Facebook recently published a paper, What Makes Training Multi-modal Models So Hard? And in it they describe an approach called Gradient Blending, which is essentially adjusting your loss function to both take into account each models individual weights as well as their combined weights. For those interested in trying this out, I’m making this thread as a documentation of sorts of the efforts. Currently I have converted their Caffe code into Pseudo-Code. My notes will be below in the comments to keep this first post clean 
6 Likes
The Model
Something interesting about this paper is instead of concatenating the outputs of the last two layers together before passing it into a FCLL (something commonly done). Instead they do this and more. So our model setup instead has 3 FCLL’s:
- Model A’s output
- Model B’s output
- Model A + B’s concatenated and it’s output.
The loss
Here comes some strong pseudo code, I’ll be testing this out soon on real data and can show the actual implementation.
def GradientBlending(model_a, model_b, model_ab, ys):
prob = torch.softmax(model, last_out)
entropy = nn.CrossEntropyLoss(prob, label)
unscaled = L1(entropy)
av_loss = model.Scale(unscaled, scale=loss_scale)
# need to know what the loss scale is
# Construct per-modality loss
if softmax:
a_prob = torch.softmax(out)
v_prob = torch.softmax(out[1])
a_entrop = nn.CrossEntropyLoss(out, lbl)
v_entrop = nn.CrossEntropyLoss(out[1], lbl1)
a_unscaled = L1(a_entrop)
v_unscaled = L1(v_entrop)
else:
a_pred_logit = output from linear layer
a_unscaled = BCEWithLogitsLossFlat(a_pred_logit, lbl)
v_pred_logit = output from linear layer 2
v_unscalled = BCEWithLogitsLossFlat(v_pred_logit, lbl2)
a_loss = model.Scale(a_unscalled_loss, scale=loss_scale)
v_loss = model.Scale(v_unscalled_loss, scale=loss_scale)
"""
model.Scale: Computes the product of two input Blobs with the shape of the latter
broadcast to match the former
"""
# actual gradient blending
weighted_a_loss = model.Scale(a_loss, scale=audio_weight)
weighted_v_loss = model.Scale(v_loss, scale=visual_weight)
weighted_av_loss = model.Scale(av_loss, scale=av_weight)
loss = sum(*weighted)
Do note it’s quite messy pseudo-code, anything that looks odd (such as a model. prefix) is their Caffe code.
4 Likes
Looking at this again, it’s actually even easier. All the if softmax is really doing is just nn.CrossEntropyLoss, as inside of it we’re already calculating the L1, so that can be skipped. model.Scale is simply multiplying by some weights. So in theory I believe our loss function should look like so:
def ModCELoss(pred, targ, ce=True):
pred = pred.softmax(dim=-1)
targ = targ.flatten().long()
if ce:
loss = F.cross_entropy(pred, targ)
else:
loss = F.binary_cross_entropy_with_logits(pred, targ)
loss = torch.mean(ce)
return loss
class GradientBlending():
def __init__(self, audio_weight=0.0, visual_weight=0.0, av_weight=1.0, loss_scale=1.0, use_cel=True):
"Expects weights for each model, the combined model, and an overall scale"
self.audio_weight = audio_weight
self.visual_weight = visual_weight
self.av_weight = av_weight
self.ce = use_cel
self.scale = loss_scale
def forward(self, audio_out, visual_out, av_out, targ):
"Gathers `self.loss` for each model, weighs, then sums"
av_loss = ModCELoss(av_out, targ, self.ce) * self.scale
a_loss = ModCELoss(audio_out, targ, self.ce) * self.scale
v_loss = ModCELoss(visual_out, targ, self.ce) * self.scale
weighted_a_loss = a_loss * self.a_weight
weighted_v_loss = v_loss * self.v_weight
weighted_av_loss = av_loss * self.av_weight
loss = weighted_a_loss + weighted_v_loss + weighted_av_loss
return loss
If anyone wants to check me please tell me if I happened to miss anything I need to read up on what they used for scale, will update if I find it
In regards to the other weights, they used three different datasets all with a variety of different weights tested, see below for that table:
| Dataset | Pre-Train | Model | Depth | Audio Weight | Visual Weight | AV Weight |
|---|---|---|---|---|---|---|
| Kinetics400 | NA | R3D | 50 | 0.014 | 0.630 | 0.356 |
| Kinetics400 | None | ip-CSN | 152 | 0.009 | 0.485 | 0.506 |
| Kinetics400 | IG-65M | ip-CSN | 152 | 0.070 | 0.485 | 0.445 |
| AudioSet | None | R(2+1)D | 101 | 0.239 | 0.384 | 0.377 |
| EPIC-Kitchen Noun | IG-65M | ip-CSN | 152 | 0.175 | 0.460 | 0.364 |
| EPIC-Kitchen Verb | IG-65M | ip-CSN | 152 | 0.524 | 0.247 | 0.229 |
I’ll try to get any of their datasets working (or Kaggle multi-modal datasets) and see what works
3 Likes
Can you link the source for this?, I tried to find how L1 is applied after CrossEntropyLoss but can’t find it.
