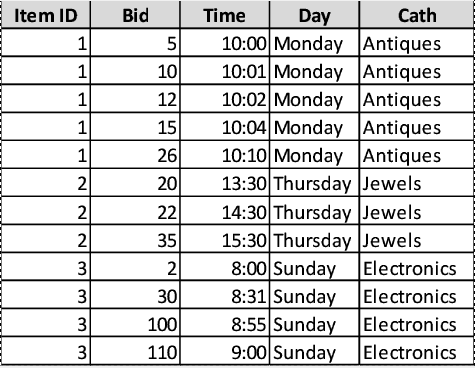
Hello everyone. I have recently started to use fastai, and as a personal excercise I wanted to create a model for regression of tabular data, but with a recurrent model. For example, we can have a csv file with auction bids, where rows are sorted by auction, with a column that identifies it. Auctions may have a variable number of bids. Of course I could double or triple the size of the input vector and just feed a fixed number of samples, but I want a proper RNN.
The creation of the model should be quite easy, by adding at least some memory cells here and there, assuming the input is not a batch of elements, but a batch of sequences of elements, as happens with the language model. The difference is that while the language model has a fixed sequence length for the training datasets given by the bptt parameter. The sequences in the tabular context usually have a variable, fixed, potentially small sequence length.
I started studying the data input classes. The data items from which to make guesses are the same: rows from the table, each with a label, so the ItemList class should ideally be the tabular one without changes. I started digging into the classes that take care of creating a batch, and I got to the sampler classes from pytorch. However, these classes use, as samples, indices from the original data source, while we need groups of the original data (rows form the dataframe) that correspond to sequences. I also feel like I’m getting too low level for what should be a pretty straight forwards processing, since these classes start to work with some multi-threading mess.
So my question is: is there even support of recurrent neural networks beyond model languages/text? I haven’t seen anything so far, not a single recurrent network for tabular data (features-rich time series), images (such as video), or anything beyond NLP, which uses the class “LanguageModelPreLoader”, which doesn’t seem to be applicable to anything beyond text. I feel like there is no actual support for RNNs, but I may be missing something. Has anyone implemented any non-NLP RNN with the corresponding data-loading classes?
I think that the most likely problem is that the data shouldn’t be fed in the way I imagined. Maybe I should consider each sequence an entire data point retrieved by the dataset, with an additional dimension in both the features and the label corresponding to the sequence. Then the network and the loss/metrics functions would just deal with the dimensions of the data in any convenient way.