Glossary of Deep Learning Terms for fast.ai
Terms are organized alphabetically
For abbreviations see the fastai Abbreviation Guide
This is a work in progress and I hope people contribute. My vision is that this is a place for short descriptions of each term: about 3 lines or sentences. If people want to add links to blogs and papers that would be cool too. Maybe we can add some sort of voting tally to put the best blogs at the top of any lists. Cheers!
A
Accuracy
Activation
This is a number which gets calculated. It’s a result of either an affine function(matrix multiplication more generally) or an activation function(nonlinearities like ReLU). They don’t always come out of matrix multiplication, but also from activation functions.
Activation Function
The activation function is any non-linear function applied to the weighted sum of the inputs of a neuron in a neural network. The presence of activation functions makes neural networks capable of approximating virtually any function. Commonly used functions include ReLU (Rectified Linear Unit), tanh, sigmoid and variants of these. These are element-wise functions. They never change the dimensions of the matrix only the contents.
Adam
Adam is an adaptive learning rate algorithm. Updates are directly estimated using a running average of the first and second moment of the gradient and also include a bias correction term.
Affine Functions
These are linear functions. If you are multiplying things up and adding them together that is a linear function. They are not always exactly matrix multiplication. Convolutions are Matrix Multiplications with some of the weights tied, so they are more of affine functions. If you add an affine function on top of another affine function it still is an affine(linear) function. So adding some nonlinearity like Relu in between will make more sense and give you a really deep neural network.
Annealing
Array
Attention
Augmentation
See Data Augmentation
Autodiff/Automatic differentiation
paper: Automatic Differentiation in Machine Learning: a Survey
Autoencoder
B
Backpropagation
Backpropagation is the primary algorithm for performing gradient descent on neural networks. First, the output values of each node are calculated in a forward pass. Then, the partial derivative of the error with respect to each parameter is calculated in a backward pass through the computation graph.
parameters ﹣= parameters.grad * learning rate
Back Propagation Through Time (BPTT)
Batch
Batch Normalization
Bias
Bounding box
C
Categorical variable
categorical variables are mainly strings. You can create date variables also at categories. eg. day of the week, month, day of the month
Categorical Cross-Entropy Loss
Channel(s)
Aka dimensions
For images, the colors: red, green, blue (3) or black and white (2)
For language data: different types of embeddings
Class
Classification
Classifier
Computer vision
Convolution
Convolutional Neural Network (CNN)
Cosine
Computer vision
Continuous variable
Includes continuous numbers eg, age, price, quantities
Cross entropy
- cross entropy loss
Cross validation
Cycle length
D
Data Augmentation
Dataframe
Data organized in a table or a .csv file. Dataframe is a term from Pandas
Dataloader
Dataset
The data that you feed the algorithm.
Dependent
For example, a dependent variable tensor is
Dropout
Embedding
A mapping of a word or a sentence into a vector
E.g. word2vec
E
Epoch
Exploding Gradient Problem
When the standard deviation becomes equal to infinity.
F
Filters
Used in CNNs
Fine-tuning
Forward Propagation
Freezing/Unfreezing
Fully connected
See “Layers”
G
Gradient Clipping
A technique to prevent exploding gradients in deep neural networks, commonly used with RNNs.
Gradient descent
H
Hidden
Hook
I
Independent
For example, an independent variable tensor is
Initialize
Input
x
Iterate, Iterator
To go through objects (add types of objects?) one at a time.
L
Label
A tag applied to an object.
For example, the name of an image.
Language model
Layers
There are only and exactly 2 types of layers either containing parameters or activations.
-
Input - Special activation layer at the start of the neural network. It doesn’t get calculated. It’s just there.
-
Output - Activation layer at the end of the neural network. It contains a set of calculations from the previous layer’s activation function (either sigmoid or softmax)
-
Hidden - in between layers can be convolutions/matrix multiplications(linear) or ReLUs(nonlinear)
-
Dense
-
Sparse
-
Fully Connected
Learning rate
Linear
Loss
Loss Function
LSTM
Long Short-Term Memory networks use a memory gating mechanism that helps prevent the vanishing gradient problem.
paper:
M
Mean Absolute Error (MAE)
Mean Squared Error (MSE)
Mixup
MNIST
A data set of 60,000 training and 10,000 test examples of handwritten digits. Each image is 28×28 pixels large.
Momentum
Multiplier
N
Natural Language Processing (NLP)
Named Entity Recognition (NER)
Named-entity recognition (NER) (also known as entity identification, entity chunking and entity extraction) is a subtask of information extraction that seeks to locate and classify named entity mentions in unstructured text into pre-defined categories such as the person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc
Negative Log Likelihood
Normalization
O
Optimizer
For example Adam
- layer group learning rate optimizer
P
Parameters -
Parameters include weights and biases. These numbers get initialized randomly first, but better to initialize them with kaiming initialization (init.kaiming_normal() from torch.nn). Then our model learns them. We update parameters through gradient descent algorithm.