1 Like
Sure, so if we check the source for nn.CrossEntropyLoss, it’s doc string says:
This criterion combines :func:`nn.LogSoftmax` and :func:`nn.NLLLoss` in one single class.
If we further go check F.cross_entropy it runs an nll_loss
(I believe I got L1 loss wrong, as they’re different, the Caffee code says they take the AveragedLoss, which I believe is done by the nll_loss)?
The docs are here: Operators Catalog | Caffe2
Either that or I need to revisit this as I got it wrong ![]() (which I wouldn’t be surprised about)
(which I wouldn’t be surprised about)
For practice I may just code it myself by hand and see what I get, word for word. Should be a fun exercise too ![]()
1 Like
@vijayabhaskar quick experiment and they are not the exact same thing!
Take a look:
So the steps they performed are (in caffe):
a_prob = brew.softmax(model, a_last_out, "a_prob")
a_entropy_loss = model.net.CrossEntropy(
[a_prob, 'label_float'], "a_entropy_loss")
a_unscaled_loss = model.AveragedLoss(
a_entropy_loss, "a_unscaled_loss")
Now the theory is that is equivalent to CrossEntropyLossFlat
If we convert it line by line, our call to F.cross_entropy would be:
loss = F.cross_entropy(out.softmax(dim=-1), truth.flatten().long())
loss_unscaled = torch.mean(loss)
This results in 0.7242
If we call CrossEntropyLossFlat, passing in what we had we get 0.7628, which is not the same. (Also still not 100% on that, since I know that it calls the log argmax)
1 Like
I asked that because I first saw your tweet and got confused why L1 loss is applied after CrossEntropyLoss and then went to look for it and couldn’t find where L1 loss was used. Glad you found the answers.
1 Like
Hi @muellerzr!
Have you managed to make ir work? I have some hybrid models, using standard concatenation and standard crossentropy loss. I am thinking if it is worth a shot to try this new approach.
Hey @fmobrj75, I am afraid I’ve been a bit caught up in other things so I haven’t gotten to it this week. I plan on taking another crack at it next week though ![]() / this weekend
/ this weekend
1 Like
Thanks. I will also try to take a look into it.
1 Like
Hey all,
Had a look at this and managed to get a model training (training maybe != working  )
)
NOTEBOOK HERE
Data
I started with @muellerzr’s MixedDL notebook with the Kaggle Melanoma dataset. I used an upload that had 224x224 images (3gb) as the original DICOM dataset was 106gb.
I used a balanced dataset (1168 images total), as the original dataset is heavily unbalanced, to able to quickly iterate and also easily understand what the accuracy meant.
Model
The model code is below. I took the standard fastai models from tabular_learner and cnn_learner.
For the multi-modal classifier (or “mixed” classifier) I used PyTorch hooks to grab the inputs into the last layers of the vision and tabular models during the forward pass, and then fed these to a single linear layer.
Gradient Blending
