Hi!
I’m attempting to classify 2D-retinal fundus images to predict Diabetic Retinopathy using ResNet-34 from the (completed) Kaggle DR Challenge. The issue that I’m having is really slow (35 mins/epoch) and (severely) underutilizing available GPU memory. I have available 2x Tesla P100s, see $ nvidia-smi output below:
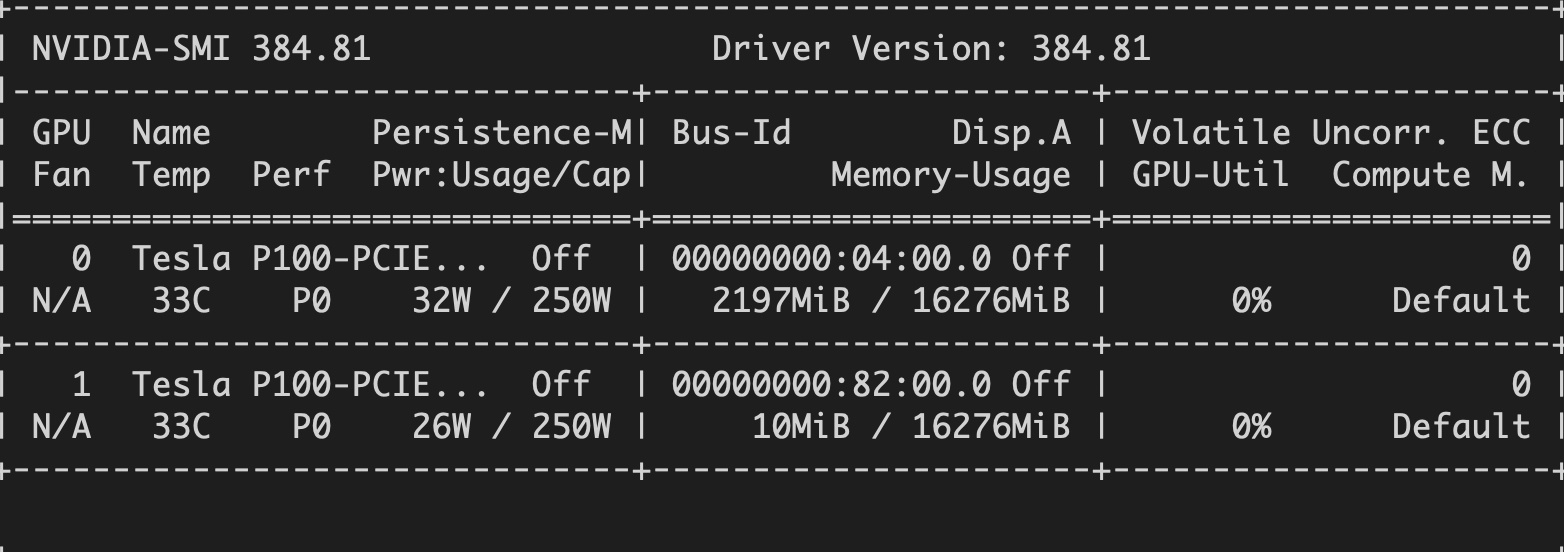
I’ve used other datasets with 1000s of images of much lower resolution and have had good success with the same computing resources. The only difference is that there are a lot more images (32K) with this dataset and of much higher resolution (3888 x 2592) which I have resized in my code below and I’ve taken a smaller sample of 5K images.
import torch
print('Make sure cuda is installed:', torch.cuda.is_available())
print('Make sure cudnn is enabled:', torch.backends.cudnn.enabled)
import fastai; fastai.__version__
True
‘1.0.57’
ds_tfms = get_transforms()
data = ImageDataBunch.from_csv(path=img_path, csv_labels=labels_path, suffix='.jpeg', valid_pct=0.2,
ds_tfms=ds_tfms, size=128, bs=128, num_workers=0);
data.classes, data.c, len(data.train_ds), len(data.valid_ds)
([0, 1, 2, 3, 4], 5, 4000, 999)
learn = cnn_learner(data, models.resnet34, metrics=error_rate)
# learn.model = torch.nn.DataParallel(learn.model, device_ids=[0, 1])
learn.fit_one_cycle(5)
I read from distributed training docs page which could help as I found no performance improvement by running learn.model = torch.nn.DataParallel(learn.model, device_ids=[0, 1])
I’ve tried varying the bs and size with different combinations of 32, 64, 218 and 512 with no success, often resulting to error messages such as https://forums.fast.ai/t/error-pytorch-expected-object-of-scalar-type-long-but-got-scalar-type-float-for-argument-2-other/33778. I’ve also tried with ResNet-50 and 101 to see if that would help, sadly same story.
I would be most grateful for any suggestions/help. Thank you!