These parameters are used to multiply with input activations resulting in a matrix product.
parameters ﹣= parameters.grad * learning rate
weights = weights - weights.grad() * learning rate
Padding
Pooling
- Max-pooling
- Average-pooling
Prediction
R
Recurrent Neuron
Recurrent Neural Network (RNN)
Regression
Regularization
ReLU, Rectified Linear Units
Often used as activation/non-linear function.
f(x) = max(0, x)
Residual
ResNet
paper: Deep Residual Learning for Image Recognition
ROC
What are they? https://acutecaretesting.org/en/articles/roc-curves-what-are-they-and-how-are-they-used
Root Mean Squared Error (RMSE)
S
Schedule
Semi-supervised learning
See supervised learning
Seq2Seq
Sigmoid
Mostly used in the last layer for calculating outputs.
It predicts values between 0 to 1. Any number of values can be high near1 at a time. No need to add up to 1. So it’s used in multi-label classification, like planet dataset from Kaggle where a single image can have agriculture, road, and water at the same time.
Softmax
Only used in the last layer for calculating output probabilities. It predicts values between 0 and 1 and these values have to add up to 1. Softmax likes to predict a single label.
We use it in a multi-class classification where you have to choose between mutually exclusive classes like MNIST, CIFAR or dog breeds competition on Kaggle.
Jeremy explains it in the excel spreadsheet
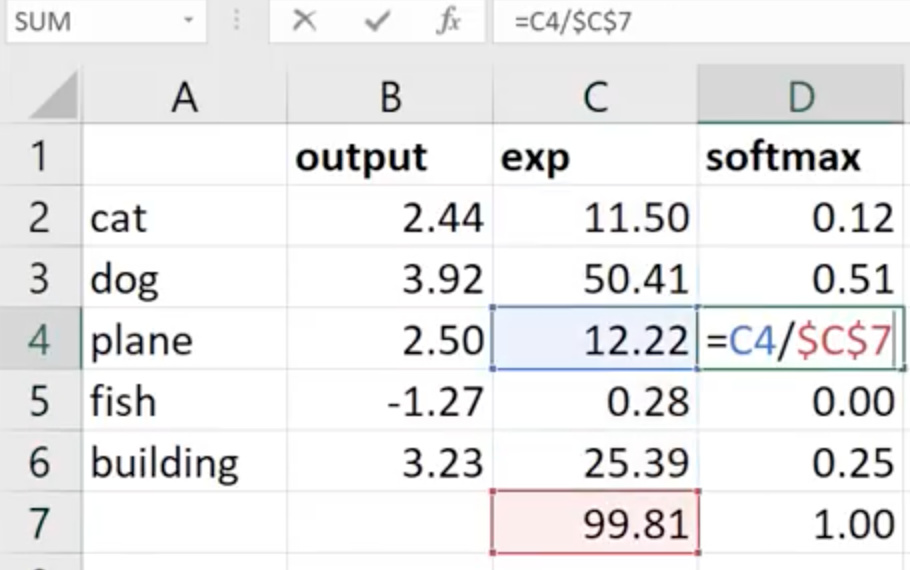
In the multi-class scenario like above, we have to take exponential of each output/prediction value. We then have to add all exponential values(99.81 here). To take softmax of a class, we then divide the exponential value of that class by the sum. Mathematically it is defined as follows,

Stochastic Gradient Descent (SGD)
Stride
Supervised learning
- semi-supervised learning
T
Target
y
Tensor
n-dimensional array designed to work on GPU for accelerated numerical computations.
Test
Test Set
Test Driver Development (TDD)
A software development process that relies on the repetition of a very short development cycle: requirements are turned into very specific test cases, then the software is improved to pass the new tests, only. This is opposed to software development that allows software to be added that is not proven to meet requirements. (An excerpt from the Wikipedia).
Not exactly a deep learning concept. However, it was mentioned several times during Part 2 so worth to mention.
Token
Used in NLP
Train
Training set
Transfer learning
Transform
U
Universal Approximation Theorem -
Matrix multiplications and Relus stacked together 1 after another has this amazing mathematical property called UAT. If we have big enough weight matrices and enough of them, it can solve any arbitrarily complex mathematical function to any arbitrarily high level of accuracy.
V
Validation
- Model Validation
- Cross Validation
Validation set
Vanishing Gradient Problem
Standard deviation going to zero.
W
Weights
Weight decay
Word2vec
paper: Efficient Estimation of Word Representations in Vector Space
paper: Distributed Representations of Words and Phrases and their Compositionality
paper: word2vec Parameter Learning Explained