I took the same code that @muellerzr posted earlier in this thread
Weights
Right now the weights are statically calculated, however I think getting the online weight version working might be doable, otherwise we’re left with another 3 hyperparameters to tune 
Multi-Modal Model
Model code:
class TabVis(nn.Module):
def __init__(self, tab_model, vis_model, num_classes=2):
super(TabVis, self).__init__()
self.tab_model = tab_model
self.vis_model = vis_model
self.mixed_cls = nn.Linear(512+100, num_classes)
self.tab_cls = nn.Linear(100, num_classes)
self.vis_cls = nn.Linear(512, num_classes)
#self.print_handle = self.tab_model.layers[2][0].register_forward_hook(printnorm)
self.tab_handle = self.tab_model.layers[2][0].register_forward_hook(get_tab_logits)
self.vis_handle = self.vis_model[-1][-1].register_forward_hook(get_vis_logits)
def remove_my_hooks(self):
self.tab_handle.remove()
self.vis_handle.remove()
#self.print_handle.remove()
return None
def forward(self, x_cat, x_cont, x_im):
# Tabular Classifier
tab_pred = self.tab_model(x_cat, x_cont)
# Vision Classifier
vis_pred = self.vis_model(x_im)
# Logits
tab_logits = glb_tab_logits[0] # Only grabbling weights, not bias'
vis_logits = glb_vis_logits[0] # Only grabbling weights, not bias'
mixed = torch.cat((tab_logits, vis_logits), dim=1)
# Mixed Classifier
mixed_pred = self.mixed_cls(mixed)
return (tab_pred, vis_pred, mixed_pred)
PyTorch Hooks
global glb_tab_logits
def get_tab_logits(self, inp, out):
global glb_tab_logits
glb_tab_logits = inp
#return None
global glb_vis_logits
def get_vis_logits(self, inp, out):
global glb_vis_logits
glb_vis_logits = inp
#return None
Metrics
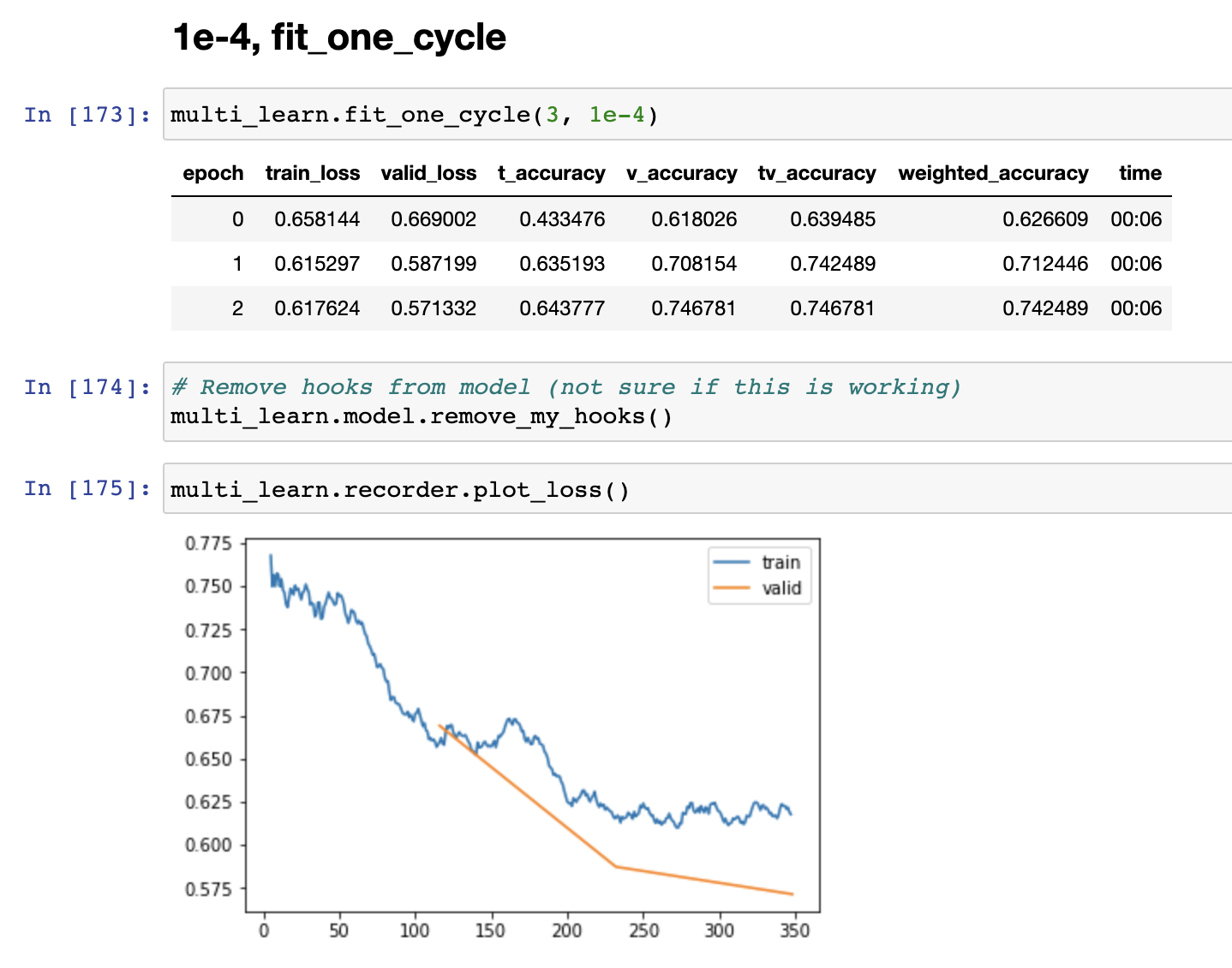
Note sure of the best strategy to calculate accuracy, I calculated it for each classifier individually, and then took at weighted average of the predictions for a weighted_accuracy
def t_accuracy(inp, targ, axis=-1):
"Compute accuracy with `targ` when `pred` is bs * n_classes"
pred,targ = flatten_check(inp[0].argmax(dim=axis), targ)
return (pred == targ).float().mean()
def v_accuracy(inp, targ, axis=-1):
"Compute accuracy with `targ` when `pred` is bs * n_classes"
pred,targ = flatten_check(inp[1].argmax(dim=axis), targ)
return (pred == targ).float().mean()
def tv_accuracy(inp, targ, axis=-1):
"Compute accuracy with `targ` when `pred` is bs * n_classes"
pred,targ = flatten_check(inp[2].argmax(dim=axis), targ)
return (pred == targ).float().mean()
def weighted_accuracy(inp, targ, axis=-1, w_t=0.333, w_v=0.333, w_tv=0.333):
t_inp = inp[0] * w_t
v_inp = inp[1] * w_v
tv_inp = inp[2] * w_tv
inp_fin = (t_inp + v_inp + tv_inp)/3
pred,targ = flatten_check(inp_fin.argmax(dim=axis), targ)
return (pred == targ).float().mean()
11 Likes
Fantastic @morgan!!! I’ll run it on my own dataset here soon and update if I noticed any improvements as well, this will definitely tell us if we’re on the right track 
2 Likes
Hi!
