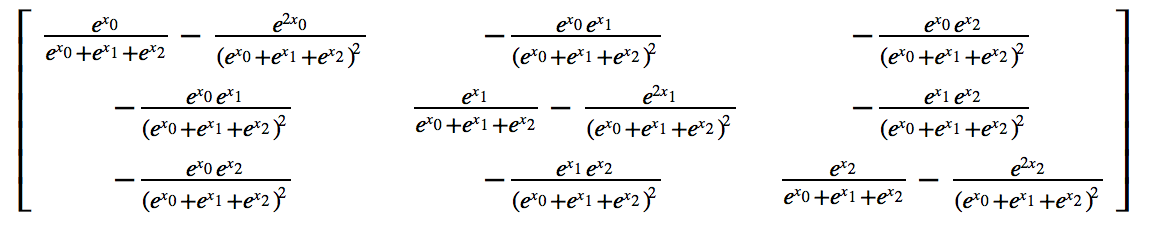Since cross entropy is the usually used loss function after softmax , and it seems to be less than 10 for me. The final multiplied gradient values will be 10^-17 * 10 = 10^-16 which is still tiny.
I haven’t looked at the magnitude of the gradients for softmax. The orders of magnitude that you mention sound a bit small though I could be mistaken.
I have softmax implemented in numpy somewhere on github and can look it up if you feel it might be helpful. The best thing to do though at this point would likely be to implement numerical gradient checking where you calculate the gradient by linear approximation (you take the loss with weight increased and decreased by some delta and divide by twice the distance). Andrew Ng has a really nice explanation of it in his original ML course on coursera. That is the best way I know of to maintain sanity when implementing such things by hand.
I am not sure how to do implement gradient checking for softmax (since all outputs depend on all inputs, do i change the entire vector by epsilon, or do i change just one value in the vector)
Since softmax is a numerically unstable , I am not sure if its easy to verify.
It would be nice if you could show me your softmax implementation (without fused cross entropy)
Also, not sure if it matters, but here is analytical derivative of softmax using Sympy:
This is code I wrote some time ago and it might be rough around the edges - sorry! Here it is.
I see I even left the numerical gradient checking there. The idea is very simple - if you have any function calculating some output value based on parameters, you can calculate a linear approximation to the gradient with regards to each of the params. Essentially, for every param, you run your entire calculation twice. You first calculate the output with w + delta and then with w - delta, obtain the difference and divide by the delta. This is how we would calculate gradients if we didn’t have calculus and the analytical form
Here is the original video by Andrew Ng. I have not gone down that low level in a very long time, but I recall that doing those numerical checks was beyond helpful. To the point where I don’t imagine working on anything of such complexity as flowing the error through a complex NN without that.
I remember deriving this on paper on a couple of occasions though seems I went for the fused form in the end. The resources that were particularly helpful for me at the time were this page on Softmax regression and a lecture by Geoffrey Hinton on coursera. In one of the lectures he walks through the derivation in some detail IIRC.
It has been a while and I don’t think I want to revisit the derivation at this point, sorry. There is quite a bit I forgot over the time and I like the new direction I am taking quite a bit and don’t have a lot of time at the moment to take a turn in this more math heavy direction.
Not sure if this will be of any help but I do recall things cancelling quite a bit and the crucial part was keeping track of the minus signs. I also don’t recall there being any good derivation written out online IIRC.
Maybe someone with a math background would be willing to chime in and help. The other option might be giving stackexchenge a try. Long time ago I posted my most popular question to date on the derivative of cost function for logistic regression. A bit of a long shot but as softmax is a generalization of that loss to multiple classes maybe looking at the answer there might be of help.