This is the continuation of topic good-readings-2019 for 2020. If you want to share deep learning papers are worth reading.
From the Authors:
Two SGD trajectories (with 2 different LR) diverged after the "break-even point". In particular, showed that a high LR implicitly reduces the variance of gradients. http://arxiv.org/abs/2002.09572
One of findings in short:
Using a high learning rate is necessary in a network with batch normalization layers to improve conditioning of the loss surface,compared to conditioning of the loss surface in the same network without batch normalization layers.
2 Likes
Question for active researchers, and research paper readers 
I’m curious to know if it makes sense to know if it makes sense to follow CV and Computational Language papers at arxiv here https://arxiv.org/list/cs.CV/recent and here https://arxiv.org/list/cs.CL/recent and read the interesting papers daily? Or at least skim through them to keep up to date with the latest research?
Being able to read and re-implement papers is definitely very valuable skill nowadays.
1 Like
There is an overwhelming number of papers that have been published about BERT, in just one year. Here below, you will find a very interesting overview that summarize 40 analysis studies, published just 2 weeks ago.
A Primer in BERTology: What we know about how BERT works
Abstract
Transformer-based models are now widely used in NLP, but we still do not understand a
lot about their inner workings. This paper decribes what is known to date about the famous
BERT model (Devlin et al., 2019), synthesizing over 40 analysis studies. We also provide
an overview of the proposed modifications to the model and its training regime. We then outline the directions for further research.
Interesting Comparison of BERT Compression Studies
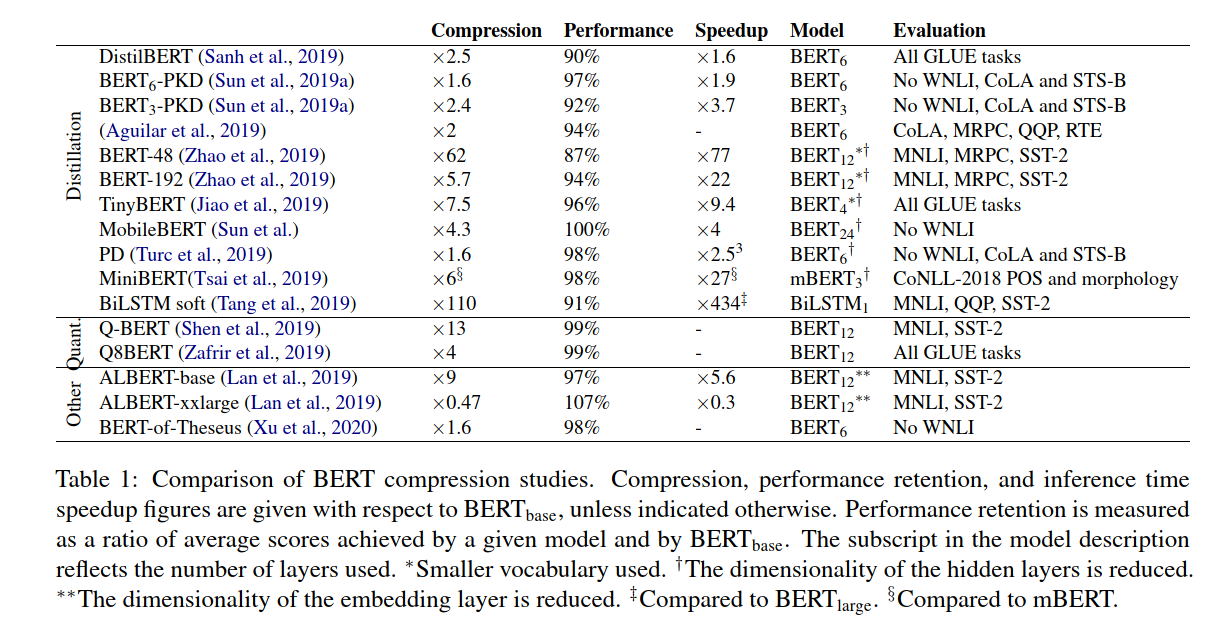
While browsing the table here above, Bidirectional LSTM (BiLSTM) performance caught my attention. BiLSTM consists in transferring task-specific knowledge from BERT to a shallow neural architecture.