First of all, thank you for the great resource!
Have some questions on @morgan implementation. Why are you calculating weighted accuracy? Also,
Did you try to increase the number of layers in the “mixed” classifier? If no, what would be your guess if you increase complexity in there?
I am doing some experiments with Image+Tabular with high class imbalance. I am trying to use some weighted cross entropy as explained here but I am not quite sure if this is implemented correctly, here is a code snipped:
def ModCELoss(pred, targ, weight=None, ce=True):
pred = pred.softmax(dim=-1)
targ = targ.flatten().long()
if ce:
loss = F.cross_entropy(pred, targ, weight=weight)
else:
loss = F.binary_cross_entropy_with_logits(pred, targ, weight=weight)
#loss = torch.mean(ce)
return loss
class myGradientBlending(nn.Module):
def __init__(self, tab_weight=0.0, visual_weight=0.0, tab_vis_weight=1.0, loss_scale=1.0, weight=None, use_cel=True):
"Expects weights for each model, the combined model, and an overall scale"
super(myGradientBlending, self).__init__()
self.tab_weight = tab_weight
self.visual_weight = visual_weight
self.tab_vis_weight = tab_vis_weight
self.ce = use_cel
self.scale = loss_scale
self.weight = weight
def forward(self, xb, yb):
tab_out, visual_out, tv_out = xb
targ = yb
"Gathers `self.loss` for each model, weighs, then sums"
tv_loss = ModCELoss(tv_out, targ, self.weight, self.ce) * self.scale
t_loss = ModCELoss(tab_out, targ, self.weight, self.ce) * self.scale
v_loss = ModCELoss(visual_out, targ, self.weight, self.ce) * self.scale
weighted_t_loss = t_loss * self.tab_weight
weighted_v_loss = v_loss * self.visual_weight
weighted_tv_loss = tv_loss * self.tab_vis_weight
loss = weighted_t_loss + weighted_v_loss + weighted_tv_loss
return loss
Where I added a new weigth value in both ModCELoss and myGradientBlending class. It seems to work well but I would like to tell me what you think.
Finally, how do you assess the proper weights for each loss? I do not quite understand this part, could you develop a little bit ![]() ?
?
EDIT: And just one more, any hints on how ClassificationInterpretation should be modified in order to make it work in this kind of model?
Thanks!
1 Like
An update on this. I am not quite sure if this should be the proper place to comment this. If you think is necessary I will open another topis.
I am trying to reformulate the whole pipeline to expect multicategory inputs. As @morgan did, I tried first to train the single models with both class imbalance weights and multicategory.
The thing is, I can train the visual model without an issue with something like:
get_x = lambda x:path/f'{x[0]}'
#get_y=ColReader('Label')
def get_y(r): return r[1].split(' ') # This is te column where the labels are (4 of them)
batch_tfms = aug_transforms(flip_vert=False,do_flip=False, max_lighting=0.1, max_zoom=1.05, max_warp=0.)
#blocks = (ImageBlock(cls=PILDicom), CategoryBlock(vocab=[0,1]))
im_db_m = DataBlock(blocks = (ImageBlock, MultiCategoryBlock),
get_x = get_x,
get_y =get_y,
#get_y = ColReader('Label'),
#item_tfms = RandomResizedCrop(128, min_scale=0.35),
#batch_tfms=Normalize.from_stats(*imagenet_stats)
splitter = splitter,
item_tfms = Resize(512),
batch_tfms = batch_tfms
)
vis_dl_m = im_db.dataloaders(train_df_ready, bs=8)
vis_learn_m = cnn_learner(vis_dl_m, resnet34, metrics=accuracy_multi, pretrained=True)
vis_dl_m.loss_func = BCEWithLogitsLossFlat(weight=class_weights)
being class_weights = tensor([11.3539, 1.0000, 5.8010, 5.1732], device='cuda')
Here I have to mention that I have a dataset with 4 single classes but I would like to train the model to expect merged labels in the future, that’s the reason for the multicategory. If you think a better approach should be performed, please, tell me and stop reading 
So, fot the tabular_learner I have issues. I hot encoded the variables as explained here so I have a dataset with 4 more columns with my labels and True/False. If I try to train like:
y_names=['Label1', 'Label2', 'Label3', 'Label4']
to = TabularPandas(df_multi, procs, cat_names, cont_names,
y_names=y_names,
y_block=MultiCategoryBlock(encoded=True, vocab=y_names),
splits=splits)
tab_dl_m = to.dataloaders(bs=8)
tab_learn_m = tabular_learner(tab_dl_m, metrics=accuracy_multi)
tab_learn_m.loss_func = BCEWithLogitsLossFlat(weight=class_weights)
tab_learn_m.fit_one_cycle(3)
A dimension error occurs:
epoch train_loss valid_loss accuracy_multi time
0 0.000000 00:00
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-277-14422a88807c> in <module>
----> 1 tab_learn_m.fit_one_cycle(3)
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastcore/utils.py in _f(*args, **kwargs)
452 init_args.update(log)
453 setattr(inst, 'init_args', init_args)
--> 454 return inst if to_return else f(*args, **kwargs)
455 return _f
456
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/callback/schedule.py in fit_one_cycle(self, n_epoch, lr_max, div, div_final, pct_start, wd, moms, cbs, reset_opt)
111 scheds = {'lr': combined_cos(pct_start, lr_max/div, lr_max, lr_max/div_final),
112 'mom': combined_cos(pct_start, *(self.moms if moms is None else moms))}
