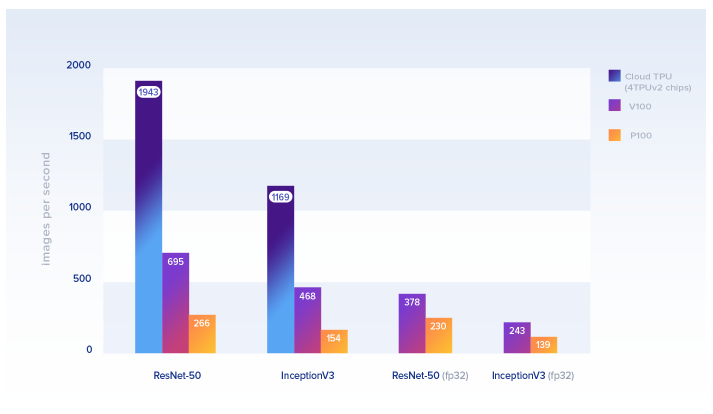
Looks like Google quietly turn on free TPU v2 for Google Colab 2 days ago. I first got to know about this from yesterday’s TensorFlow and Deep Learning group meetup in Singapore with Google’s engineers talking about TensorFlow 2.0. GPU hardware accelerator is still available. If I heard correctly, this will be available for a limited time only. I have tested this by trying to train a simple MNIST model and it works for me in this part of the world. I am planning to do a quick benchmark and compare the performance with GPU later.
Note that TPU v3 is in Alpha testing and not available to the everyone yet.
That’s an amazing news I have also just discovered : TPU for free is like a dream that comes true.
Then I try to test it out: colab CPU vs GPU vs TPU.
And training time for 12 epochs of mnist dataset is almost the same between GPU and TPU.
I can’t view the Colab notebooks. This is what I see:
I suggest you either make the notebook available to everyone or grant access to my Google Account.
But without looking at your code, I assumed you are using Keras + TensorFlow and if that’s the case, I suspect you are experiencing the slowness because you are doing the exact same thing (train/fit model) without using tf.data for the data pipeline.
On a side note, I experimented that using a smaller batch size increase performance on TPU
[ training over 12 epochs - mnist dataset]
bc=1024 -> 53s training time ; bc=128 -> 43s training time
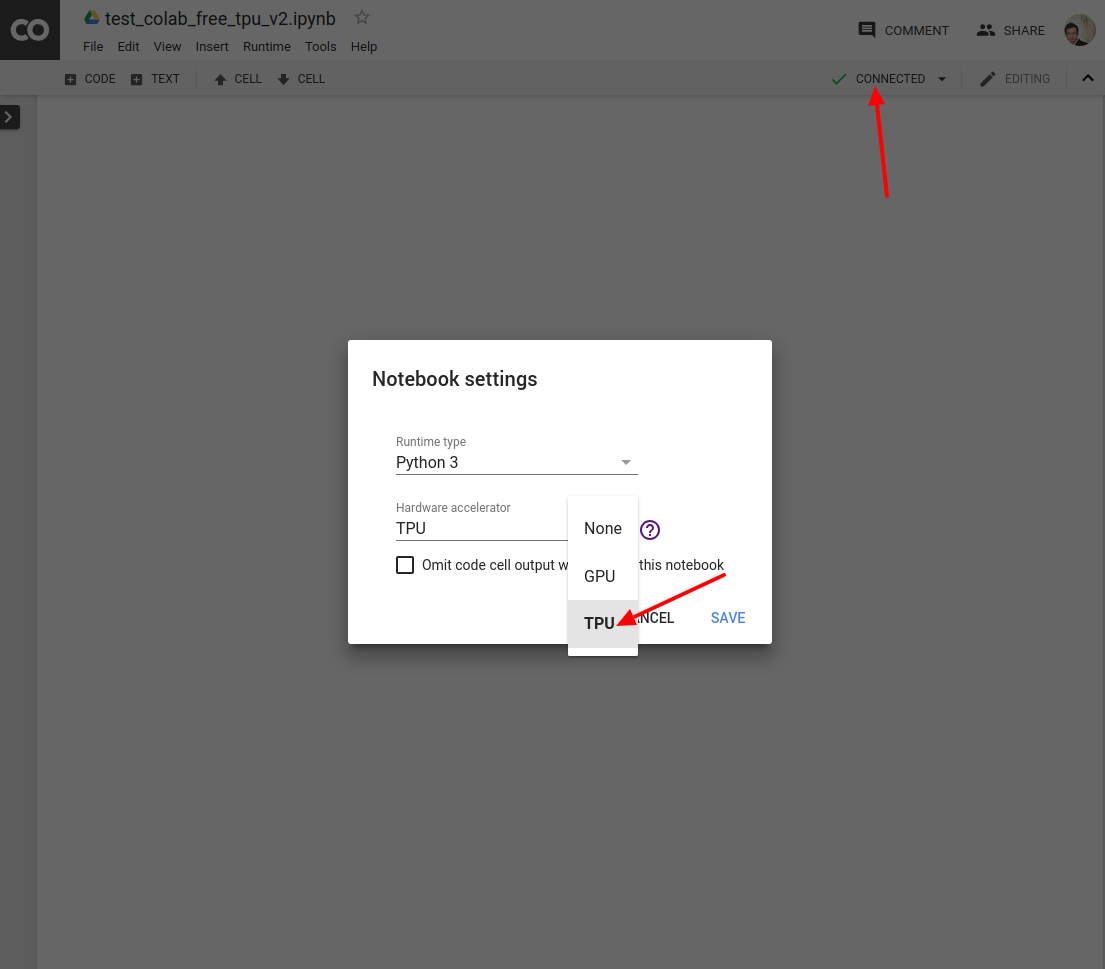
 One epoch took around 3s!!!
One epoch took around 3s!!!