it’s definitely cool!
Hii everyone here especially @Gavztheouch who started this thread and @ptd006 who has made amazing stuff with this and shown us the potential of AI in agriculture.
I’m super excited to implement something whereby I create an ML model to detect whether cassava/maize plant and if yes, to kill it with laser/spray it and if it’s healthy, I will feed it fertilizers.
The model creation is the easy part here as fastai has made that easily accessible and create state of the art model.
But the difficult part is assembling the machinery, deploying the model onto the robot/machine, take pictures of the crops, and within seconds decide whether to kill or fertilize the crop.
I’m super excited and I would like to get advice guys on where to start.
This company has done an amazing work in this space












 thing down.
thing down. folder-like files created automatically by jupyter: “.ipynb_checkpoints”. It was present in the dataset folder but didn’t show up on the notebook’s file explorer. It shows up however when you do a “ls -la” in the folder. Like in the picture below.
folder-like files created automatically by jupyter: “.ipynb_checkpoints”. It was present in the dataset folder but didn’t show up on the notebook’s file explorer. It shows up however when you do a “ls -la” in the folder. Like in the picture below.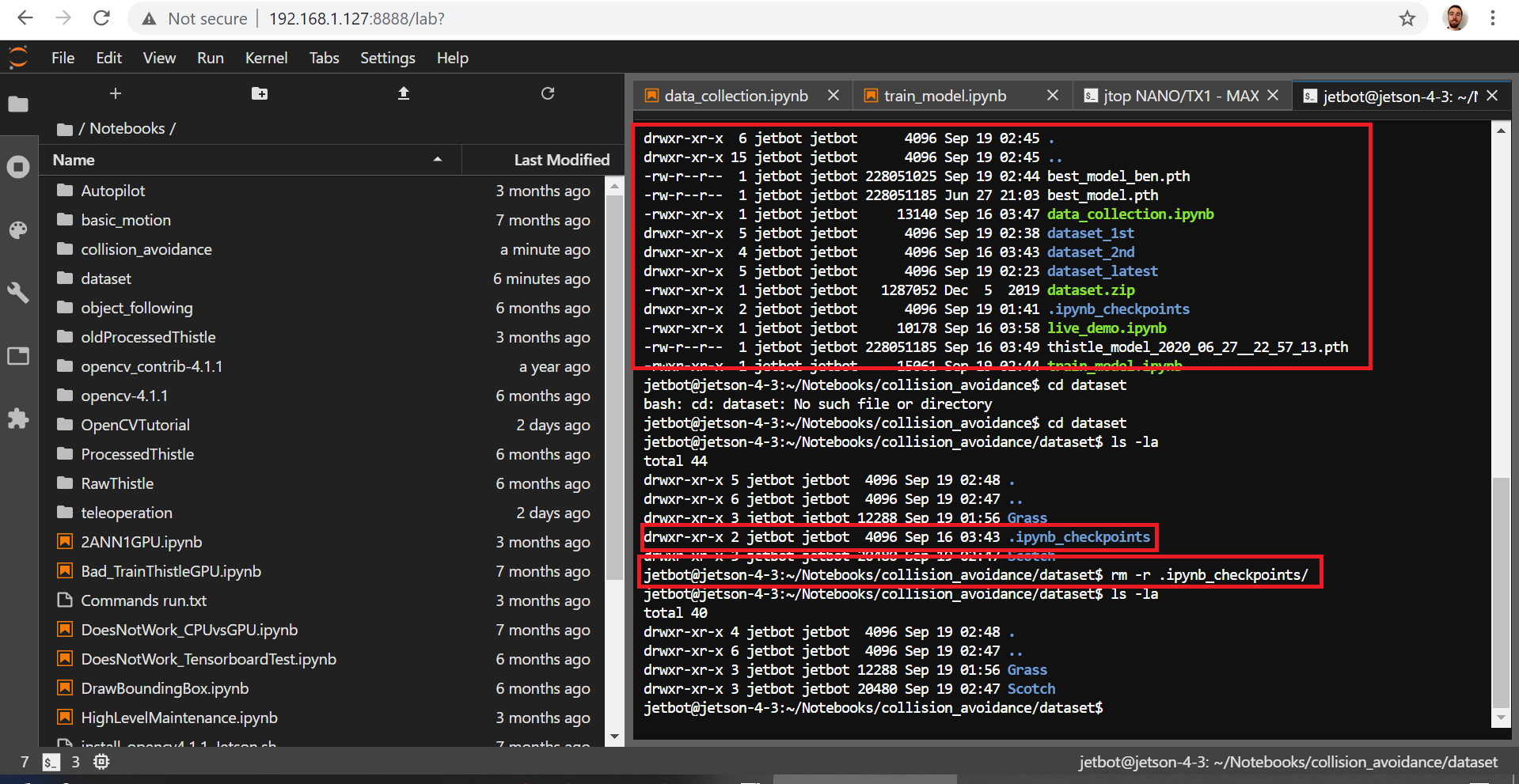
 , that’s it. So we wrote a script to nuke recursively all the directories, not sure if this is the correct way to do it but for now, it works and we didn’t have any problem so far.
, that’s it. So we wrote a script to nuke recursively all the directories, not sure if this is the correct way to do it but for now, it works and we didn’t have any problem so far. and contains training images but couldn’t open it so it sent us an error. What a stupid and sneaky problem. Well, frustration over
and contains training images but couldn’t open it so it sent us an error. What a stupid and sneaky problem. Well, frustration over  .
.







 ) seems to have got stuck in well despite not having a farming background. Their grand vision is per-plant farming with a dedicated robot for taking photos and ML done in the cloud (rather than real time identifying weeds for spot spraying). At the moment I’m not 100% convinced their concept will scale well vs
) seems to have got stuck in well despite not having a farming background. Their grand vision is per-plant farming with a dedicated robot for taking photos and ML done in the cloud (rather than real time identifying weeds for spot spraying). At the moment I’m not 100% convinced their concept will scale well vs 