--> 113 self.fit(n_epoch, cbs=ParamScheduler(scheds)+L(cbs), reset_opt=reset_opt, wd=wd)
114
115 # Cell
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastcore/utils.py in _f(*args, **kwargs)
452 init_args.update(log)
453 setattr(inst, 'init_args', init_args)
--> 454 return inst if to_return else f(*args, **kwargs)
455 return _f
456
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in fit(self, n_epoch, lr, wd, cbs, reset_opt)
202 self.opt.set_hypers(lr=self.lr if lr is None else lr)
203 self.n_epoch,self.loss = n_epoch,tensor(0.)
--> 204 self._with_events(self._do_fit, 'fit', CancelFitException, self._end_cleanup)
205
206 def _end_cleanup(self): self.dl,self.xb,self.yb,self.pred,self.loss = None,(None,),(None,),None,None
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in _with_events(self, f, event_type, ex, final)
153
154 def _with_events(self, f, event_type, ex, final=noop):
--> 155 try: self(f'before_{event_type}') ;f()
156 except ex: self(f'after_cancel_{event_type}')
157 finally: self(f'after_{event_type}') ;final()
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in _do_fit(self)
192 for epoch in range(self.n_epoch):
193 self.epoch=epoch
--> 194 self._with_events(self._do_epoch, 'epoch', CancelEpochException)
195
196 @log_args(but='cbs')
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in _with_events(self, f, event_type, ex, final)
153
154 def _with_events(self, f, event_type, ex, final=noop):
--> 155 try: self(f'before_{event_type}') ;f()
156 except ex: self(f'after_cancel_{event_type}')
157 finally: self(f'after_{event_type}') ;final()
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in _do_epoch(self)
186
187 def _do_epoch(self):
--> 188 self._do_epoch_train()
189 self._do_epoch_validate()
190
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in _do_epoch_train(self)
178 def _do_epoch_train(self):
179 self.dl = self.dls.train
--> 180 self._with_events(self.all_batches, 'train', CancelTrainException)
181
182 def _do_epoch_validate(self, ds_idx=1, dl=None):
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in _with_events(self, f, event_type, ex, final)
153
154 def _with_events(self, f, event_type, ex, final=noop):
--> 155 try: self(f'before_{event_type}') ;f()
156 except ex: self(f'after_cancel_{event_type}')
157 finally: self(f'after_{event_type}') ;final()
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in all_batches(self)
159 def all_batches(self):
160 self.n_iter = len(self.dl)
--> 161 for o in enumerate(self.dl): self.one_batch(*o)
162
163 def _do_one_batch(self):
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in one_batch(self, i, b)
174 self.iter = i
175 self._split(b)
--> 176 self._with_events(self._do_one_batch, 'batch', CancelBatchException)
177
178 def _do_epoch_train(self):
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in _with_events(self, f, event_type, ex, final)
153
154 def _with_events(self, f, event_type, ex, final=noop):
--> 155 try: self(f'before_{event_type}') ;f()
156 except ex: self(f'after_cancel_{event_type}')
157 finally: self(f'after_{event_type}') ;final()
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in _do_one_batch(self)
164 self.pred = self.model(*self.xb); self('after_pred')
165 if len(self.yb) == 0: return
--> 166 self.loss = self.loss_func(self.pred, *self.yb); self('after_loss')
167 if not self.training: return
168 self('before_backward')
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/layers.py in __call__(self, inp, targ, **kwargs)
295 if targ.dtype in [torch.int8, torch.int16, torch.int32]: targ = targ.long()
296 if self.flatten: inp = inp.view(-1,inp.shape[-1]) if self.is_2d else inp.view(-1)
--> 297 return self.func.__call__(inp, targ.view(-1) if self.flatten else targ, **kwargs)
298
299 # Cell
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/torch/nn/modules/loss.py in forward(self, input, target)
626
627 def forward(self, input: Tensor, target: Tensor) -> Tensor:
--> 628 return F.binary_cross_entropy_with_logits(input, target,
629 self.weight,
630 pos_weight=self.pos_weight,
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/torch/nn/functional.py in binary_cross_entropy_with_logits(input, target, weight, size_average, reduce, reduction, pos_weight)
2538 raise ValueError("Target size ({}) must be the same as input size ({})".format(target.size(), input.size()))
2539
-> 2540 return torch.binary_cross_entropy_with_logits(input, target, weight, pos_weight, reduction_enum)
2541
2542
RuntimeError: The size of tensor a (32) must match the size of tensor b (4) at non-singleton dimension 0
So, somehow tabular learner loss expects a 32 weights tensor. Tried to add a 32 tensor in the class weights filling the rest of values with 0 or with 1 but both options give me a similar dimension error. However this error appears at the end of the epoch:
epoch train_loss valid_loss accuracy_multi time
0 0.586030 0.579553 0.861255 00:15
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-288-14422a88807c> in <module>
----> 1 tab_learn_m.fit_one_cycle(3)
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastcore/utils.py in _f(*args, **kwargs)
452 init_args.update(log)