Compared to BERT Large, BiLSTM has :
- compression factor : x110
- Performance retention : 91%
- Inference time : 434
For those interested in learning more about BERT, you might check out these 2 interesting resources:
Video: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Blog post: The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
@morgan, now that you earned your official title of Mister BERT in this forum after your amazing job in both porting HuggingFace transformers to fastai2 and writing a blog post about it, this paper should catch your attention in case you haven’t already seen it.
7 Likes
haha I’m not sure I deserve that title, but thanks for the paper, it caught my eye when it came out but I never got to it, thanks for the highlights! ![]()
1 Like
This paper outlines a very interesting and elegant approach to cut down model weights & FLOPs while still retaining accuracy:
4 Likes
The 2010s: Our Decade of Deep Learning (Juergen Schmidhuber)
This is a very informative summary. Despite the fact it highlights more the achievements accomplished in Dr Jürgen Schmidhuber research lab, it contains very interesting information.
Among some interesting stuff:
2 Likes
Transformers + computer vision = looks very interesting:
9 Likes
SimCLRv2: an improved self-supervised approach for semi-supervised learning. On ImageNet with 1% of the labels, it achieves 76.6% top-1, a 22% relative improvement over previous SOTA.
3 Likes
Building One-Shot Semi-supervised (BOSS) Learning up to Fully Supervised Performance
2 Likes
from the authors:
This article is the first part of a three article deep dive into curve detectors: their behavior, how they’re built from earlier neurons, and their prevalence across models.
Opportunities and Challenges in Explainable Artificial Intelligence (XAI): A Survey
Abstract from the paper:
Nowadays, deep neural networks are widely used in mission critical systems such as healthcare, self-driving vehicles, and military which have direct impact on human lives. However, the black-box nature of deep neural networks challenges its use in mission critical applications, raising ethical and judicial concerns inducing lack of trust. Explainable Artificial Intelligence (XAI) is a field of Artificial Intelligence (AI) that promotes a set of tools, techniques, and algorithms that can generate high-quality interpretable, intuitive, human-understandable explanations of AI decisions. In addition to providing a holistic view of the current XAI landscape in deep learning, this paper provides mathematical summaries of seminal work. We start by proposing a taxonomy and categorizing the XAI techniques based on their scope of explanations, methodology behind the algorithms, and explanation level or usage which helps build trustworthy, interpretable, and self-explanatory deep learning models. We then describe the main principles used in XAI research and present the historical timeline for landmark studies in XAI from 2007 to 2020. After explaining each category of algorithms and approaches in detail, we then evaluate the explanation maps generated by eight XAI algorithms on image data, discuss the limitations of this approach, and provide potential future directions to improve XAI evaluation.
This paper, suggested to Jeremy by @lnsmith613, focuses on weight decay, proposing a method for choosing the hyper-parameter similar to the LR Finder.
4 Likes
This paper, suggested by Jeremy . Looks definitely interesting to read.
Debiased Contrastive Learning
paper: https://arxiv.org/abs/2007.00224
code: https://github.com/chingyaoc/DCL
3 Likes
Very interesting:
https://kdexd.github.io/virtex
Stick a transformer as a head on your vision model and use full text captions as labels for pre-training.
PS: We need to keep this thread going, as I always enjoy the very interesting papers posted here. I’ll also try to post more often here in the future.
8 Likes
Deep Ensembles: A Loss Landscape Perspective (Paper Explained)
video explains paper:
paper Deep Ensembles: A Loss Landscape Perspective:
1 Like
Paper : Random Matrix Theory Proves that Deep Learning Representations ofGAN-data Behave as Gaussian Mixtures
comment from twitter…
Crazy exp: take Resnet embedding of Imagenet as dataset A. Train linear predictor on A; get accuracy p. Now make fake dataset B = a mixture of Gaussians w/ same class mean & covariance as A. Train linear predictor on B => get SAME ACCURACY p. WTF
2/ the spectrum of the Gram matrix of the Resnet embeddings is also the same as the spectrum of the corresponding Gaussian mixture Gram matrix. Wow
3/ This says the quality of representation is purely determined by 1st & 2nd moment of embedding distribution.
@muellerzr might be interesting for you.
2 Likes
Comprehensive review:
2 Likes
Next step in self-supervised learning:
5 Likes