453 setattr(inst, 'init_args', init_args)
--> 454 return inst if to_return else f(*args, **kwargs)
455 return _f
456
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/callback/schedule.py in fit_one_cycle(self, n_epoch, lr_max, div, div_final, pct_start, wd, moms, cbs, reset_opt)
111 scheds = {'lr': combined_cos(pct_start, lr_max/div, lr_max, lr_max/div_final),
112 'mom': combined_cos(pct_start, *(self.moms if moms is None else moms))}
--> 113 self.fit(n_epoch, cbs=ParamScheduler(scheds)+L(cbs), reset_opt=reset_opt, wd=wd)
114
115 # Cell
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastcore/utils.py in _f(*args, **kwargs)
452 init_args.update(log)
453 setattr(inst, 'init_args', init_args)
--> 454 return inst if to_return else f(*args, **kwargs)
455 return _f
456
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in fit(self, n_epoch, lr, wd, cbs, reset_opt)
202 self.opt.set_hypers(lr=self.lr if lr is None else lr)
203 self.n_epoch,self.loss = n_epoch,tensor(0.)
--> 204 self._with_events(self._do_fit, 'fit', CancelFitException, self._end_cleanup)
205
206 def _end_cleanup(self): self.dl,self.xb,self.yb,self.pred,self.loss = None,(None,),(None,),None,None
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in _with_events(self, f, event_type, ex, final)
153
154 def _with_events(self, f, event_type, ex, final=noop):
--> 155 try: self(f'before_{event_type}') ;f()
156 except ex: self(f'after_cancel_{event_type}')
157 finally: self(f'after_{event_type}') ;final()
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in _do_fit(self)
192 for epoch in range(self.n_epoch):
193 self.epoch=epoch
--> 194 self._with_events(self._do_epoch, 'epoch', CancelEpochException)
195
196 @log_args(but='cbs')
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in _with_events(self, f, event_type, ex, final)
153
154 def _with_events(self, f, event_type, ex, final=noop):
--> 155 try: self(f'before_{event_type}') ;f()
156 except ex: self(f'after_cancel_{event_type}')
157 finally: self(f'after_{event_type}') ;final()
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in _do_epoch(self)
187 def _do_epoch(self):
188 self._do_epoch_train()
--> 189 self._do_epoch_validate()
190
191 def _do_fit(self):
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in _do_epoch_validate(self, ds_idx, dl)
183 if dl is None: dl = self.dls[ds_idx]
184 self.dl = dl;
--> 185 with torch.no_grad(): self._with_events(self.all_batches, 'validate', CancelValidException)
186
187 def _do_epoch(self):
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in _with_events(self, f, event_type, ex, final)
153
154 def _with_events(self, f, event_type, ex, final=noop):
--> 155 try: self(f'before_{event_type}') ;f()
156 except ex: self(f'after_cancel_{event_type}')
157 finally: self(f'after_{event_type}') ;final()
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in all_batches(self)
159 def all_batches(self):
160 self.n_iter = len(self.dl)
--> 161 for o in enumerate(self.dl): self.one_batch(*o)
162
163 def _do_one_batch(self):
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in one_batch(self, i, b)
174 self.iter = i
175 self._split(b)
--> 176 self._with_events(self._do_one_batch, 'batch', CancelBatchException)
177
178 def _do_epoch_train(self):
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in _with_events(self, f, event_type, ex, final)
153
154 def _with_events(self, f, event_type, ex, final=noop):
--> 155 try: self(f'before_{event_type}') ;f()
156 except ex: self(f'after_cancel_{event_type}')
157 finally: self(f'after_{event_type}') ;final()
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in _do_one_batch(self)
164 self.pred = self.model(*self.xb); self('after_pred')
165 if len(self.yb) == 0: return
--> 166 self.loss = self.loss_func(self.pred, *self.yb); self('after_loss')
167 if not self.training: return
168 self('before_backward')
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/layers.py in __call__(self, inp, targ, **kwargs)
295 if targ.dtype in [torch.int8, torch.int16, torch.int32]: targ = targ.long()
296 if self.flatten: inp = inp.view(-1,inp.shape[-1]) if self.is_2d else inp.view(-1)
--> 297 return self.func.__call__(inp, targ.view(-1) if self.flatten else targ, **kwargs)
298
299 # Cell
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/torch/nn/modules/loss.py in forward(self, input, target)
626
627 def forward(self, input: Tensor, target: Tensor) -> Tensor:
--> 628 return F.binary_cross_entropy_with_logits(input, target,
629 self.weight,
630 pos_weight=self.pos_weight,
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/torch/nn/functional.py in binary_cross_entropy_with_logits(input, target, weight, size_average, reduce, reduction, pos_weight)
2538 raise ValueError("Target size ({}) must be the same as input size ({})".format(target.size(), input.size()))
2539
-> 2540 return torch.binary_cross_entropy_with_logits(input, target, weight, pos_weight, reduction_enum)
2541
2542
RuntimeError: The size of tensor a (4) must match the size of tensor b (32) at non-singleton dimension 0
Sadly, multi_model expect the same as tabular_learner so I am kind of stuck. Any ideas why this is happening?
I have read the facebook’s publication “What Makes Training Multi-modal Classification Networks Hard?”,
but they does not release the code for finding the blending value of each modality loss. And also I cannot find any non-official implementation. Could anyone give an example? Thanks a lot.
You can check @morgan notebook or the @muellerzr’s implementation at the beggining of the thread
An update on this. I managed to get some predictions on a test set using get_preds like the following.
- Add
test.dlon vision and tabular learners like:
#Assuming you're working with df
#For vision
vis_learn.dls.loaders.append(vis_dl.test_dl(x_test, with_labels=True))
#For tabular
tab_learn.dls.loaders.append(tab_dl.test_dl(x_test, with_labels=True))
-
Create a
MixedDLwith the twodlsame astrainandvalid
test_mixed_dl = MixedDL(tab_dl[2], vis_dl[2]) -
After training
multi_learngo directly:
preds,targs = multi_learn.get_preds(dl=test_mixed_dl)
This will output a tuple for preds corresponding to (tab_pred, vis_pred, mixed_pred)
So, this work nicely. However, a couple of things I would like to comment just if someone could give me some feedback:
predsare not normalized to one, if you check the output you got something like:
tensor([[ -3.1324, 11.6989, -3.3465, -6.6904],
[ -3.0470, 12.2665, -4.2536, -8.8645],
[ -5.7865, 8.2423, -5.4613, -1.7817],
...,
[ 1.5389, -3.5621, -7.6754, 2.7510],
[ -2.4909, -8.9468, 2.5080, 4.9270],
[ -4.4602, 1.2689, -10.6158, 6.3456]])
How this should be normalize? I am not quite sure if there is something missing in forward
ClassificationInterpretationthrows an error of dimensions that I am not quite sure what it means
interp_multi = ClassificationInterpretation.from_learner(multi_learn, dl=test_mixed_dl)
Exception ignored in: <generator object MixedDL.__iter__ at 0x7f5d517e9ba0>
Traceback (most recent call last):
File "/home/jgibert/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py", line 161, in all_batches
for o in enumerate(self.dl): self.one_batch(*o)
RuntimeError: generator ignored GeneratorExit
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in _with_events(self, f, event_type, ex, final)
154 def _with_events(self, f, event_type, ex, final=noop):
--> 155 try: self(f'before_{event_type}') ;f()
156 except ex: self(f'after_cancel_{event_type}')
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in _do_one_batch(self)
165 if len(self.yb) == 0: return
--> 166 self.loss = self.loss_func(self.pred, *self.yb); self('after_loss')
167 if not self.training: return
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
TypeError: forward() got an unexpected keyword argument 'reduction'
During handling of the above exception, another exception occurred:
RuntimeError Traceback (most recent call last)
<ipython-input-348-85cdee54278a> in <module>
----> 1 interp_multi = ClassificationInterpretation.from_learner(multi_learn_0, dl=test_mixed_dl_0)
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/interpret.py in from_learner(cls, learn, ds_idx, dl, act)
27 "Construct interpretation object from a learner"
28 if dl is None: dl = learn.dls[ds_idx]
---> 29 return cls(dl, *learn.get_preds(dl=dl, with_input=True, with_loss=True, with_decoded=True, act=None))
30
31 def top_losses(self, k=None, largest=True):
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in get_preds(self, ds_idx, dl, with_input, with_decoded, with_loss, act, inner, reorder, cbs, **kwargs)
230 if with_loss: ctx_mgrs.append(self.loss_not_reduced())
231 with ContextManagers(ctx_mgrs):
--> 232 self._do_epoch_validate(dl=dl)
233 if act is None: act = getattr(self.loss_func, 'activation', noop)
234 res = cb.all_tensors()
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in _do_epoch_validate(self, ds_idx, dl)
183 if dl is None: dl = self.dls[ds_idx]
184 self.dl = dl;
--> 185 with torch.no_grad(): self._with_events(self.all_batches, 'validate', CancelValidException)
186
187 def _do_epoch(self):
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in _with_events(self, f, event_type, ex, final)
153
154 def _with_events(self, f, event_type, ex, final=noop):
--> 155 try: self(f'before_{event_type}') ;f()
156 except ex: self(f'after_cancel_{event_type}')
157 finally: self(f'after_{event_type}') ;final()
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in all_batches(self)
159 def all_batches(self):
160 self.n_iter = len(self.dl)
--> 161 for o in enumerate(self.dl): self.one_batch(*o)
162
163 def _do_one_batch(self):
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in one_batch(self, i, b)
174 self.iter = i
175 self._split(b)
--> 176 self._with_events(self._do_one_batch, 'batch', CancelBatchException)
177
178 def _do_epoch_train(self):
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in _with_events(self, f, event_type, ex, final)
155 try: self(f'before_{event_type}') ;f()
156 except ex: self(f'after_cancel_{event_type}')
--> 157 finally: self(f'after_{event_type}') ;final()
158
159 def all_batches(self):
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in __call__(self, event_name)
131 def ordered_cbs(self, event): return [cb for cb in sort_by_run(self.cbs) if hasattr(cb, event)]
132
--> 133 def __call__(self, event_name): L(event_name).map(self._call_one)
134
135 def _call_one(self, event_name):
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastcore/foundation.py in map(self, f, *args, **kwargs)
381 else f.format if isinstance(f,str)
382 else f.__getitem__)
--> 383 return self._new(map(g, self))
384
385 def filter(self, f, negate=False, **kwargs):
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastcore/foundation.py in _new(self, items, *args, **kwargs)
331 @property
332 def _xtra(self): return None
--> 333 def _new(self, items, *args, **kwargs): return type(self)(items, *args, use_list=None, **kwargs)
334 def __getitem__(self, idx): return self._get(idx) if is_indexer(idx) else L(self._get(idx), use_list=None)
335 def copy(self): return self._new(self.items.copy())
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastcore/foundation.py in __call__(cls, x, *args, **kwargs)
45 return x
46
---> 47 res = super().__call__(*((x,) + args), **kwargs)
48 res._newchk = 0
49 return res
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastcore/foundation.py in __init__(self, items, use_list, match, *rest)
322 if items is None: items = []
323 if (use_list is not None) or not _is_array(items):
--> 324 items = list(items) if use_list else _listify(items)
325 if match is not None:
326 if is_coll(match): match = len(match)
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastcore/foundation.py in _listify(o)
258 if isinstance(o, list): return o
259 if isinstance(o, str) or _is_array(o): return [o]
--> 260 if is_iter(o): return list(o)
261 return [o]
262
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastcore/foundation.py in __call__(self, *args, **kwargs)
224 if isinstance(v,_Arg): kwargs[k] = args.pop(v.i)
225 fargs = [args[x.i] if isinstance(x, _Arg) else x for x in self.pargs] + args[self.maxi+1:]
--> 226 return self.fn(*fargs, **kwargs)
227
228 # Cell
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in _call_one(self, event_name)
135 def _call_one(self, event_name):
136 assert hasattr(event, event_name), event_name
--> 137 [cb(event_name) for cb in sort_by_run(self.cbs)]
138
139 def _bn_bias_state(self, with_bias): return norm_bias_params(self.model, with_bias).map(self.opt.state)
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/learner.py in <listcomp>(.0)
135 def _call_one(self, event_name):
136 assert hasattr(event, event_name), event_name
--> 137 [cb(event_name) for cb in sort_by_run(self.cbs)]
138
139 def _bn_bias_state(self, with_bias): return norm_bias_params(self.model, with_bias).map(self.opt.state)
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/callback/core.py in __call__(self, event_name)
42 (self.run_valid and not getattr(self, 'training', False)))
43 res = None
---> 44 if self.run and _run: res = getattr(self, event_name, noop)()
45 if event_name=='after_fit': self.run=True #Reset self.run to True at each end of fit
46 return res
~/anaconda3/envs/fastai2/lib/python3.8/site-packages/fastai/callback/core.py in after_batch(self)
111 if self.with_loss:
112 bs = find_bs(self.yb)
--> 113 loss = self.loss if self.loss.numel() == bs else self.loss.view(bs,-1).mean(1)
114 self.losses.append(to_detach(loss))
115
RuntimeError: shape '[8, -1]' is invalid for input of size 1
It seems that has something to do with the loss since
multi_learn.get_preds(dl=test_mixed_dl, with_decoded=True, with_loss=True)
throws the same error. Any advice?
Thanks!